 夜雨聆风
夜雨聆风你有没有遇到过这样的场景:公司花大价钱部署了一套AI知识库,满心期待员工可以像问同事一样得到精准答案,结果却是——
你问:“去年咱们公司的年假政策是怎样的?”
AI答:“根据人力资源手册,员工享有病假、事假和年假……(戛然而止)”
你问:“具体年假天数?”
AI答:“关于年假,政策中提到根据工龄有所不同……”然后开始胡编天数。
发现问题了吗?不是模型不够聪明,是你喂给它的“食物”根本就没法消化。今天我们就来聊聊,如何从源头把文档整理好,让AI知识库真正变成可靠的同事,而不是满嘴跑火车的话痨。
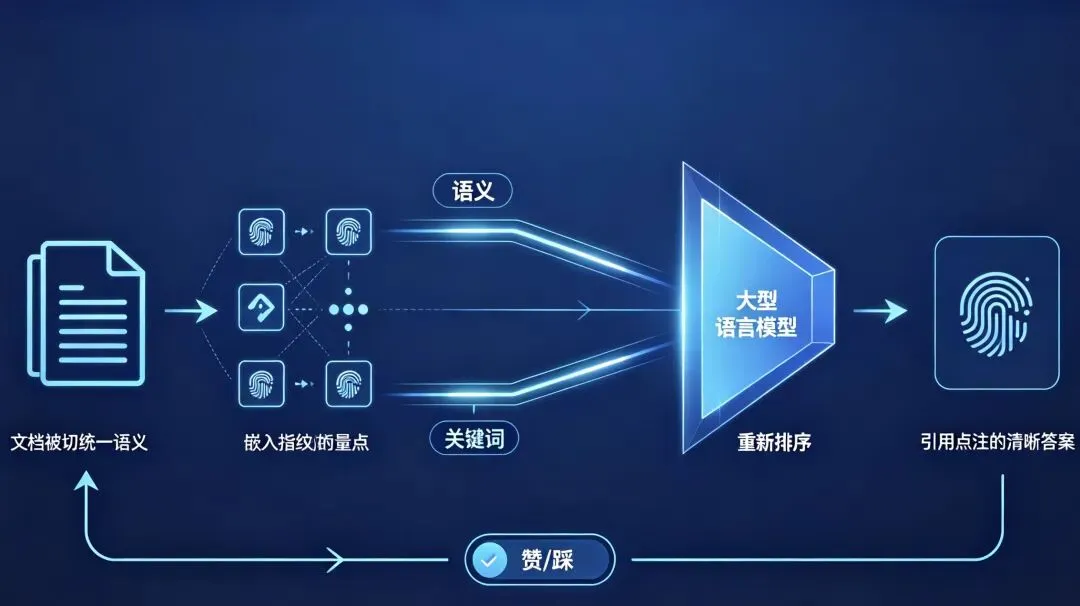
一、AI到底是怎么“读”你的文档的?
先把复杂的流程揉碎了说。AI知识库的核心技术叫做RAG(检索增强生成),拆开来看就三步:
第一步:把文档切成小纸条
就好比你要把一本厚厚的手册分给几个人同时查阅,你得先把书拆成一页一页的。AI会把你的PDF、Word、Markdown先转成纯文字,再按照段落或标题切成一个个小片段,每个片段大概几百个字。这就是“分块”。

第二步:给每个小纸条贴上隐形标签
AI不认识汉字,但它能把每段文字变成一个很长很长的数字串(向量)。这个数字串就像是文字的“语义指纹”——两段意思相近的话,它们的指纹在数学上距离就很近。所有这些指纹被存在一个向量库里。
第三步:问题来了,翻纸条找人帮忙
当你问“年假几天”时,AI先把你的问题也变成指纹,然后在整个向量库里飞快扫描,找到距离最近的几张“小纸条”,把它们连同你的问题一起打包,塞给大语言模型:“喏,这是参考资料,照着回答,不许瞎编。”
听起来很顺?但这里面有一个巨大的坑:如果你丢进去的是一大堆混乱的扫描件、没有章法的合同,那么在第一步“分块”时就彻底完蛋了。 分出来的可能是半句废话、一个孤立的数字,甚至夹杂着乱码。AI拿着这样的纸条,不胡说才怪。
二、文档格式的红黑榜:谁是AI眼中的山珍海味,谁是带壳核桃?
不是所有文档都生而平等。不同的文件格式,最后被AI理解的准确度可以相差好几个档次。我们来从“最好吃”到“最难啃”排个序,你一看就明白。
🥇 第一名:Markdown(.md)—— 顶级刺身,原汁原味
Markdown是纯文本格式,用简单的井号(#)表示标题,用星号表示列表,没有任何多余的花哨。AI消化它就像吃顶级刺身,直接入口,结构分明。一个二级标题就是一个天然的分块标记,切出来的片段完整又干净,不会把上一段和下一段混在一起。
案例:把产品手册写成 功能A.md,里面用 ## 配置步骤、### 注意事项 这样清晰的结构。AI被问到“功能A怎么配”,能精准找到那个二级标题下的全部内容,一字不落。
🥈 第二名:结构化的问答表(.json、.csv)—— 营养胶囊,精准投喂
如果你有大量FAQ,比如“如何重置密码”“退货流程是什么”,千万别把他们写成长篇散文。直接整理成 问题,答案 的表格(导出为CSV或JSON),入库时就能直接绕开分块,每个问答变成一个独立的片段。命中率近乎100%,AI回答得干净利落。
案例:电商客服知识库,用CSV整理200条常见问题。用户问“包裹几天到”,AI直接召回那条精确对,不需要在一堆政策文档里瞎翻。
🥉 第三名:纯文本(.txt)—— 白水煮面,差点味道
纯文本没有格式负担,但缺少标题层级,AI只能机械地按固定字数切分。很可能一个完整的意思被拦腰截断。如果你非要用,务必加入人工分隔符,比如每一段开头写 ### Q: 或者用空行+标题来模拟结构。
第四名:可编辑的Word(.docx)和文字版PDF —— 需要先过一道“翻译”
Word里明明有“标题1”“标题2”,但很多解析工具在提取文字时会把这个层级信息丢掉,或者把表格变成一堆分散的数字。强烈不建议直接导入word或PDF,先通过工具(比如Pandoc)转成Markdown,检查标题和表格没丢再入库。
案例:一份50页的标书是Word格式,直接导入后发现所有“第一章、1.1节”的层级全部消失,整章被切成了十几个碎片,问“付款条件”时AI找了四五个不相关的碎片拼凑,答案完全不可用。转成Markdown后,恢复标题,AI马上就能准确回答。
第五名:网页(.html)—— 带沙子的菜,得仔细淘洗
网页里除了正文,还有导航、广告、相关推荐、评论等大量噪音。如果不先做“正文提取”,AI会把“Copyright 2025 版权所有”也当作知识片段存起来。所以网页必须先用工具摘出干净的文章部分,再转成Markdown。
⚠️第六名 (垫底):扫描版PDF、图片、PPT —— 带壳核桃,费力不讨好
这是最常见的坑。很多企业把自己的历史档案、扫描合同一股脑丢进知识库。AI面对这种文件就像一个近视眼没戴眼镜——它看到的是“一张图”,必须先靠OCR(光学字符识别)把图里的字认出来。但扫描件可能有歪斜、水印、多栏排版,OCR的结果常常是“乱码开会”,分块灾难。
案例:某公司把十年前的纸质合同扫描成PDF直接入库,AI被问“违约金多少”时,因为OCR把“违约金”错误识别成了“走约金”,完全检索不到,最终AI开始自行编造条款。这类文档除非经过高精度OCR加人工校对,否则宁可人工摘要后录成Markdown,也不要直接扔进去。
三、文件夹建得越精细,AI搜得越准?恰恰相反!***
很多人在搭建知识库的时候会本能地干一件事:建立密密麻麻的多级文件夹,像整理电脑D盘一样。
公司资料 > 人力资源 > 规章制度 > 2025年 > 考勤政策.docx
公司资料 > 产品部门 > 功能说明 > V3.0 > 高级配置.pdf

你以为这样就可以让AI在“考勤政策”里找年假,在“高级配置”里找参数?大错特错。
真相是:AI进行语义检索时,根本不看文件夹。所有文件里的所有片段,在向量库里是全部打散混在一个大池子里的。你问一个问题,AI就从这个大池子里捞出语义最相近的几张“小纸条”,它才不管这些纸条原来放在哪个文件夹。
那文件夹完全没用了吗?当然不是,它的价值在于“管理”,不在“检索”。 文件夹是给人看的,方便你后续去更新、巡检。但是要想让AI做到“只在这个范围里搜”,靠的是一种叫元数据过滤的技术。
元数据,你可以理解为贴在每份文档上的标签。 比如给文档打上:
· 部门:人力资源部
· 年份:2025
· 类型:政策
· 标签:年假、考勤
当用户问“去年人力资源部的考勤政策”时,系统先根据标签快速过滤出一小批文档,然后再在这个小范围里做语义搜索。这才能做到又快又准。
所以,不要用文件夹来规划检索路线,养成打标签的习惯。 建一到两层文件夹辅助人类管理足矣,深度千万不可超过三层,否则只会给后面的维护人员带来“这文档到底该放哪儿”的困惑。
四、实战秘籍,让你的知识库智商翻倍
除了格式和标签,还有几个关键技巧,能直接把知识库从“及格”拉到“优秀”。
1. 分块不是切豆腐,要切“思想块”
一个好的分块,应该包含一个完整的意思。比如一个操作步骤的三小步不要切散,一个概念的定义不要把下半句切到另一个块里去。Markdown天然支持按标题分块,这就是为什么我们把它排在第一的原因。如果是普通文本,建议保持块大小在500-1200字之间,并且块与块之间保留一点重叠(比如上一块最后50个字在下一块开头重复出现),防止边界信息丢失。
2. 别忘了给图片“说话”
如果你的文档里有流程图、架构图,AI是看不懂图片本身的。你需要为每张重要图片生成一段文字描述,嵌入在那个位置。比如一张“请假审批流程图”,在旁边加上文字:“员工发起申请→直属上级审批→超过3天需部门负责人审批→HR备案”。这样AI才能“看见”图片内容。
3. 混合搜索:关键字和语义双管齐下
单纯靠语义,有时候会闹笑话。比如用户搜“WX2025-001工单”,语义检索可能理解不了这个工单号,但如果同时有一条关键词检索通道,就能直接精准命中。所以专业的知识库一定会同时跑“语义路”和“关键词路”,把两者的结果合并起来,再通过一个重排序模型挑出最贴切的几条。这就是为什么有些产品搜产品型号特别准的秘诀。
4. 建立“错题本”和自动体检
正式上线前,准备至少100个真实问题当作“考卷”,包含查事实的、问步骤的、做对比的,甚至一些故意捣乱的问题(比如“今天天气怎么样”,应拒答)。每次改了文档后,用这些题目自动跑一遍,看看有没有原本能答对的题现在答错了。这能防止知识库越更新越笨。
上线后,别忘在答案下方放上“赞/踩”按钮和反馈框。当某个回答被踩的次数超标时,自动生成一个整改任务,让文档负责人去修改源文档。这样知识库就活起来了,能自己进化。
五、小白也能用的自检清单和工具包
下次你在准备上传文档之前,请逐条打钩:
· 文件转成Markdown了吗?(不是“保存为.md”,是真的用井号表示标题)
· 里面的表格能正常显示成文字吗?(而不是变成图片)
· 重要的图片都给配上文字说明了吗?
· 每个章节是不是大概几百字到一千多字,没有被硬生生切碎?
· 已经填好部门、日期、关键词等标签了吗?
· 涉及敏感内容的,设好权限标签了吗?
如果你手头只有Word或普通PDF,推荐用Pandoc这类免费工具转成Markdown。如果文档非常复杂,可以用MinerU这类带版式分析的解析器。知识库搭建平台方面,Dify、FastGPT等对新手都很友好,内置了分块和元数据管理功能,不用自己写代码。
结语
搭建一个靠谱的AI知识库,本质上是在给AI准备一套干净、营养、好消化的“知识餐”。这个过程没有太高的技术门槛,却需要足够的耐心和规范。
从今天试试用Markdown写新文档,把旧文档慢慢“翻译”过来,再给你的文件贴上标签,建立反馈循环。过一段时间你就会发现,之前总爱胡言乱语的AI,开始变得严谨、准确,甚至能帮你发现知识体系里隐藏的矛盾。
毕竟,AI擅长放大你的努力——你给它有条理的输入,它就还你值得信赖的输出。
