 夜雨聆风
夜雨聆风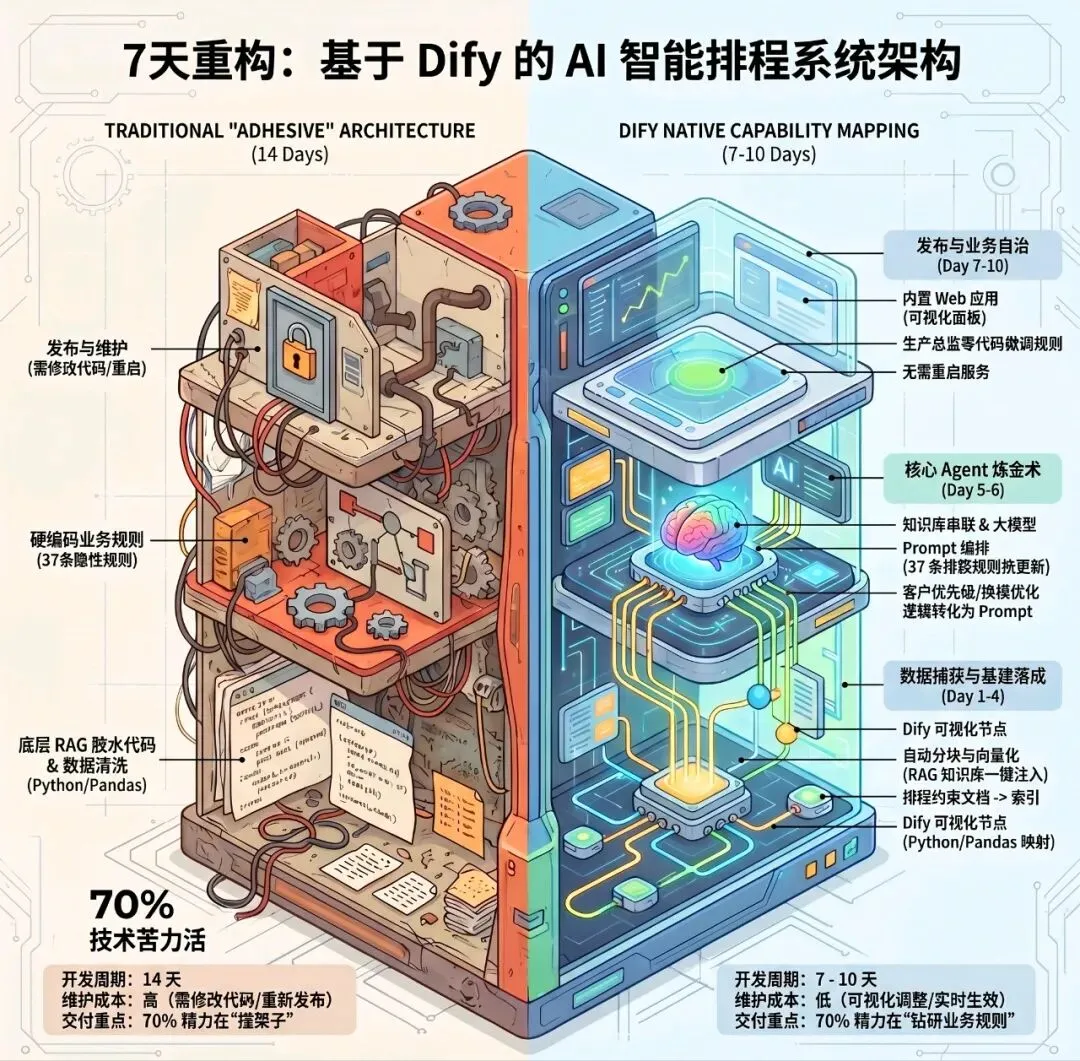
今天,我们来看一个真实AI项目,也是现在热议的FDE的典型案例:“一个FDE项目的14天:我在客户现场搭了一套AI排程系统”,同时,一起感受一下在AI大模型时代,护城河的前移,原文链接:
https://mp.weixin.qq.com/s/axhx6IndVpZ_0WPKKeqxcw
从业务视角的切入点来看,这个项目极其精妙——它精准地抓住了车间“老张的 37 条隐性排程规则”,用大模型解决了传统 APS 系统无法处理的非结构化异常约束。
从技术视角的切入点来看,这个生产排程 AI 智能体,完全可以只用 Dify 一个平台实现所有需求并落地部署,且开发周期将从 14 天压缩至 7-10 天,维护成本呈指数级下降。
一、 架构剥离:原系统模块与 Dify 的 100% 能力映射
原项目的痛点在于:开发者把 70% 的精力花在了“搭架子(写 RAG 代码、接 API、搭后端)”上,只有 30% 的精力在调优业务规则。而 Dify 的核心价值,就是把这 70% 的技术苦力活“平台化”。
我们来看这组直击本质的架构映射:
原项目模块(拼盘架构) | 原实现方式 | Dify 平台原生对应能力 | 差异 |
数据同步 | Python 定时脚本 (Cron) | 工作流定时触发节点 | 可视化配置调度时间,无需手写服务器监控代码,且自带可视化运行日志。 |
数据清洗 | Pandas 脚本 | 代码节点 (Code Node) | 直接在云端/容器内运行 Python 代码,输入输出变量与整个工作流无缝融合,拒绝代码散落。 |
RAG 知识库 | LlamaIndex + Milvus + BGE 模型 | Dify 原生知识库 | 一键上传排程约束文档,平台自动完成分块(Chunking)、向量化与检索,完全消灭 RAG 底层胶水代码。 |
排程 Agent | 手写 Prompt 编排代码 | 提示词编排 + Agent 工具 | 支持模板变量提取、可视化版本管理。老张的 37 条规则可以随时热更新,无需重启服务。 |
前端界面 | 钉钉宜搭 | Dify 内置 Web 应用 | 开箱即用的对话与展示界面,免去跨系统对接的 API 鉴权折磨,一键发布即可使用。 |
结论: Dify 不是一个简单的套壳工具,它是一个封装了 LLM 应用开发全生命周期的“集成调度总线”。原项目的所有技术栈,在 Dify 中都能找到原生的、可视化的平替方案。
二、 破局实战:7-10 天极速交付的 FDE 路径
抛弃了繁琐的环境配置,我们可以将原本 14 天的战线大幅压缩。在 Dify 的加持下,您的实施团队可以将绝大部分精力倾注于“业务规则”本身。
▶ Day 1-2:需求穿透与数据捕获(业务为王)
技术永远是最后一步。前两天的工作与原项目完全一致:跟着车间主任老张,把排程的 37 条决策规则(客户优先级、交货紧急度、换模优化等)全部“榨取”出来,并导出 ERP 历史数据。
▶ Day 3:搭建基础工作流与数据清洗(基建落成)
在 Dify 中创建工作流应用。拖拽出一个“定时触发节点(设定凌晨 2 点运行)”,连接一个“代码节点”。将原项目中写好的 Pandas 清洗代码直接粘贴进去:处理缺失交货期、校正设备状态、核对物料库存。测试运行,确保干净的数据流出。
▶ Day 4:构建 RAG 生产排程知识库(注入灵魂)
在 Dify 知识库面板,上传清洗后的历史订单、设备约束参数以及老张的 37 条规则。选择 BGE-M3 作为嵌入模型,一键构建索引。以往需要两天才能调通的 Milvus 向量库,现在只需两分钟。
▶ Day 5-6:开发排程 Agent(核心炼金术)
这是项目的核心。在工作流中串联“知识库检索节点”与“大模型节点”。将业务逻辑转化为极其严密的 Prompt:
你是一个生产排程专家。你的任务是根据以下信息,生成今天的生产排程计划。
## 输入信息
- 今日订单列表:{{orders}}
- 设备状态:{{equipment}}
- 物料库存:{{materials}}
- 历史排程规则:{{knowledge}} # 这里自动注入知识库检索结果
## 排程规则(优先级从高到低)
1. 客户优先级:A类 > B类 > C类
2. 交货紧急度:交货日期-今天 < 3个工作日的订单优先
3. 设备匹配:产能>1000件/天的设备排大订单,反之排小订单
4. 换模优化:模具相同的产品排在一起
5. 物料约束:缺料的订单不能排
6. 同一客户的同一订单,必须排给同一台设备
7. 设备精度与客户等级匹配
8. 遇到冲突时,按客户优先级 > 交货紧急度 > 设备利用率的顺序决策
## 输出格式
JSON格式,包含:
- schedule: 每条产线今天排哪些订单
- reasoning: 每条排程决策的理由
- warnings: 异常情况(缺料、设备故障等)
利用 Dify 的调试面板,拉取历史数据进行高频回测,迅速将排程准确率逼近 85% 以上。
▶ Day 7:发布前端与权限管控(开箱即用)
开启 Dify 内置的 Web 应用。通过简单的拖拽,形成清晰的展示界面。利用 Dify 的 API 或内置功能,配置角色权限:调度员可以微调排程,一线工人只能查看本产线任务。
▶ Day 8-10:现场压测、隐性规则回填与交付
拉着老张进行系统与人工的背靠背排程大比武。发现系统考虑不周的地方(例如某台设备的刀具刚换过),直接在 Dify 的 Web 界面修改 Prompt 规则,实时生效,零代码重启。 最后输出标准操作手册,完成交付。
三、 为什么 Dify 类LLMOps平台是甲乙双方采用 FDE 模式的最优解?
面对这套新架构,您可能会问:企业为什么要改变现有的开发习惯?核心在于这套架构能为您带来无法抗拒的商业与管理收益:
开发效率的绝对压制(提升 50%+):把工程师从底层的接口联调、数据库运维中解放出来,所见即所得。对于 FDE 团队而言,这意味着同样的人力,可以并行交付双倍的驻场项目。
“业务与 IT 的和解”(维护成本暴跌):传统的纯代码 Agent 一旦上线,业务部门想改一条规则(比如把 B 类客户的优先级调高),必须提 IT 需求、改代码、走测试发布流程。在 Dify 中,业务逻辑与系统代码彻底解耦。生产总监甚至可以自己在可视化的 Prompt 面板里调整规则,真正的“业务人员自治”。
消除“黑盒恐慌”(内置级可追溯性):在合规极严的药企环境,AI 最大的风险是不可解释。Dify 内置的监控面板和日志追踪,能清晰展示大模型每一次决策到底检索了知识库里的哪一句话、消耗了多少 Token。这为未来的系统验证(Validation)打下了天然的审计基础。
四、 Dify方案的底牌:回应硬核技术质疑
当然,作为严谨的 IT 决策者,您必定会有以下技术顾虑:
疑问 1:Dify 的代码节点能扛住复杂的 Pandas 运算吗?
底牌: 完全可以。Dify 代码节点支持 Python 3.10+ 环境运行,预装了 Pandas 等常用库。您的清洗逻辑不需要任何妥协。
疑问 2:如果是高度机密的排程数据,能做私有化部署吗?
底牌: Dify 最强大的护城河之一就是其开源和企业版私有化能力。通过 Docker,一键部署在药企内网的服务器上,模型也可以对接本地部署的 vLLM 或 Ollama,实现数据 100% 物理隔绝,不出厂区半步。
疑问 3:如何把结果推给下游的 MES 或 ERP?
底牌: Dify 应用发布后,自带标准的 RESTful API。您的旧有系统只需要写几行代码请求这个接口,就能拉取到完美的 JSON 排程结果,极其符合现代微服务架构规范。
友好建议:
在 Agentic AI 爆发的当下,使用 Dify 这类成熟的 LLMOps 平台,把底层复杂的 RAG、记忆、工具调用全部外包给平台引擎,让您的架构师和业务专家把所有弹药倾注在“业务规则挖掘”上,才是当前 FDE 交付的最优技术战略。
所以,AI大模型时代的护城河是什么呢?这个案例完全依赖老张,那老张是行业里面的Top级吗?他的“37条规则”是“行业圣经”吗?
