 夜雨聆风
夜雨聆风在AI编程助手的演进历程中,有一个方向正在悄然改变人机协作的底层逻辑——不是让模型变得更快、更聪明,而是让它能够主动管理自己的任务节奏与对话结构。这就是Codex最新引入的「自主管理对话线程与并行任务」能力。它意味着,当开发者给出一个模糊的目标,Codex不再是一条一条顺序执行指令的工具,而是能够理解整体意图后,自行拆解任务、调度子进程、管理多个并行线索,最终把完整结果交付给用户。
这种能力的落地,标志着AI编程助手从「被动响应」向「主动规划」的一次关键跃迁。
从单轮对话到多线程协同
传统AI编程助手的工作模式,可以用「问答接龙」来概括:用户提一个问题,AI给一段回答,用户再追问,AI再回应。这种模式在简单任务上效率尚可,但面对复杂项目开发时,问题随之暴露——上下文窗口有限,历史信息被稀释,多个关联需求散落在不同对话轮次中,AI难以建立全局视野。
Codex的多线程管理机制,本质上是给AI一个「任务中枢」。当用户提出一个涉及多个模块的需求,比如「帮我重构这个项目的认证模块,并同步更新API文档和测试用例」,Codex会先对任务进行意图分析,然后将这个整体需求拆解为三个并行子线程:认证逻辑重构、API文档更新、测试用例编写。每个子线程有独立的上下文区间,可以独立调用工具、读写文件、搜索代码。线程之间通过共享的内存层保持信息同步,确保重构后的字段名能够准确反映到文档和测试中。
这种设计解决了长期困扰AI编程助手的一个核心矛盾:上下文容量有限,但复杂任务需要的信息量无限。通过线程化拆分,Codex在每个子线程内都维持了一个精简但完整的上下文视图,避免了信息在长对话中的层层衰减。
并行任务的调度逻辑
并行执行并不是简单地把多个任务同时扔给AI处理。真正的挑战在于:任务之间往往存在依赖关系,有的是数据依赖,有的是逻辑先后。手动标注这些依赖对用户来说过于繁琐,也不符合「让AI自主管理」的初衷。
Codex的调度系统引入了「依赖自动推导」机制。在任务拆解阶段,系统会分析各个子线程之间的数据流关系——如果某个线程的输出是另一个线程的输入,调度器会自动建立父子依赖链,确保前置任务完成后置任务才启动。例如在上面的重构案例中,认证逻辑重构完成之前,测试用例线程会处于等待状态;一旦认证模块代码落地,测试线程立即激活,开始针对新逻辑编写用例。
对于真正独立的子任务,调度器则会让它们并行推进。文档更新和代码重构在多数情况下可以同步进行,因为两者的输入来源都是同一个项目结构,输出也各自独立。调度器会最大化地利用这种独立性,在保证正确性的前提下压缩整体执行时间。
这种调度逻辑还带来了一个额外收益:任务级别的断点续传。当某个并行线程在执行过程中遇到阻塞——比如网络超时或文件权限问题——系统可以单独重试这个线程,而不需要重启整个任务链路。用户不必因为一个子任务的失败而从头再来,这种韧性在长时间运行的复杂任务中尤为重要。
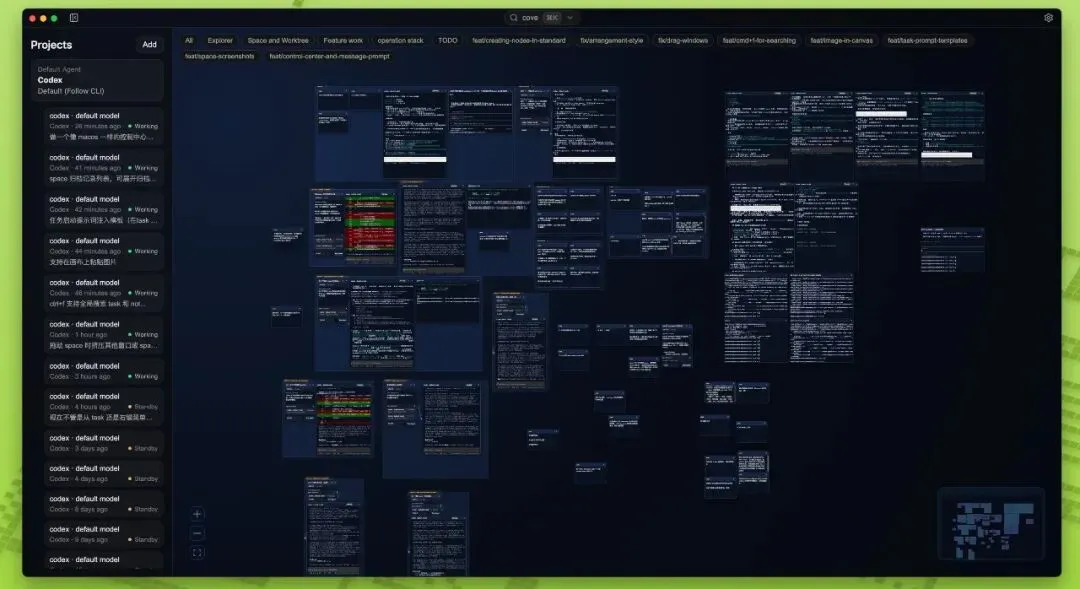
对话线程的上下文隔离与复用
多线程架构还有一个容易被忽视的优势:上下文的隔离与按需复用。在传统单线程对话中,所有历史信息都堆在一个上下文窗口里,AI在处理新需求时往往会被早已无关的历史对话「稀释」,导致响应质量下降。
Codex的线程模型允许每个对话线程拥有自己独立的上下文区间。一个线程可以专门用于处理Bug修复,另一个线程负责新功能开发,第三个线程用来解答代码审查问题。线程之间可以按需共享信息,但不会相互干扰。用户可以在一个会话中同时推进多个方向,AI不会因为话题切换而丢失对当前任务的专注。
更精细的设计在于上下文的复用机制。当某个线程需要调用另一个线程的计算结果或分析结论时,系统可以通过轻量级的引用机制将目标线程的关键上下文注入当前线程,而不必复制整段历史。这种设计既保证了信息的传递效率,又避免了上下文窗口的浪费。
实际场景中的体验跃迁
让我们通过一个具体场景来感受这种能力的实际价值。假设一名全栈开发者正在使用Next.js开发一个电商后端,数据库用PostgreSQL,缓存层用Redis。用户对Codex说:「帮我把商品查询接口从直接查库改成先查Redis缓存,缓存未命中再查库,同时加上分页和搜索条件。」
在传统模式下,AI可能会分几步来做这件事:首先写一段缓存读取逻辑,再写缓存未命中的回源逻辑,然后加上分页参数处理,最后处理搜索条件。每一步都要依赖用户的反馈来修正方向,整个流程可能要十几次来回。
在Codex的多线程模式下,这个需求会被自动拆解为并行线程:缓存读写逻辑线程、分页参数解析线程、搜索条件过滤线程。三个线程同时开工,各自生成代码片段。调度器在合并阶段会发现分页和搜索条件的代码片段需要以缓存结果为输入,自动调整合并顺序,最终拼装出一段逻辑完整、结构清晰的函数代码。用户只需要做一次确认,整个重构就完成了。
这个例子背后展示的,不仅是效率的提升,更是AI编程助手角色定位的转变——它开始像一个真正的协作搭档,而不仅仅是工具。
开发者工作流的重塑
随着这类多线程自主管理能力的成熟,开发者的工作流也在被重塑。过去,开发者需要花大量时间将任务拆解成AI可以处理的最小单元,然后一条一条喂给AI,并持续纠正方向。这本质上是一种「流水线工头」的工作模式——人负责规划,AI负责执行。
Codex的自主管理能力让这种分工发生了逆转。现在,用户只需要描述最终想要达成的状态,Codex会自动完成中间所有的规划、拆解、调度与校验工作。人的角色从「指令编排者」转变为「结果审核者」,专注于定义目标和验收标准,而不是管理执行细节。
这种转变对团队协作的影响同样深远。一个三人小团队可以共享同一个Codex会话,各自提出自己的需求,由Codex在后台进行需求冲突检测和资源调度。Codex可以在合并前检测到两个需求可能产生的接口冲突,主动提示开发者决策,而不是等到代码合并后才发现问题。

技术底座的支撑
支撑这套多线程并行系统运转的,是一套轻量级的任务协调协议。每个子线程在启动时都会向任务中枢注册自己的输入输出契约,调度器基于这些契约构建有向无环图(DAG),从而实现精确的依赖计算和最优的执行排序。这套协议独立于具体的模型实现,意味着无论底层模型如何升级,上层的任务调度逻辑都可以保持稳定。
内存管理层则采用了分层设计。线程私有内存存储当前任务的中间变量,共享内存层存放跨线程共用的数据结构和常量。私有内存的隔离保证了线程间的故障隔离,共享内存的分层则实现了安全的信息流通。
此外,整套系统还内置了完整的执行日志和回溯机制。每个线程的输入、输出、执行时长和异常信息都被记录下来。当用户对某个结果不满意时,可以直接定位到产生该结果的线程,查看其完整执行轨迹,然后给出精确的修正指令,而不必重新描述整个需求背景。
面向未来的协作范式
Codex迈出的这一步,实际上指向了一个更大的方向:当AI具备了对自身任务结构的管理能力,它就不再只是被人类驱动的执行器,而开始具备某种意义上的「主动性」。这种主动性并不意味着AI有了自我意识,而是说它能够在给定的目标框架内,自行做出大量此前需要人类介入才能做出的决策。
这对AI编程助手的进化路径有深远的意义。下一步,我们可能会看到Codex进一步整合代码库的全量上下文,建立项目级别的知识图谱;也可能会看到它主动发现代码中的潜在风险,提前向开发者预警。这些能力叠加在多线程自主管理的基础之上,将让AI编程助手从「辅助工具」逐步演化为真正的「协作智能体」。
对于今天的开发者而言,理解并尽早适应这种新的协作范式,已经成为一项值得投入的技能。学会给AI描述目标而不是步骤,学会在更高的抽象层级上进行审核而不是指挥,这将决定一个人在使用AI编程助手时的效率天花板。
那么,你是否已经在使用支持多线程任务管理的AI编程助手?如果还没有,你认为哪种场景最让你期待这种能力?
