 夜雨聆风
夜雨聆风2026年5月19日,Nature同时刊登了两篇重量级论文。一篇来自Google DeepMind,一篇来自FutureHouse。它们在做同一件事:让AI不只是"回答问题",而是像真正的科学家一样——提出假设、自我辩论、设计实验、迭代优化。
这不是又一个大语言模型的"聊天升级"。这是一次科研范式的底层变革。
一个能做科研的AI,长什么样?
先说结论:Google把这个系统叫做Co-Scientist(协研者)。
它不是一个人工智能助手。它是一个由多个AI智能体组成的"虚拟科研团队",每个成员有明确分工:

这六个智能体在一个监督协调者的管理下异步协作——就像一个真实的科研团队,有人提想法,有人挑毛病,有人做决策,有人持续优化。整个过程形成一个闭环循环:
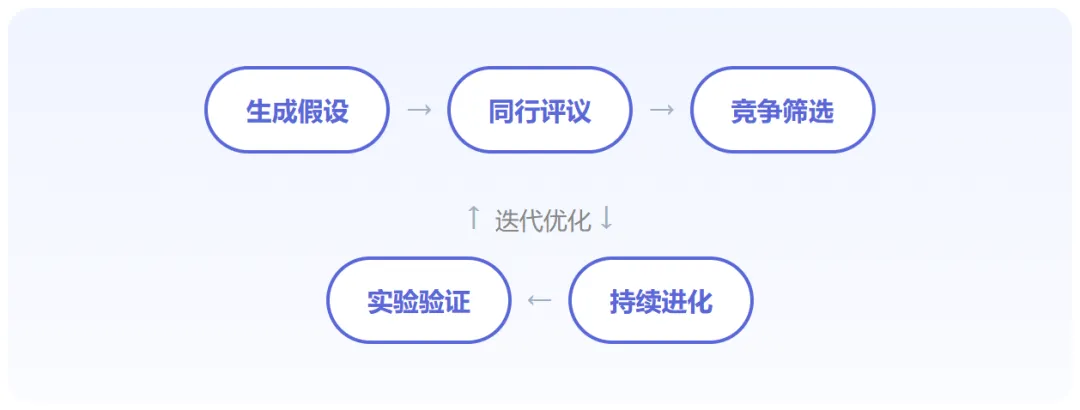
注意这个流程的核心:它模拟的不是"写论文"的过程,而是科学研究本身的思维过程。提出假设→被质疑→被比较→被优化→再验证。这是每一位真正做过科研的人最熟悉的日常。
最硬核的创新:让AI自己跟自己"打比赛"
Co-Scientist最引人注目的设计,是它的"想法锦标赛"(Tournament of Ideas)机制。
这个机制借鉴了AlphaGo和AlphaStar的原理——只不过这一次,AI下的不是围棋或星际争霸,而是科学假说之间的辩论赛。
具体怎么做?系统会同时生成数百甚至数千个研究方向和假设。然后,排名智能体组织这些假设进行成对比较,就像棋手的Elo评分系统一样——赢的假设获得更高分数,输的被淘汰或重组。进化智能体会把高分假设进行交叉组合,产生更优的新一代假设。
关键发现:Google在203个不同研究目标上测试了这个机制,结果显示——Elo评分随着推理时间持续上升,没有出现性能饱和。也就是说,给Co-Scientist更多的计算时间,它就能产生越来越好的假设。这个特性被称为"Test-time Compute Scaling"。
这意味着什么?意味着这个系统的能力不是固定的。你给它更多的"思考时间",它就变得更聪明。这和传统大模型"一次生成一个答案"的模式完全不同。
真刀真枪:它在实验室里做出了什么?
理论说得再好,关键还是看实际效果。Co-Scientist已经在多个真实科研项目中通过了验证,以下是最具代表性的几个案例。
案例一:从2300种药物里找到白血病新药
这是论文中最受关注的验证任务:急性髓系白血病(AML)的药物重定位。
任务本身并不简单:从FDA已批准的约2300种药物中,找出可能治疗AML的候选药物。这是一个典型的"大海捞针"式搜索。
| Binimetinib | |
| Pacritinib | |
| Cerivastatin | |
| KIRA6(IRE1α抑制剂) |
KIRA6值得特别关注。这是一种此前从未被用于AML研究的药物,是Co-Scientist完全自主提出的全新候选。在体外实验中,它对白血病细胞的杀伤效果是对正常细胞的18倍——这在药物研发领域是一个非常令人振奋的治疗窗口。
但更厉害的是协同药物组合的发现。药物组合的数量是指数级增长的——从2300种药物中找三药组合,可能性超过20亿种。Co-Scientist在这个浩瀚的空间中找到了有效组合:

不仅如此,Co-Scientist还对这些发现做了临床转化可行性分析。比如它指出Binimetinib最适合"高龄、复发/难治性AML患者"这一临床场景——因为Binimetinib通过UGT1A1代谢而非CYP3A4,可以避免当前AML靶向药常见的药物相互作用问题。
这种分析深度,已经超出了"推荐药物"的层面,进入了临床试验设计的范畴。
案例二:两天破解抗菌耐药性的分子机制
与帝国理工学院José Penadés教授团队合作时,Co-Scientist面对的问题是:cf-PICI(一种可移动遗传元件)是如何跨越不同细菌物种传播的?
这个问题困扰了微生物学界很长时间。Co-Scientist在阅读相关文献后,仅用两天时间独立提出了正确机制:cf-PICI通过与不同噬菌体尾部结构相互作用来扩展宿主范围。
关键细节:这个结论与Penadés团队尚未发表的实验室发现高度一致。也就是说,AI独立推理出了科学家们正在实验台上验证的结果。
案例三:91%抑制率的肝纤维化新疗法
斯坦福大学医学院Gary Peltz教授用Co-Scientist寻找肝纤维化的治疗方案。系统突出了几个被忽视的药物重定位候选,其中一种药物在实验室测试中成功阻断了91%的疤痕相关反应。
其他领域的突破
ALS跨实验室合作细胞衰老逆转新发传染病分子开关代谢性肝病机制衰老应激反应通路
在MIT的ALS(肌萎缩侧索硬化症)研究中,Co-Scientist帮助两个实验室发现了潜在RNA疗法的互补线索;在Abudayyeh-Gootenberg实验室的衰老研究中,系统将大规模筛选数据的分析时间从数月缩短到数天;剑桥大学的Clare Bryant教授用它识别病原体跨物种传播的关键蛋白质,将原本需要数年的工作压缩到数月。
和顶级模型比,它到底强在哪?
公平起见,Google做了一个严格的对比测试。
他们找了15个由生物医学专家设计的高难度问题,让Co-Scientist和目前最强的几个大模型同台竞技:
| Co-Scientist | 多智能体科研系统 |
结果很清楚:在专家盲评中,Co-Scientist在新颖性、潜在影响力和总体偏好三个维度上全部排名第一。而且随着推理轮次增加,领先优势还在扩大。
更重要的是,领域专家的主观偏好与系统的Elo自动评分之间具有较好的一致性。这说明Elo评分不是一个自娱自乐的数字,它能一定程度反映真实科研价值。
同日登刊:Co-Scientist vs Robin
Nature 2026年5月19日 · 同日发表
值得一提的是,FutureHouse在同一天于Nature发表了另一篇论文,介绍他们的AI科研系统Robin。两套系统的对比非常说明问题:
Robin的一个独特优势在于它的Finch模块——可以接收湿实验室的原始数据,自动编写和执行Python代码进行分析,然后根据新的实验结果更新假设。这让它形成了一个更完整的"文献→假设→实验→数据→新假设"闭环。
但两篇论文的同时出现释放了一个清晰信号:多智能体AI科研系统不再是科幻概念,而是已经被严肃学术界接受的研究方向。
冷静看待:它还不能替代科学家
尽管成果亮眼,但论文和配套社论都坦诚地指出了当前的局限性:
第一,文献访问受限。系统主要依赖开放获取文献,无法充分利用付费期刊和负结果数据——而后者恰恰是科学研究中避免重复犯错的关键资源。
第二,幻觉风险依然存在。多智能体的互相制衡可以显著减少但无法完全消除"看似新颖实则荒谬"的错误假设。
第三,处于药物研发的"容易部分"。两个系统的验证都集中在药物重定位(老药新用),这比从头设计新分子要简单得多。绝大多数药物研发失败发生在动物实验和临床试验阶段,而不是细胞培养阶段。
第四,机制解释仍有空白。模型能够发现有效的药物和组合,但对"为什么有效"的深层机制推理仍然有限。
Nature同期发表的社论标题就很直接:"Why AI cannot do good science without humans"(为什么没有人类,AI无法做好科研)。核心观点是:AI系统正在重新定义科学家的角色,但并非替代——人类科学家正从"执行者"转向"首席科学家",负责提出根本性问题、定义实验边界和做出最终判断。
写在最后
Co-Scientist代表的不只是技术进步,更是科研方法论的一次范式转移。
过去,一位科学家一辈子能深入阅读的文献数量是有上限的。能同时并行探索的研究方向也是有限的。能想到的假设组合,受限于个人知识结构和思维定势。
现在,有一个AI系统能够同时探索数千个方向,自动进行数百轮自我辩论和优化,在几天内完成以前需要数月甚至数年的文献消化和假设筛选工作。
它不会替代科学家。但它会极大地放大优秀科学家的能力和产出。
正如爱丁堡大学Filippo Menolascina教授所说:"我认为我们正处于一场科学革命的边缘,这将显著缩短实现突破所需的迭代周期。"
这场革命已经开始。问题是:你准备好迎接你的AI协研者了吗?
参考文献:
Gottweis J, et al. Accelerating scientific discovery with Co-Scientist. Nature (2026). DOI: 10.1038/s41586-026-10644-y
本文基于公开论文及DeepMind官方博客整理,仅供科普交流使用
