 夜雨聆风
夜雨聆风本期摘要
你和ChatGPT聊的内容,对方公司会保存吗?会用你的数据训练下一代模型吗?你的个人信息会泄露吗?这一篇把隐私问题彻底讲清楚,包括你能做什么来保护自己。
上篇回顾
上篇讲了大模型和以前AI的本质区别——从专用工具变成通用引擎,Scaling Laws让能力随规模幂律增长,100亿参数以上出现涌现能力。程序员从"写代码"变成"审代码"。
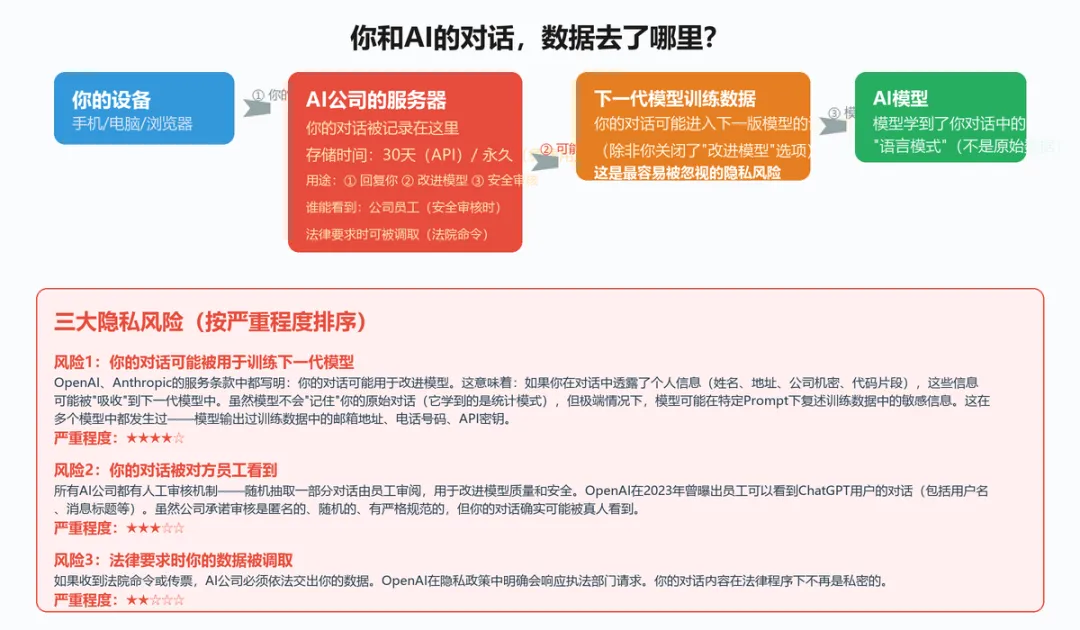
▲ 你的对话数据流向:设备→AI服务器→训练数据→下一代模型
一、你的对话会被保存吗
答案是:会。但保存的方式和时间取决于你使用的方式。
ChatGPT网页版/APP(免费用户):你的所有对话历史会被永久保存(除非你手动删除)。OpenAI可以用这些数据改进模型。你的对话会出现在侧边栏的"历史记录"中,随时可以查看和删除。
ChatGPT Plus(付费用户):你的对话历史仍被保存,且默认也会被用于改进模型。但你可以在设置(Data Controls)里关闭"改进模型"选项来退出。这一点和免费用户其实一样——关键不在于你是否付费,而在于你有没有主动关掉这个开关。
API调用:你的对话数据保留30天(用于安全监控),之后自动删除。API数据默认不用于训练模型。这是隐私保护最强的方式。
Claude(Anthropic):你的对话历史默认保存。Anthropic的服务条款写明:API数据保留30天后删除,不用于训练。网页版用户可以关闭"改进模型"选项来防止数据被使用。
Gemini(Google):你的对话历史被Google保存(Google账号体系)。Google可能将这些数据与其他Google服务的数据关联(搜索、邮件、位置)。这是Google生态的隐私特点——数据互通。
二、对方能看到你的对话内容吗
能。但不是你想的那种"有人在看你的每一条消息"。
所有主流AI公司都有人工审核机制——随机抽取一部分用户对话,由标注员审阅,用于评估模型质量和安全性。OpenAI在2023年3月曾曝出隐私事件:由于Redis库的bug,部分用户可以看到其他人的对话标题。虽然OpenAI很快修复了,但这暴露了一个事实:用户的数据确实存储在对方的服务器上,且存在被意外暴露的风险。
人工审核的特点:随机的(不是针对你)、匿名的(审核员不知道你是谁)、有规范的(审核员不能复制、截图或外泄对话内容)。但即使有这些规范,你的对话确实可能被真人看到——包括你在对话中分享的个人信息、商业机密、代码片段。
此外,如果收到法院命令或传票,AI公司必须交出你的数据。OpenAI在其隐私政策和信任页面中明确表示,会依法响应政府和执法部门的数据请求。这意味着在司法程序下,你的对话内容不再是私密的。
三、你的数据会被用来训练模型吗
这是最核心的问题。答案取决于你的使用方式:
ChatGPT免费用户:是的。OpenAI明确说可能用你的对话数据改进模型。这意味着:如果你在对话中写了"我的名字叫张三,我在XX公司做Java开发",这段话可能被用于训练下一代GPT模型。模型不会"记住"你的原始对话(它学到的是统计模式和语言规律),但在极端情况下,模型可能在特定Prompt下复述训练数据中的敏感信息。
事实上,训练数据泄漏(Training Data Extraction)已经在多个模型中被证实:研究人员通过精心设计的Prompt,让模型输出训练数据中的邮箱地址、电话号码、API密钥、甚至源代码。这说明:你输入AI的敏感信息,真的有可能被"吸"进模型里。
ChatGPT Plus用户:和免费用户一样,对话默认会被用于改进模型,但可以在设置里关闭"改进模型"(Improve the model for everyone)选项主动退出。换句话说,隐私保护靠的是你手动关开关,而不是付费身份。
API用户:API数据默认不用于训练。这是API和网页版的最大区别之一。如果你在意隐私,用API是最安全的选择。
四、真实案例:隐私是怎么泄露的
案例1:ChatGPT标题泄露事件(2023年3月):由于Redis开源库的bug,约1.2%的ChatGPT Plus用户可以看到其他人的对话标题和部分内容。包括支付信息(部分信用卡号后四位)、用户邮箱等。OpenAI紧急下线ChatGPT数小时修复。这是AI隐私史上影响较大的一次数据泄露事件。
案例2:三星员工数据泄露(2023年4月):三星公司员工在使用ChatGPT时,把公司源代码粘贴到对话中让AI帮忙debug。这些数据被传到OpenAI的服务器。三星因此在2023年5月禁止员工使用AI聊天工具。这个案例提醒:公司机密代码绝对不要粘贴到在线AI工具中。
案例3:模型记忆训练数据(2021年起的多项研究):多篇研究论文证实,大模型可以通过特定Prompt输出训练数据中的个人信息。由Google研究员Nicholas Carlini领衔、联合OpenAI、斯坦福、伯克利等机构的研究(《Extracting Training Data from Large Language Models》)成功让模型吐出训练数据中的邮箱地址、电话号码等,成功率约0.1-1%。虽然概率不高,但对于敏感信息来说,任何非零概率都意味着风险。

▲ 四种隐私保护方案对比:API、关闭选项、脱敏、本地部署
五、怎么保护自己的隐私
方法1(最强保护):用API代替网页版。API数据默认不用于训练,30天后自动删除。每次对话独立,不会关联到你的账号历史。成本:GPT-4o输入$2.50/百万Token,普通对话一次约消耗2000 Token,约$0.005。一个月1000次对话约$5。
方法2(简单有效):关闭"改进模型"选项。ChatGPT设置→数据控制→关闭"Chat controls"和"改进模型"。Claude设置中也有类似选项。这能阻止你的数据被用于训练,但对话历史仍被保存(你可以手动删除)。
方法3(零成本):敏感信息脱敏。在对话中把真名换成"张三",公司名换成"XX公司",代码中的API密钥换成"xxx",邮箱换成"xxx@xxx.com"。这是最简单也最有效的隐私保护方法——即使数据被保存或被用于训练,也不会暴露真实信息。
方法4(终极方案):本地部署开源模型。用Ollama或llama.cpp在本地运行开源模型(如Qwen3、Llama 3、DeepSeek V3)。数据完全不出你的设备,零隐私风险。缺点:需要GPU(推荐RTX 4090或Mac M系列芯片),且模型能力略弱于GPT-4o。
绝对不要做的事:①把公司源代码/机密数据粘贴到在线AI工具 ②把个人密码、API密钥、身份证号输入AI ③在AI对话中讨论未公开的商业计划 ④假设你的对话是"阅后即焚"的——它们不是。
API是隐私保护最强的方式
数据30天后自动删除,不用于训练。一次对话约$0.005
关闭"改进模型"选项
设置里可以关。但这只阻止训练用途,不删除存储
敏感信息脱敏是最实用的日常保护
真名换假名,代码中的密钥换xxx,邮箱换xxx@xxx.com
公司代码和机密绝对不要粘贴到在线AI
三星已经为此付出代价。这是红线
下期预告
大模型是怎么学会说话的
预训练、微调、RLHF三步走流程图解
看完有启发的话,点个"在看"再走
本文包含AI辅助创作内容,作者已审核并对全文负责
