 夜雨聆风
夜雨聆风
上个月,我给客户做了一条AI短片,有一个画面是两个人相遇的场景,提示词里明明写的很清楚:“两人间隔三米,远远对望”。
结果,出来的画面,还是俩人面对面贴着站。
就这一个画面,提示词改了十几遍,还是没有跳出我想要的画面。
 是 AI 压根就没有空间感,它不知道"3米"是多远,也不知道"左边"是哪个左边,不知道镜头该从哪个角度看这两个人。
是 AI 压根就没有空间感,它不知道"3米"是多远,也不知道"左边"是哪个左边,不知道镜头该从哪个角度看这两个人。这类问题好像从一开始就是死局:空间关系、人物站位、镜头角度,三维的信息,使用提示词好像根本就没有办法给AI传达出准确的意思。
直到我最近用上了 LibTV 新出的这个导演台功能,可以说这个功能把我生成视频的逻辑都给改变了。
先贴个地址:
liblib.tv

这么做的好处,相当于提前给AI画了张草图,
以前生成图片出来是盲盒,出来什么全靠缘分。
不对就改提示词,改完再跑,跑完再改,一个镜头耗半小时都是常事。
站位、角度、景别,全都在图里,那生成的无论是视频还是图片可控性都变高了。
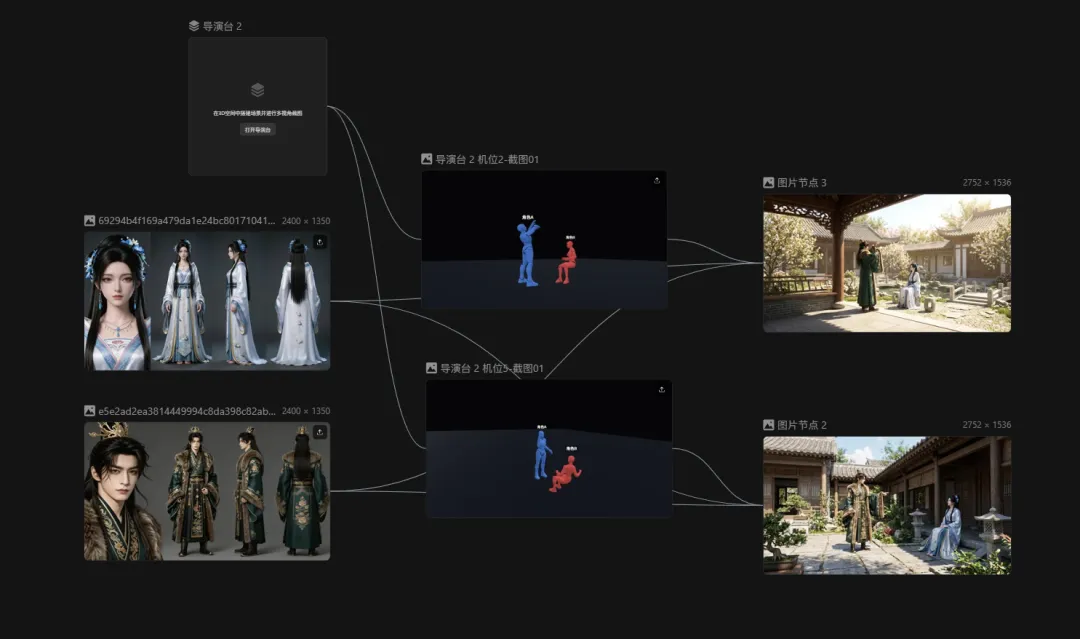
导演台打开之后,里面是一个简易的 3D 画布。
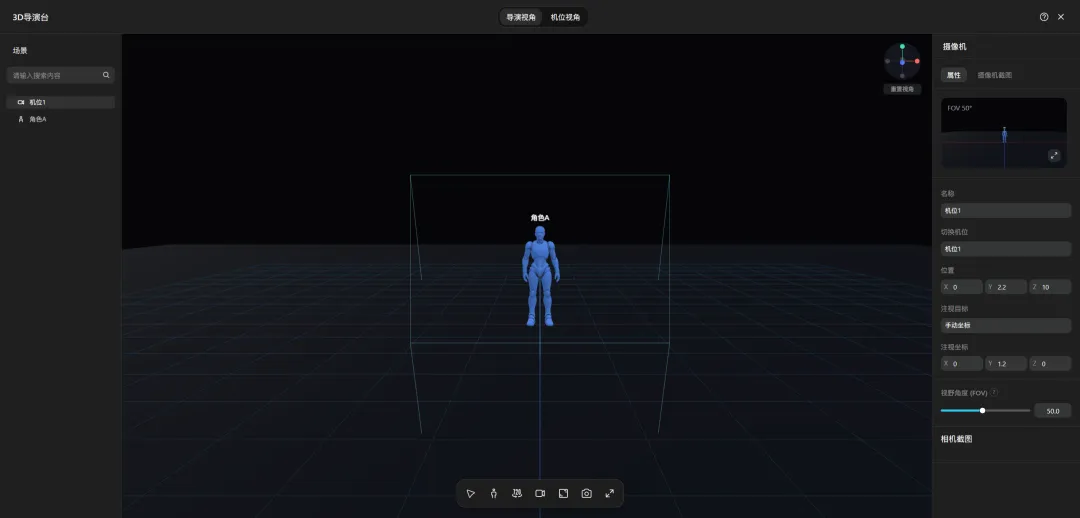
平台内置了一批人物模型,直接拖进来摆就行。单人居中、左右站位、多人并排,位置、姿势,随便调,拖到哪算哪。
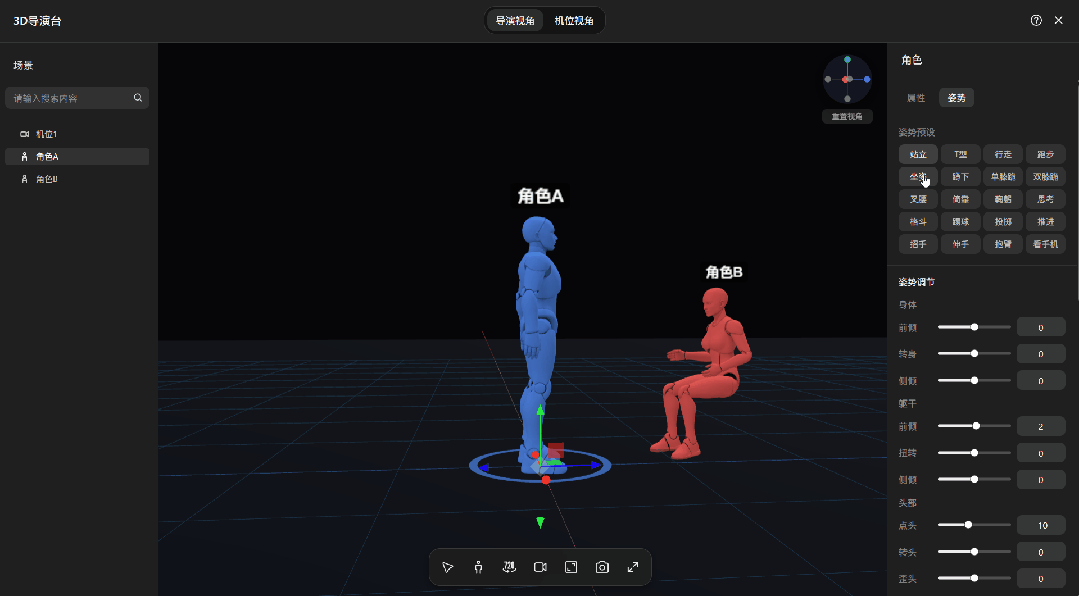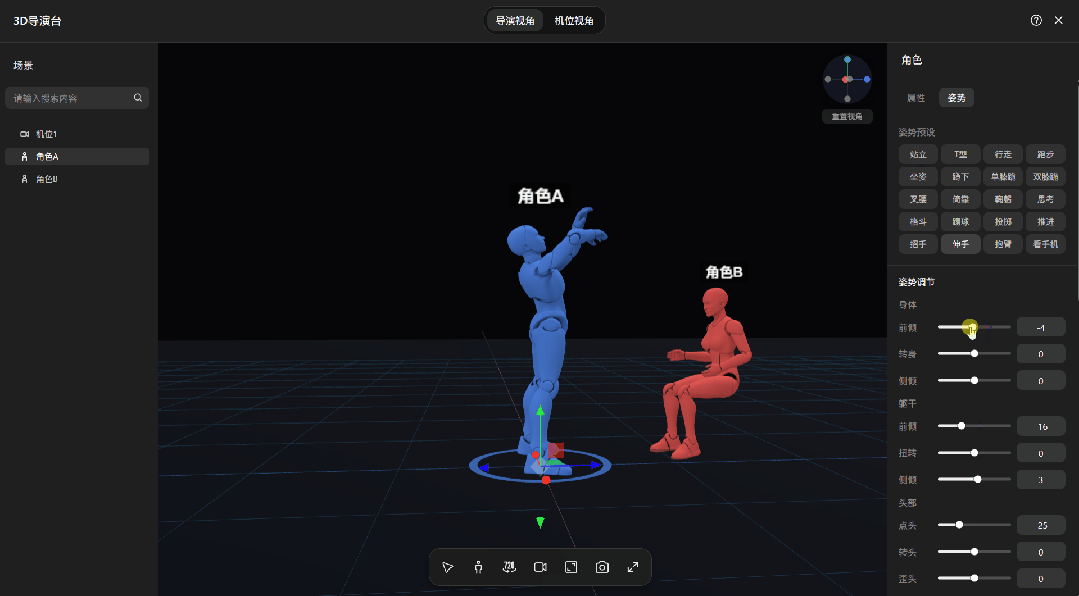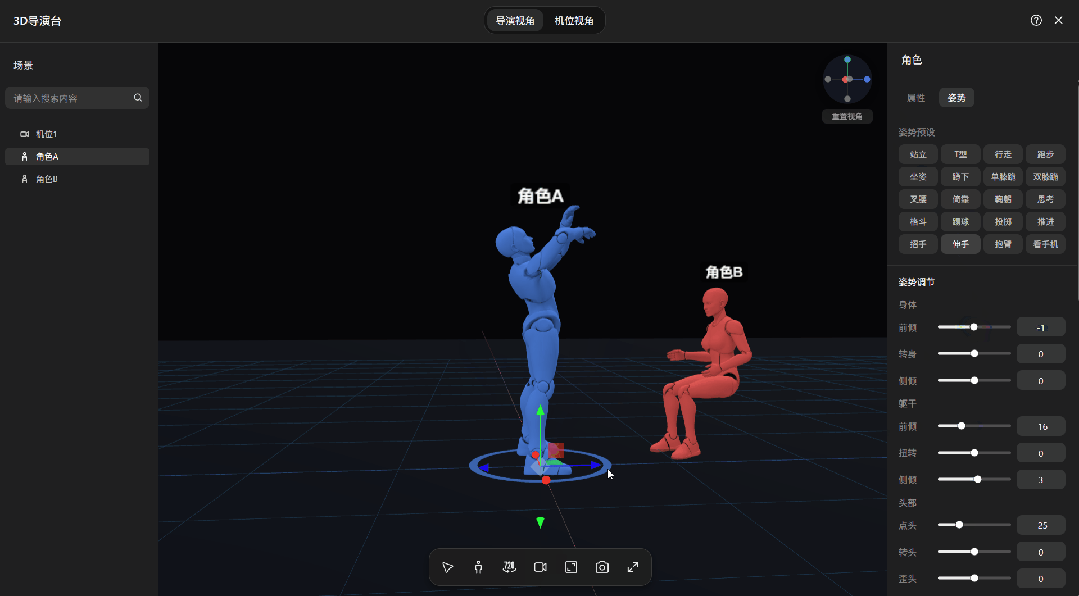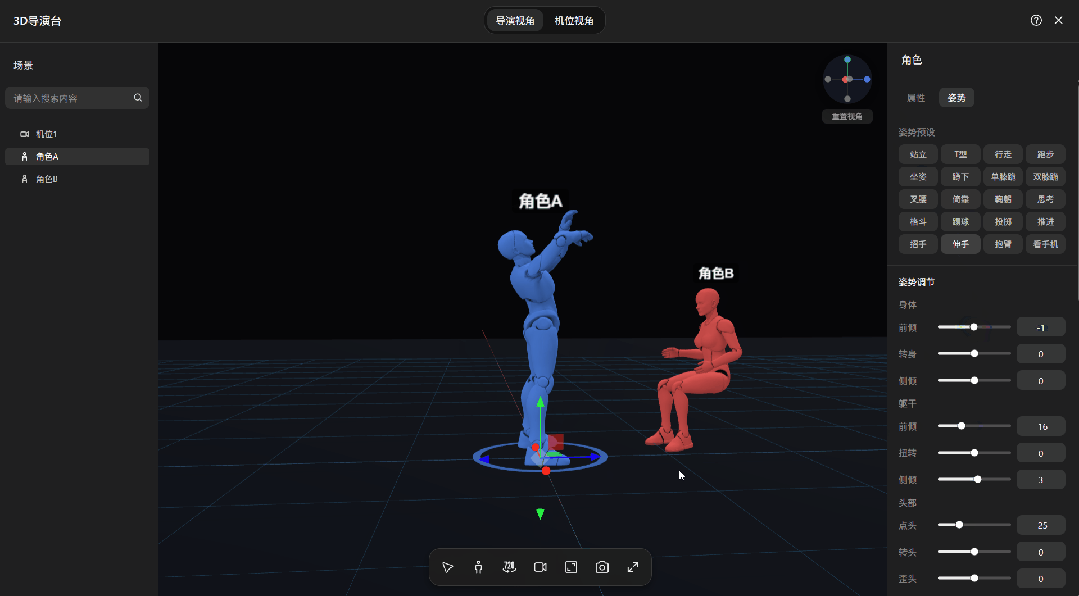
镜头也是手动控制的。摄像机位置、角度自己拧,俯拍、仰拍、近景、特写,调到满意为止。
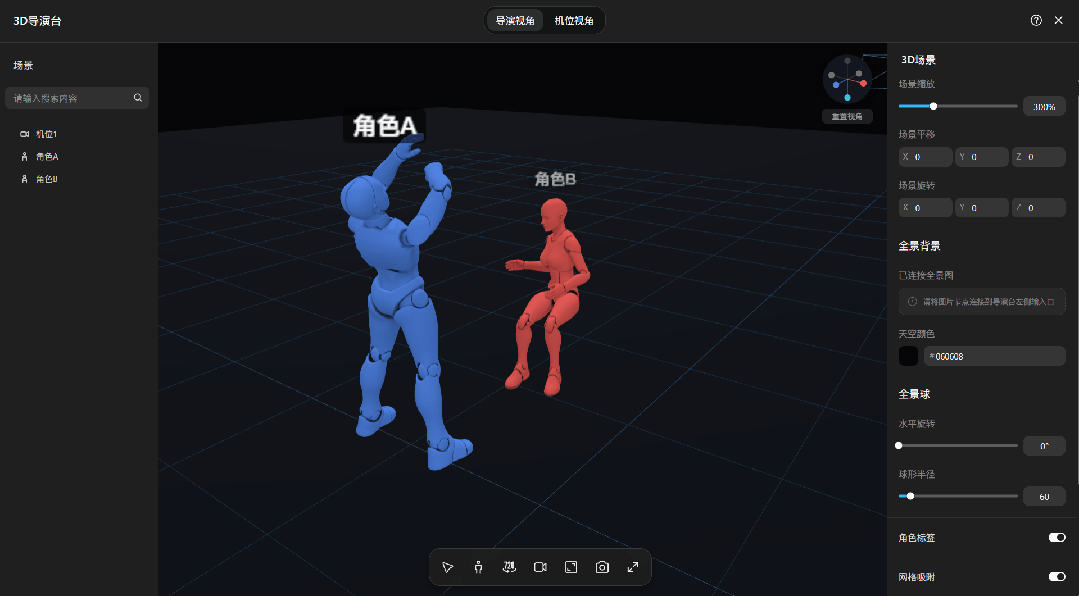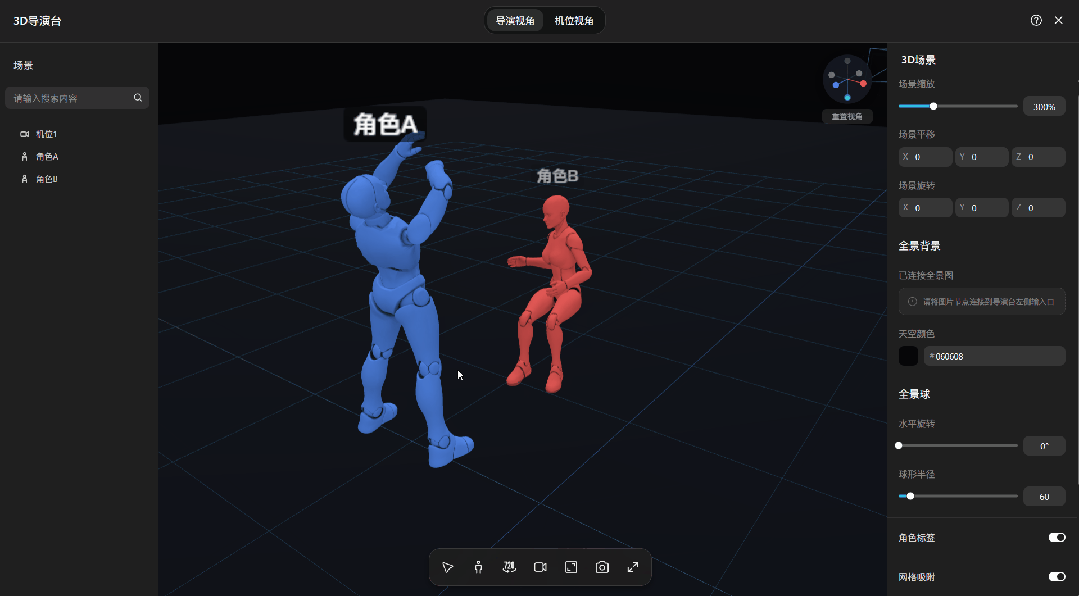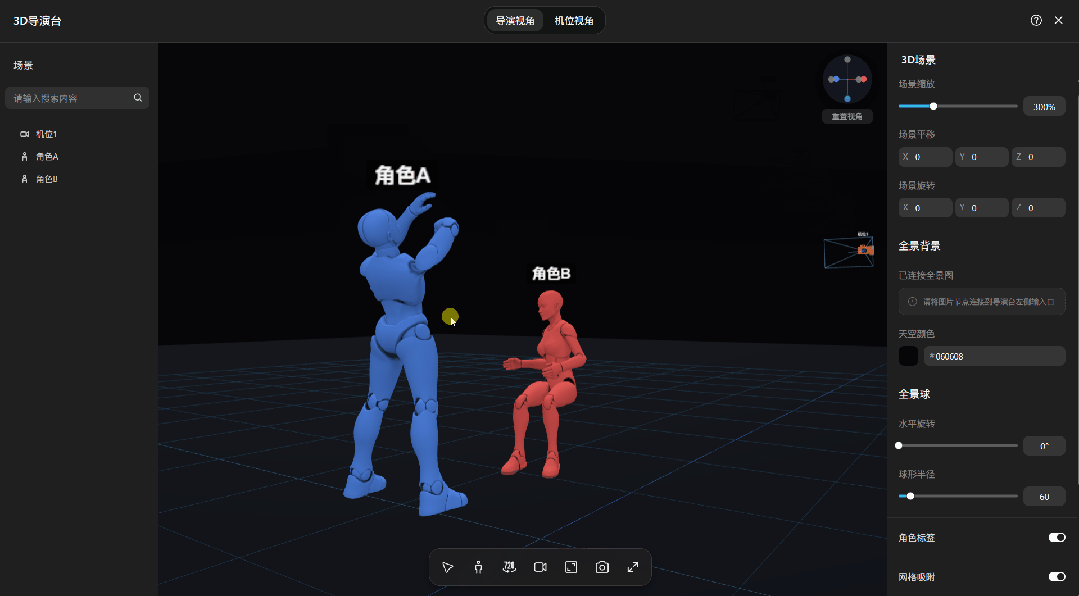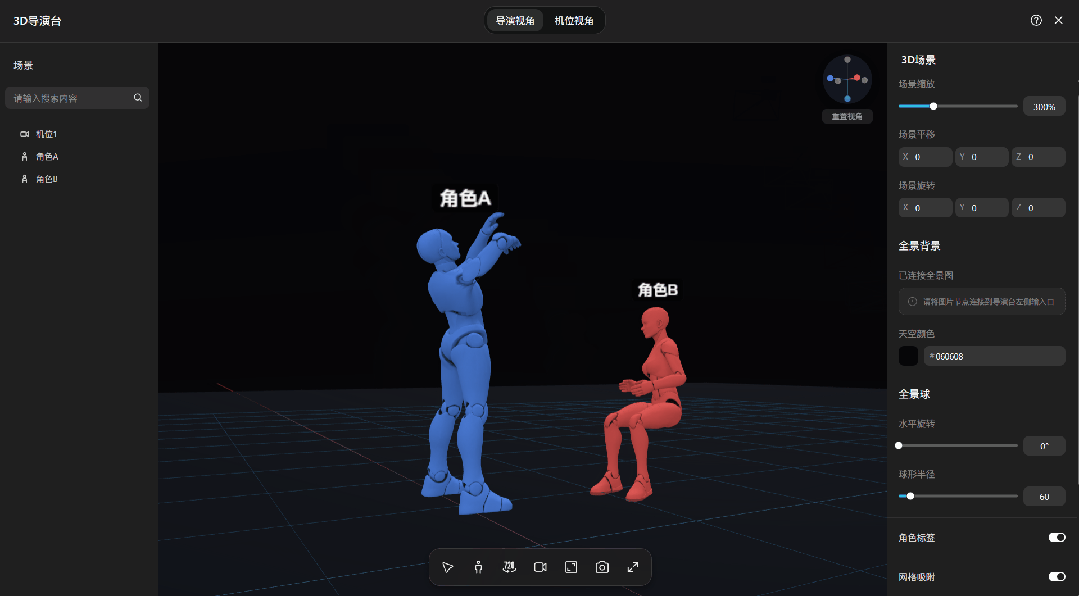
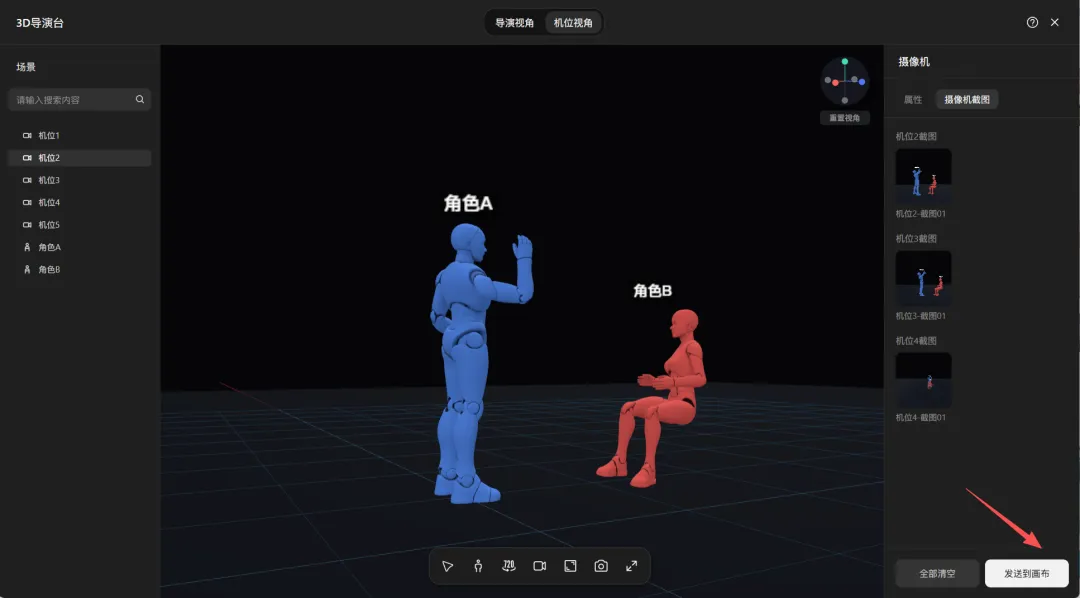
无论是站位、角度还是景别,全都在这张图里,生成出来的画面,和你摆放的3D模型基本一致。
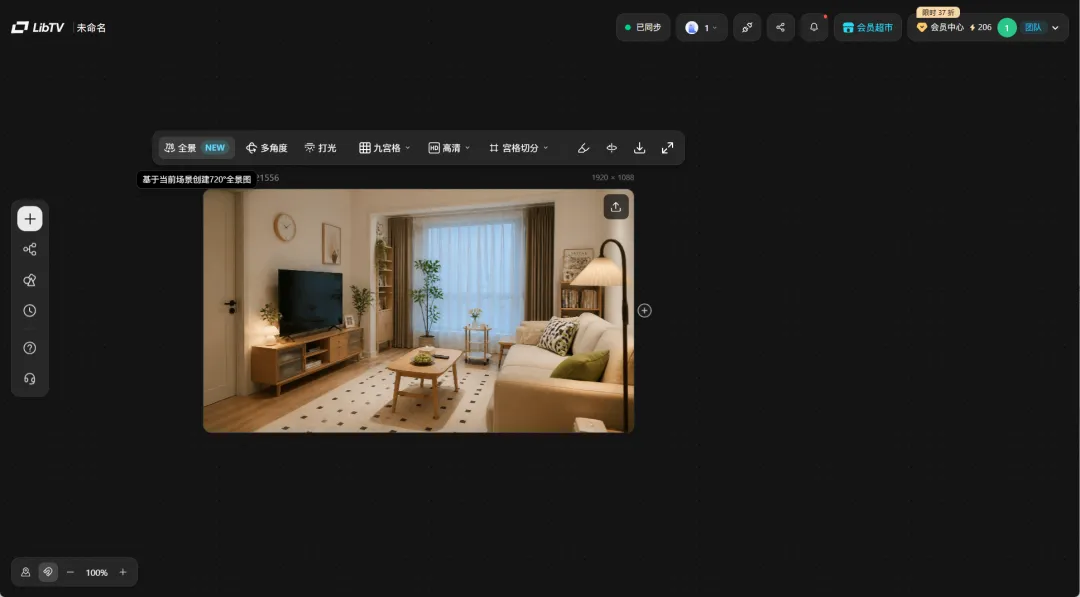
 现在一张效果图进去,全景图出来,空间感、比例、材质一览无余,比任何语言描述都直接。
现在一张效果图进去,全景图出来,空间感、比例、材质一览无余,比任何语言描述都直接。最后,连接图片生成节点,还可以一键生成室内设计的效果图。
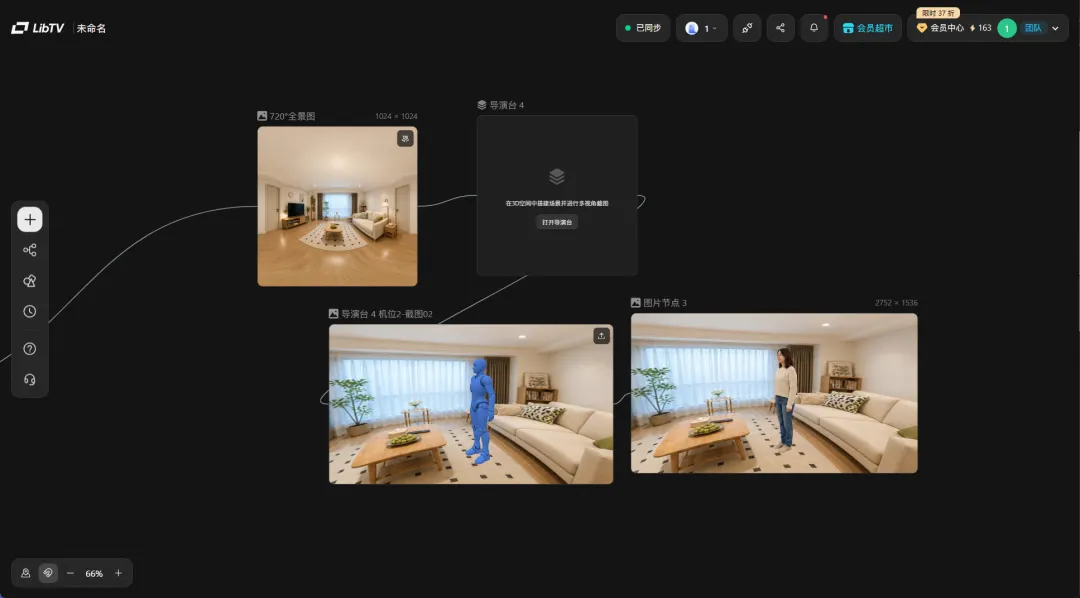

 正面对不对、侧面对不对、四分之三角对不对,每个角度都是需要反复抽卡,而用导演台就直接多了
正面对不对、侧面对不对、四分之三角对不对,每个角度都是需要反复抽卡,而用导演台就直接多了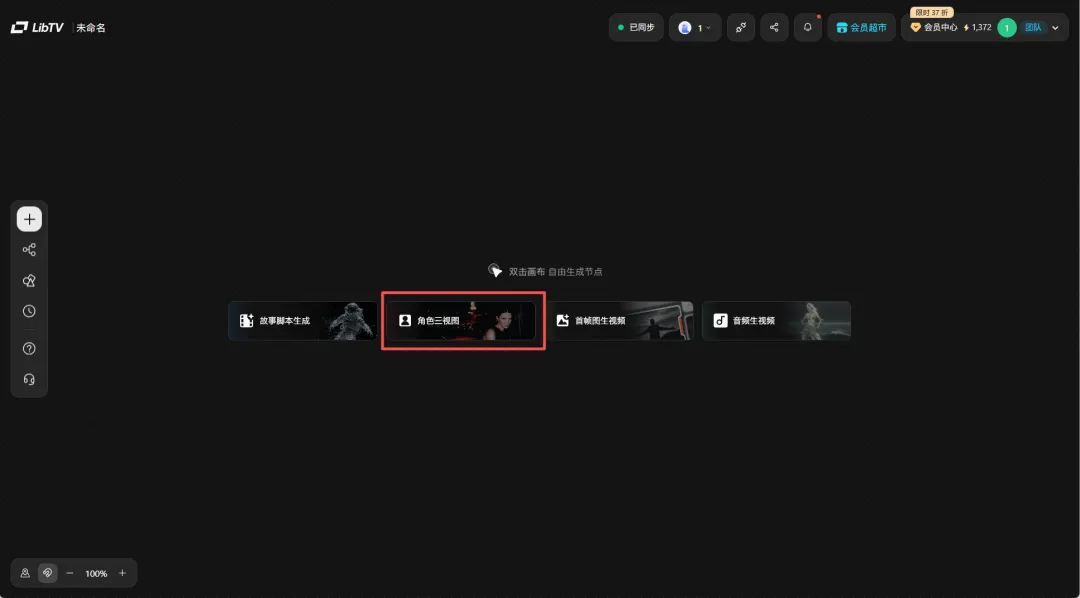
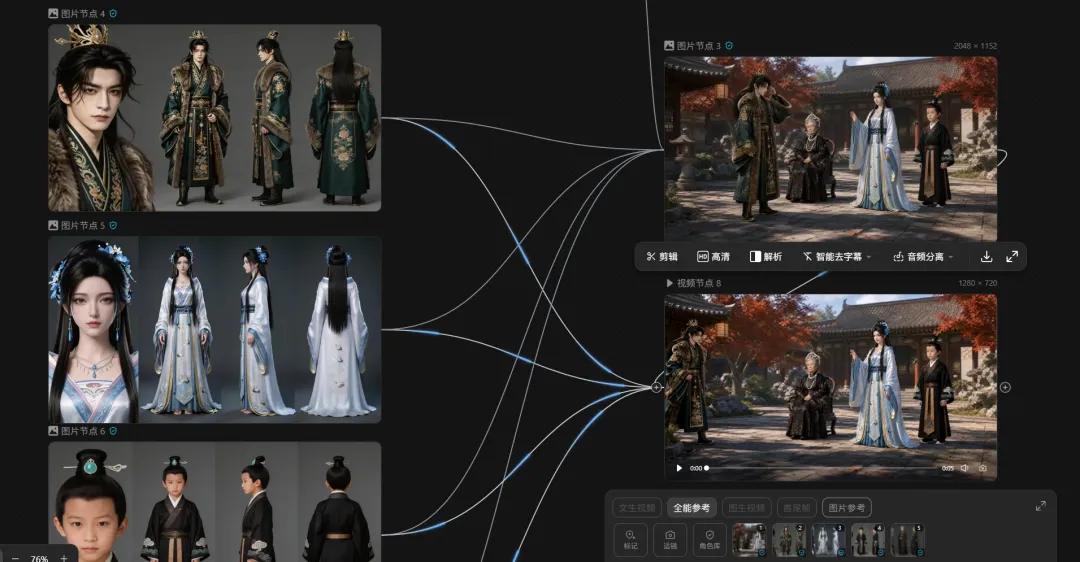
点击角色三视图节点,输入"/"找到角色三视图皆可以一键生成角色设计的三视图。
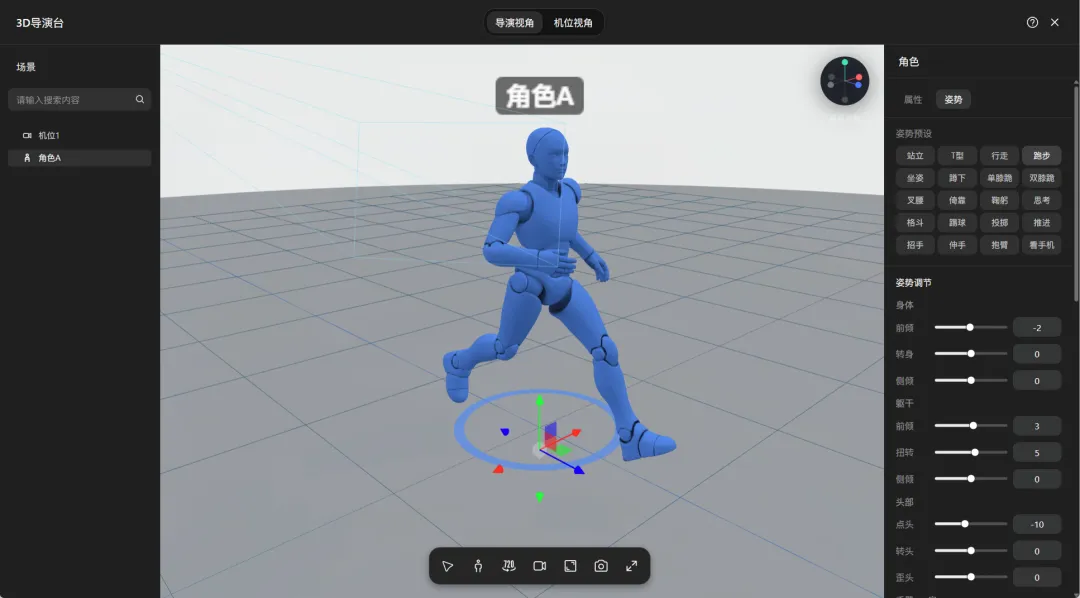
创建一个导演台,用模型摆放好你想要的角色姿势,选择好角度以后发送到画板。
把导演台的截图和角色图都连接到图片生成节点中,就可以控制IP角色的动作以及画面的效果了。
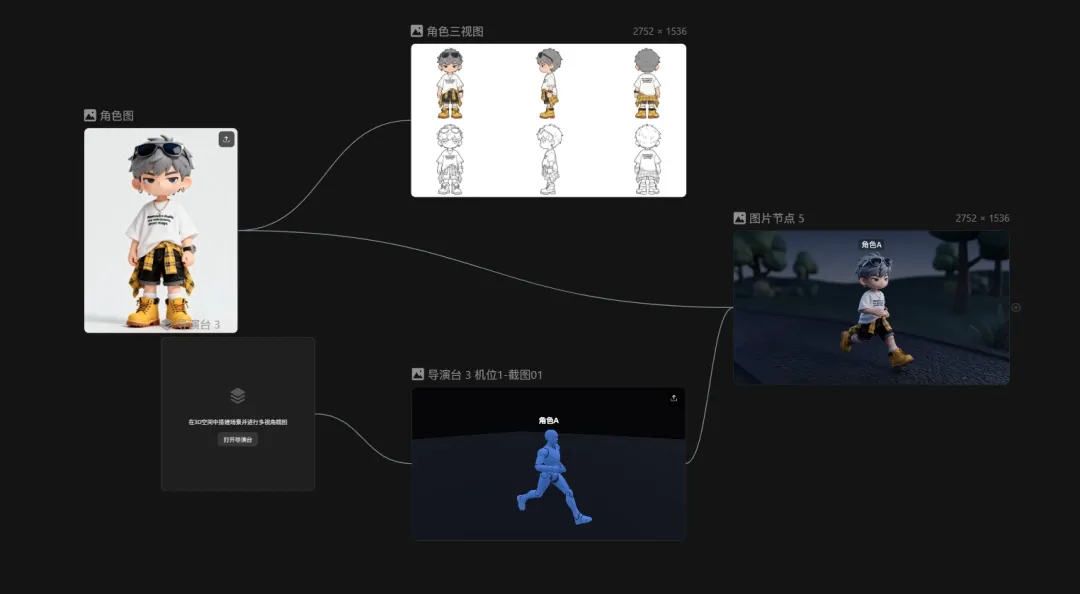
最后,根据我们设计的动作来输出一整套以IP形象的VIS的物料设计。


而在导演台里直接把人摆好:谁在前、谁在后、面朝哪、距离多远,AI 看图直接就能生成。
创建导演台,在导演视角下点击创建角色的按钮就可以直接创建不同的角色。
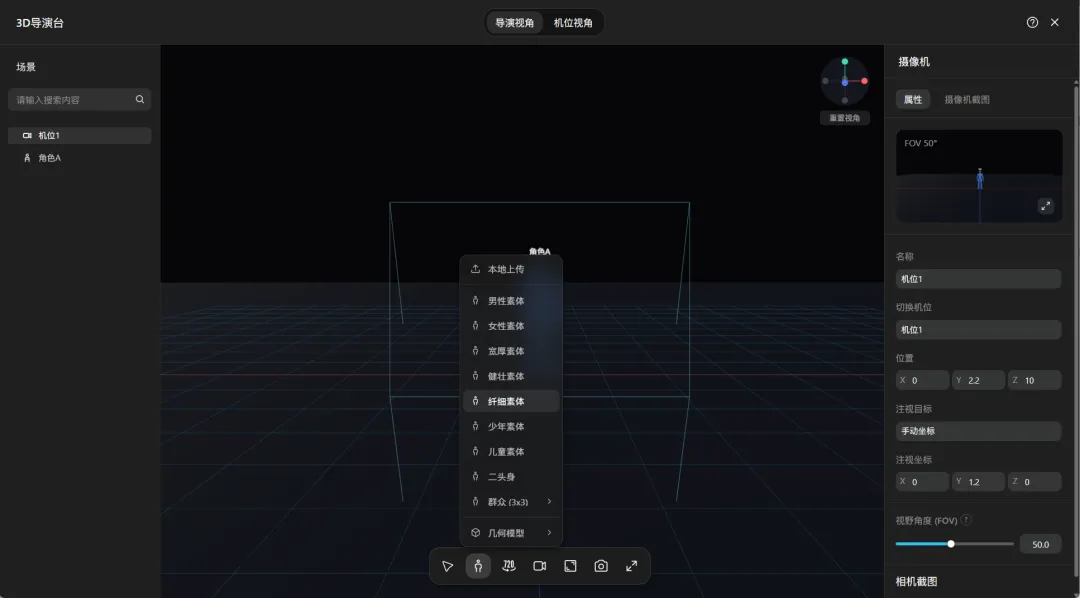
在导演视图下创建多人的站位场景,并且调整每一个人的动作和姿势。
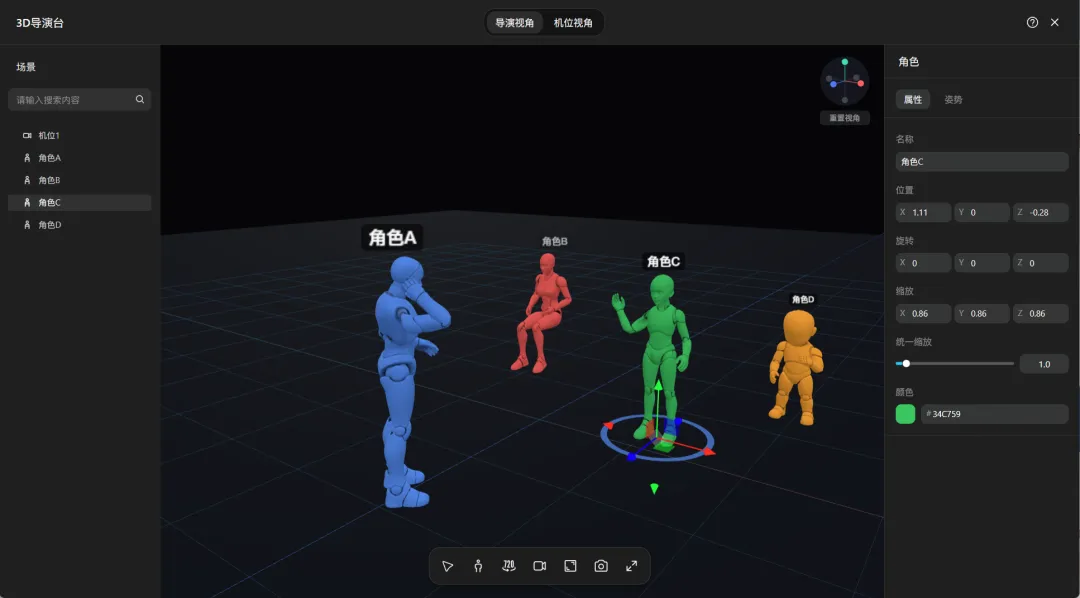
最后在视图节点中配置好任务的设定和角色的站位,就可以保证每一个角色在视频中都是精准的站位。
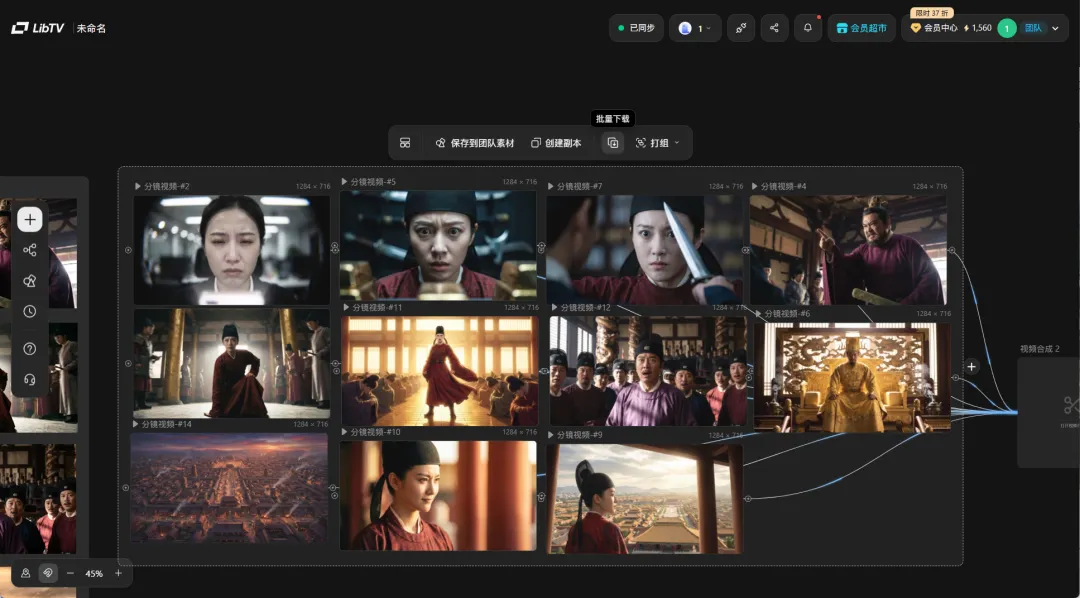
很多人低估了批量操作有多重要,尤其是在制作短剧的过程中每天要处理几十个素材,给多张图片建立参考连线,要一张一张手动连,十几张图连完人都麻了。
批量下载也是一样,以前逐个点击导出,素材一多就是纯体力活。
现在多个素材勾选,一起导出,一次搞定。
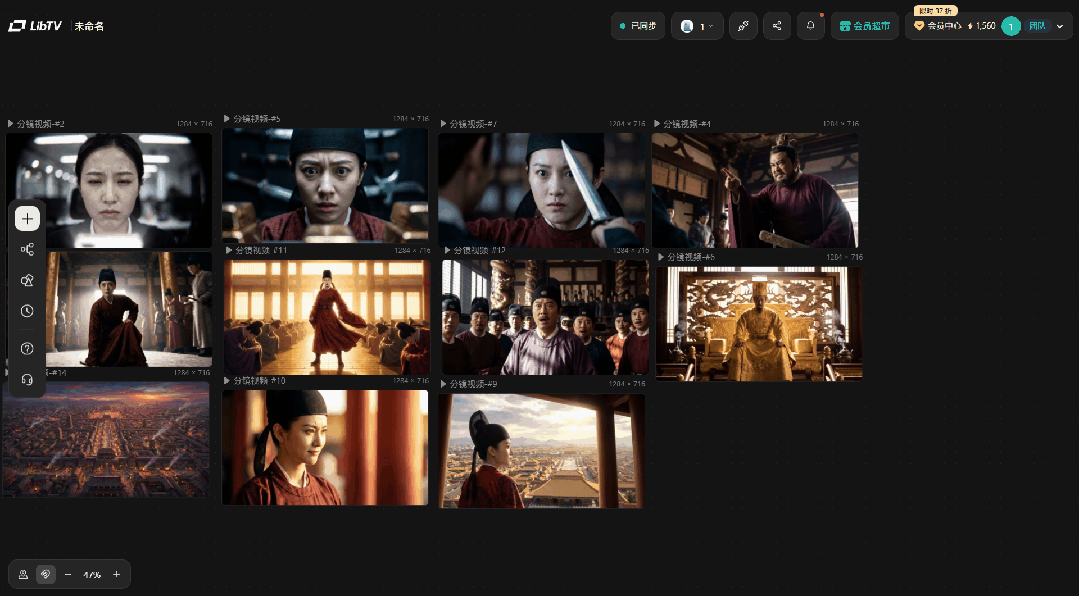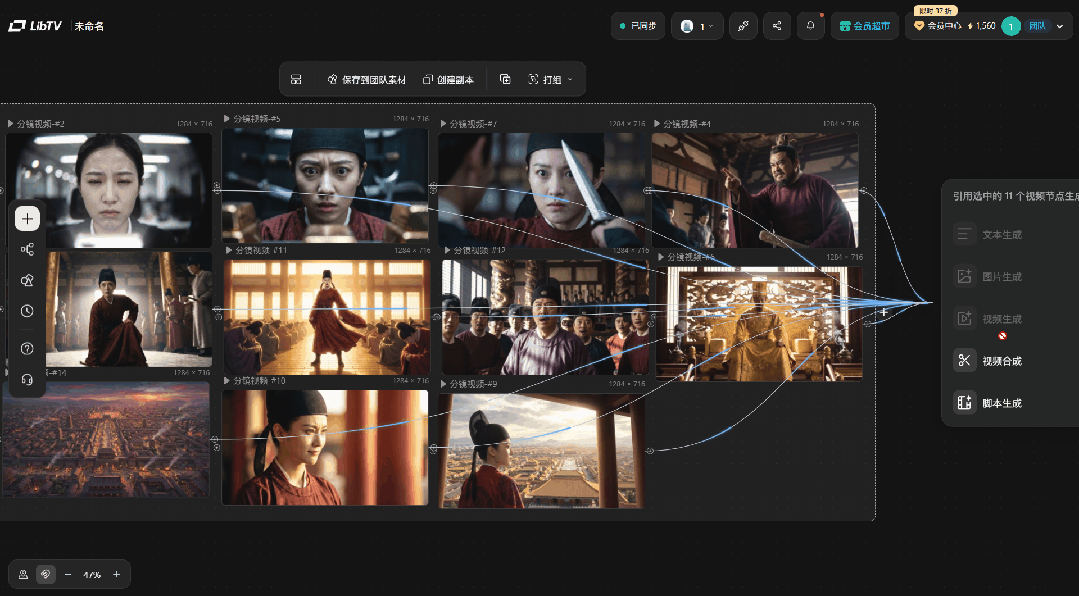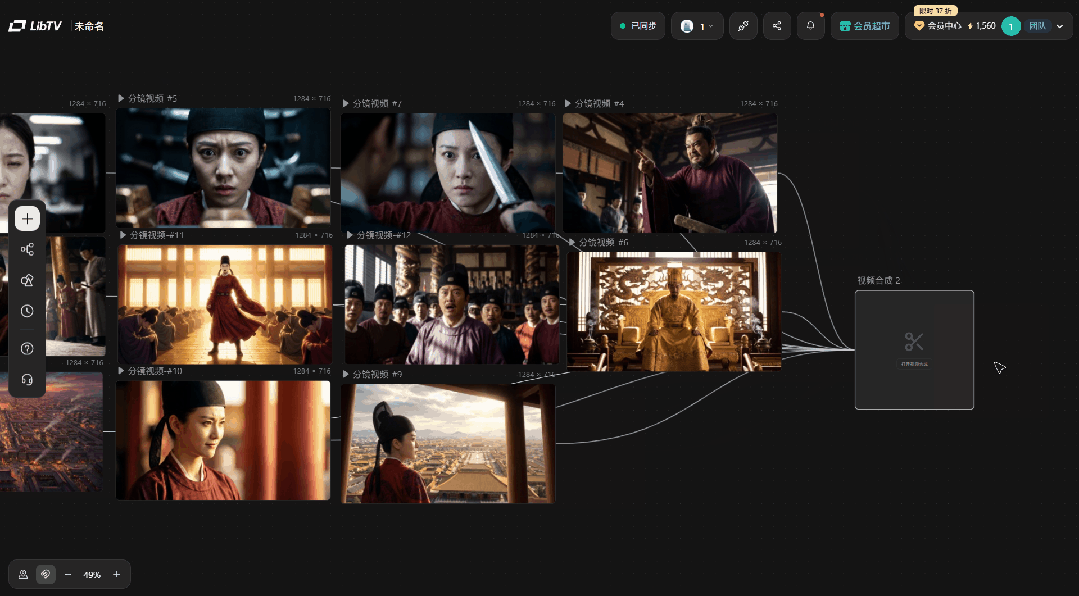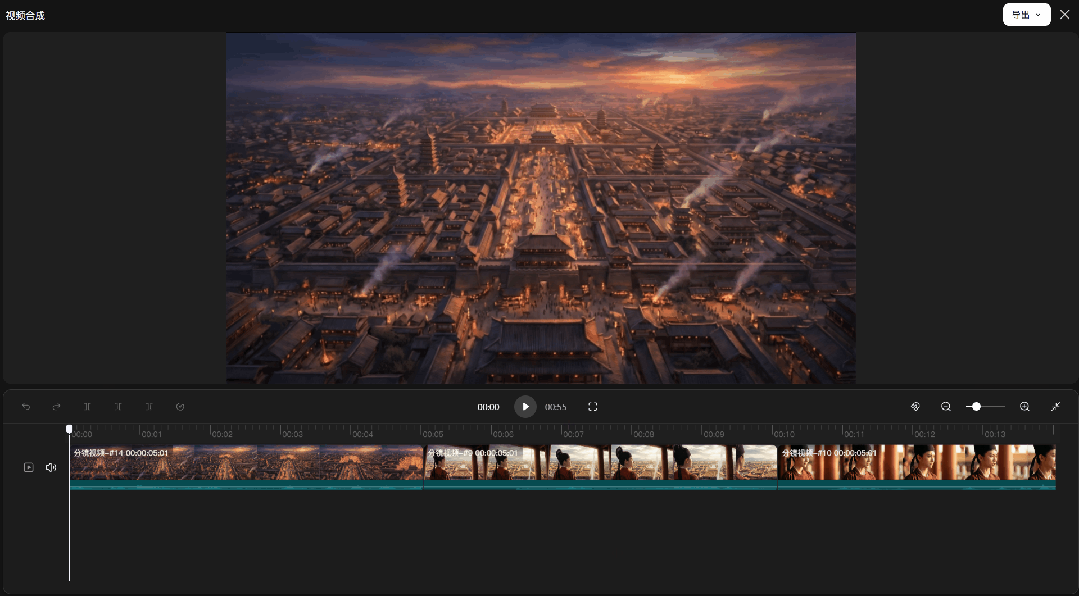
时间线这边的升级也很实在。
以前 AI 视频只能一条轨道走到底,节奏想调只能导出去剪辑软件里折腾。
现在支持多条视频和音频轨道同时编辑,画中画、三分屏直接在画布里做完,不用来回导。
 变速功能也内置了,卡点、慢动作想在哪加在哪加,节奏完全可控。
变速功能也内置了,卡点、慢动作想在哪加在哪加,节奏完全可控。
从素材管理到时间线编辑,这些看起来不起眼的地方,叠在一起省出来的时间,其实才是最值钱的。
以前做一个复杂场景,光在提示词上反复试错的时间,有时候比真正生成的时间还长。
现在摆好截图,直接跑。
如果你最近也在做 AI 视频,正好 LibTV 现在有活动,创作会员低至 3.7 折,最多送 160 条 Seedance 2.0;团队版最多送 2000 条;Seedance 2.0 VIP 不排队,折算下来低至 0.36 元/秒。
 在618促销的期间,入手 LibTV 会员是个比较好的机会。
在618促销的期间,入手 LibTV 会员是个比较好的机会。
