夜雨聆风
夜雨聆风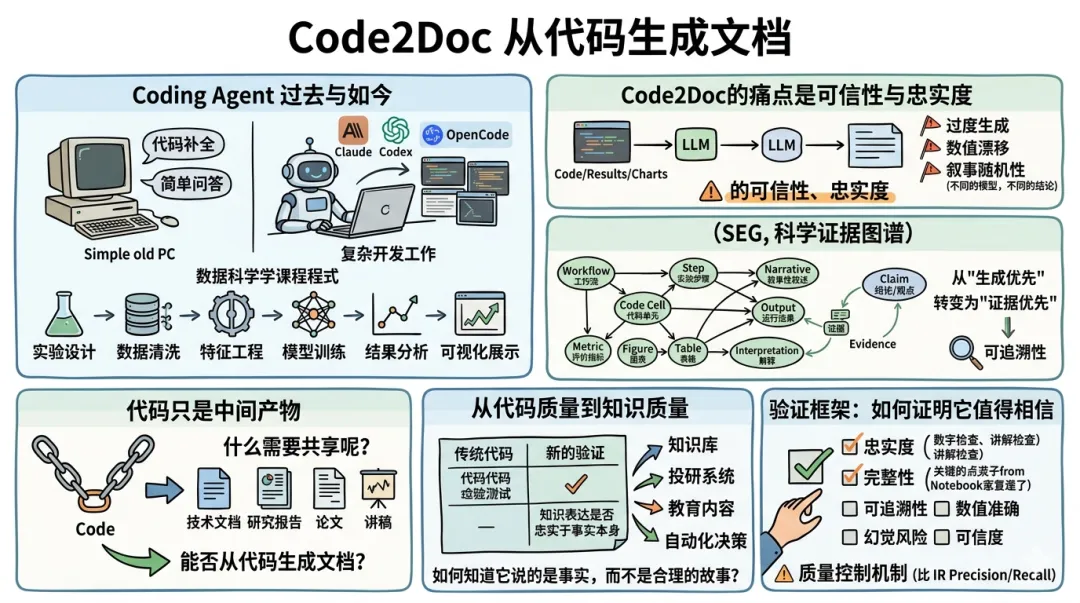
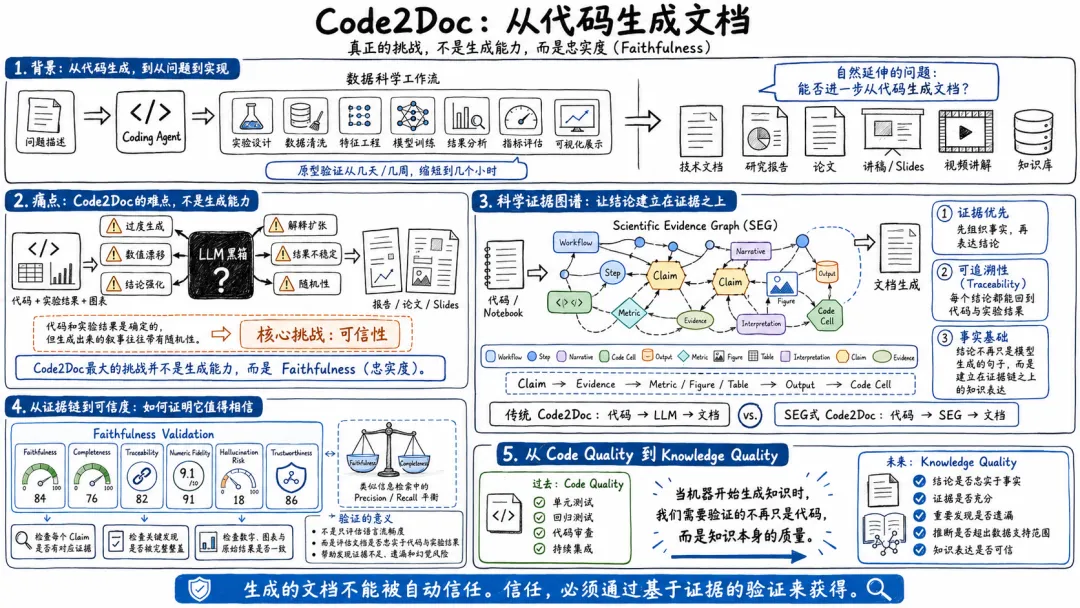
过去一年,Coding Agent的发展速度之快,已经远远超出许多人的预期。以前,我们对AI编程的期待还停留在代码补全和简单问答层面。如今,无论是Claude Code、Codex、OpenCode,还是各种围绕Agent Workflow构建的新能力和工具,已能够参与相当复杂的软件开发工作。
对于数据科学项目而言,这种变化尤为明显。一个典型的数据科学工作流,往往包含实验设计、数据读取与清洗、特征工程、模型训练、结果分析、指标评估以及可视化展示等多个环节,每一步都有明确的输入、输出和评价标准。这种天然的结构化特征,恰好与Coding Agent的能力高度契合,使得许多原本需要几天甚至几周才能完成的原型验证工作,如今往往几个小时就能够搭建完成。越来越多的项目已经不再从代码开始,而是从问题描述开始,然后由Agent自动完成大部分实现和迭代工作。
当Code Generation逐渐成为现实之后,一个新的问题开始浮出水面。对一个项目而言,代码只是中间产物。真正需要被分享、被评审、被长期沉淀下来的,还有技术文档、研究报告、论文、讲稿,甚至包含视频讲解和知识库内容。那么下一个自然的问题便是:能否进一步从代码生成文档?这正是本文想讨论的Code2Doc。
Code2Doc的痛点,并不是生成能力
提到Code2Doc,一个很自然的想法是:既然大语言模型已经能够理解代码,那么把代码、实验结果以及图表交给模型,再要求它生成技术文档或者研究报告,似乎是一件顺理成章的事情。过去几个月里,这其实也是我最常采用的工作方式之一。特别是在数据科学项目中,我习惯使用Jupyter Notebook来组织整个工作流,每一个关键步骤前面通常会先用Markdown说明当前任务,代码运行之后,再生成Markdown对结果进行解释和总结。表面上看,这样的Notebook已经接近一篇技术报告或者研究论文,只需要一句“请帮我整理成报告”或者“请帮我写成论文”,利用最新最强的大模型,很快就能给出一份看起来相当不错的结果。
问题很快就出现了。最常见的问题是过度生成(Over-generation)。模型往往会主动补充大量背景知识和扩展讨论,把原本几个实验步骤和几张图表扩展成十几页甚至几十页的分析报告。从阅读体验上看,这些内容未必不好,但其中相当一部分已经超出了代码和实验本身所表达的信息。
与此同时,数值漂移、结论强化以及解释扩张等现象也时有发生。对于数据科学项目而言,结论最终建立在具体指标、图表和实验结果之上,但在长篇文档生成过程中,这些信息往往会被重新组织和重新解释。同样一份代码,交给不同模型生成报告,甚至同一个模型重新运行一次,最终强调的重点和提炼出的结论也不尽相同。代码和实验结果本身是确定的,而围绕这些结果生成出来的叙事却带有明显随机性。
这些问题本质上都指向同一个核心挑战:可信性。今天的大模型已经能够生成足够长、足够流畅、足够专业的文档,真正困难的反而是如何保证这些文档始终忠实于代码、实验过程以及实验结果本身。换句话说,Code2Doc最大的挑战并不是生成能力,而是Faithfulness(忠实度)。
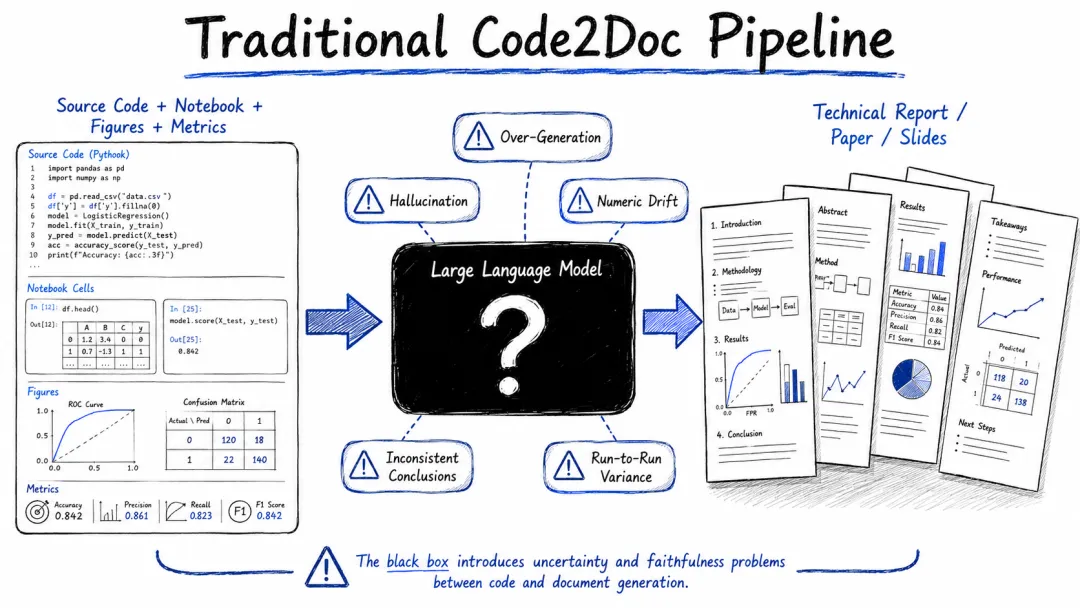
代码描述的是实现逻辑和执行过程,文档表达的是知识、结论和观点,而从代码直接跳到文档,本质上相当于要求模型同时完成事实抽取、证据关联、结论归纳和叙事表达等多个任务。所有这些工作都被压缩到一次生成过程中完成,最终生成结果自然会高度依赖模型自身的推理路径和表达偏好。模型也许能够写出一篇不错的文章,但很难保证其中每一个结论都忠实于代码和实验结果本身。
因此,代码和文档之间缺少了一层中间结构。这层结构不负责讲故事,也不负责生成文字,而是负责组织事实、记录证据并建立结论与证据之间的关联关系。如果没有这样一层结构,Code2Doc最终仍然只能停留在“让模型帮忙写文档”的阶段,而难以真正解决Faithfulness的问题。
围绕这个问题,我最近专门做了一轮实验,并构建了一套新的中间层:Scientific Evidence Graph (SEG,科学证据图谱)。
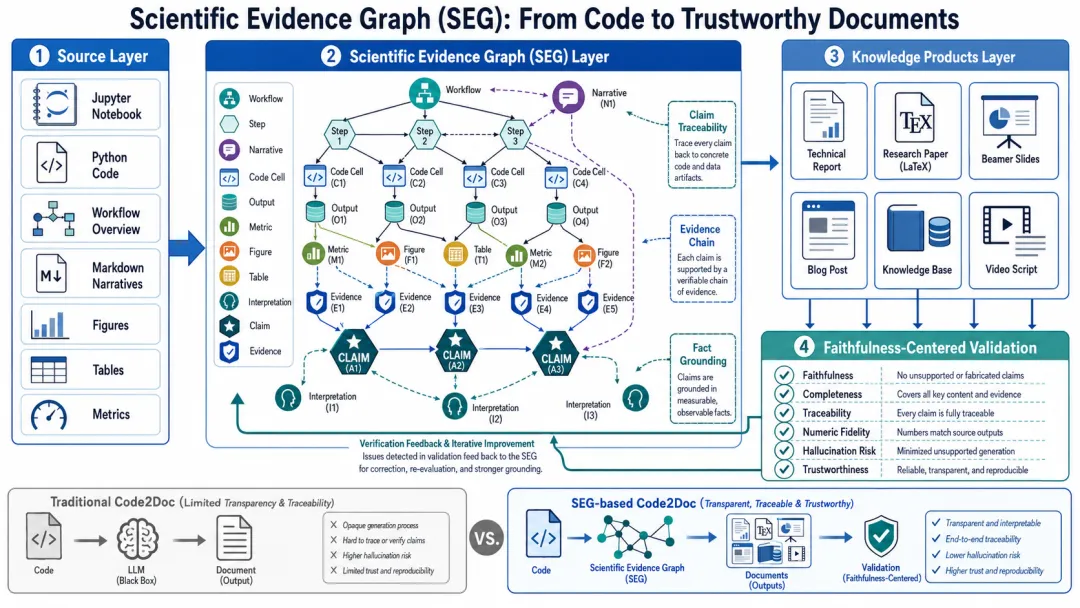
SEG图中包含Workflow, Step, Narrative, Code Cell, Output, Metric, Figure, Table, Interpretation等节点,它们是支撑Claim的证据体系。每一个Claim都必须关联到对应的Evidence,而每一个Evidence又必须能够进一步追溯到具体的Metric、Figure、Table、Output以及Code Cell。这样一来,文档中的结论不再只是模型生成出来的一段文字,而是建立在明确证据链之上的知识表达。
这种设计带来了一个非常重要的变化。在传统Code2Doc流程中,模型首先看到的是代码,然后自行决定哪些内容重要、哪些结论值得强调。而在SEG中,系统首先建立的是事实与证据之间的关系,然后再由这些证据支撑最终结论。整个过程从“生成优先”转变为“证据优先”,从“先写再验证”转变为“先组织事实再表达”。
更重要的是,当Claim成为图谱中心之后,自然带来可追溯性(Traceability)。对于文档中的任何一个结论,都可以沿着图谱不断向下追溯:它引用了哪些证据,证据来自哪些指标和图表,图表来自哪些实验结果,而实验结果又来自哪些代码执行过程。对于技术文档而言,这种能力意味着每一个结论都拥有明确来源;对于研究论文而言,这意味着每一个论断都能够找到对应依据;而对于未来的Agent系统而言,这意味着生成的文档拥有了可验证的事实基础。
从证据链到可信度:如何证明它值得相信
当科学证据图谱(SEG)逐渐成型之后,一个新的问题很快又出现了。SEG解决的是“结论从哪里来”的问题,但对于一个真正可用的Code2Doc系统而言,仅仅拥有证据链仍然不够。证据链回答的是结论的来源,而可信度回答的则是结论是否值得相信。换句话说,从Evidence到Trust,并不是一个自动成立的过程,中间仍然需要一套系统化的验证机制。
事实上,这也是整个实验过程中思考时间最长的一部分。因为从工程角度来看,生成一份报告并不困难;生成一份带有完整证据链的报告也并不困难。真正困难的是如何评价最终生成出来的文档与原始代码、实验过程以及实验结果之间究竟有多接近。对于研究报告、论文或者技术讲义而言,仅仅能够追溯来源并不足够,人们更关心的是:这份文档是否忠实地反映了事实本身。
围绕这个问题,我进一步构建了一套以Faithfulness为核心的验证框架,并将其作为整个Code2Doc流程的最后一环。
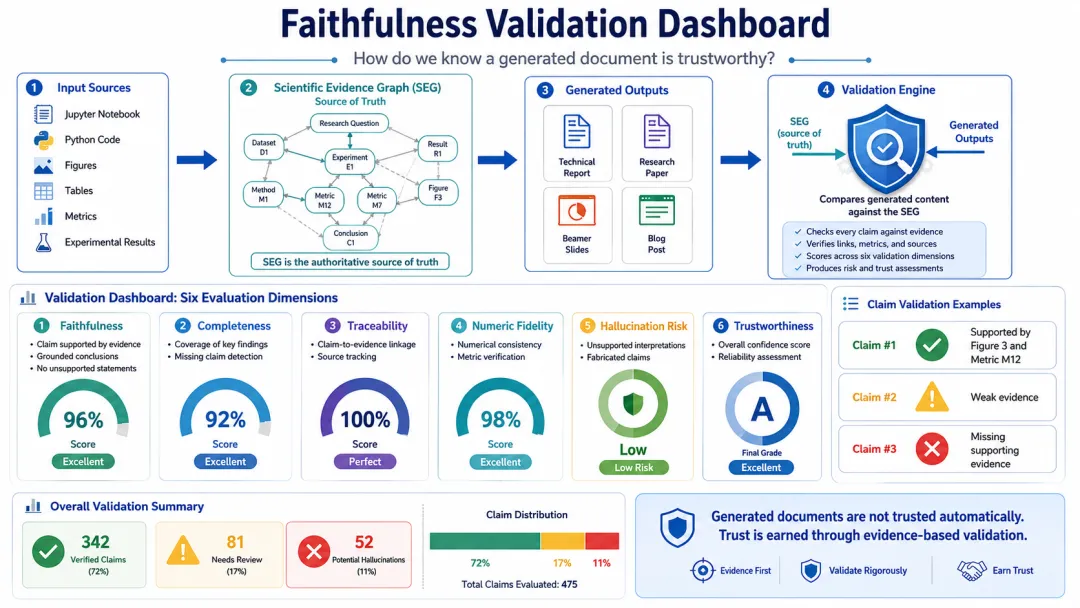
与传统文档评测不同,这套框架并不把语言质量放在最核心的位置。对于今天的大模型而言,生成一篇结构完整、语言流畅的文章已经不是特别困难的事情。真正需要评估的,是文档是否忠实于代码和实验结果,是否完整覆盖了关键发现,以及是否出现无法追溯来源的推测和幻觉内容。
围绕这个目标,整个验证体系被组织成几个核心维度。首先是忠实度(Faithfulness)。系统会检查每一个Claim是否能够找到对应证据,所有数字是否能够追溯到原始实验结果,以及文档中的解释是否超出了证据本身所支持的范围。其次是完整性(Completeness)。一个系统即使完全忠实,也可能遗漏重要发现,因此还需要评估Jupyter Notebook中的重要结果是否都被正确提取和表达出来。
除此之外,Traceability、Numeric Fidelity、Hallucination Risk和Trustworthiness也成为验证体系的重要组成部分。对于每一个结论,系统都会生成对应的证据链分析;对于整份文档,则会形成一份综合评估报告,帮助作者快速发现哪些结论证据充分,哪些部分仍然存在风险。
值得一提的是,在构建这套框架的过程中,我越来越觉得Faithfulness和Completeness与信息检索里的Precision和Recall存在某种天然对应关系。如果一个系统只输出极少量结论,它很容易做到高度忠实,但与此同时也可能遗漏大量有价值的信息;反过来,如果一个系统试图覆盖所有内容,又很容易引入过度解释和推测。因此,一个优秀的Code2Doc系统并不是生成最多内容的系统,而是在Faithfulness和Completeness之间找到平衡点的系统。
从这个角度看,Faithfulness Validation的意义已经不仅仅是验证文档质量。它更像是一种针对知识生成过程的质量控制机制。过去的软件工程通过单元测试、集成测试和回归测试验证代码,而在Code2Doc场景下,我们同样需要一套机制来验证知识表达是否忠实于事实本身。
从Code Quality到Knowledge Quality
回头看这轮实验,最初希望能够从一个完成的数据科学项目代码自动生成技术文档、研究报告和演讲Slides。然而随着系统逐渐成型,我才发觉,真正值得关注的已经不再是文档生成本身。
过去几十年,软件工程围绕Code Quality建立起了一整套成熟体系。代码是否正确、是否稳定、是否可维护、是否能够通过测试,几乎已经形成行业共识。对于一段代码,我们知道如何进行单元测试、如何进行回归测试、如何进行代码审查,也知道如何利用持续集成和自动化工具去保证最终质量。换句话说,围绕代码质量,我们已经积累了几十年的工程经验。
但今天,随着Agent开始越来越深入地参与知识工作,当Agent自动生成代码、并自动撰写研究报告、总结实验结果、组织知识结构甚至辅助决策时,我们需要验证的对象已经不再只是代码本身。即使代码完全正确,也不意味着最终生成的结论一定正确;即使实验结果完全准确,也不意味着最终生成的报告一定准确。从代码到知识表达的过程中,开始出现大量新的质量问题:结论是否忠实于事实、证据是否充分、重要发现是否遗漏、推断是否超出了数据本身能够支持的范围。
如此看来,Code2Doc真正暴露出来的,其实并不是文档生成问题,而是知识质量问题。科学证据图谱和忠实度验证的的价值并不仅仅局限于Code2Doc。今天它们服务于技术报告和研究论文,明天也许会出现在Agent生成的分析报告、企业知识库、投研系统、教育内容甚至各种自动化决策流程之中。无论具体应用场景如何变化,背后的核心问题其实始终相同:当机器开始生成知识时,我们如何知道它说的是事实,而不是一个听起来合理的故事。
免责声明:以上文案由AI协助生成 🤖✨