 夜雨聆风
夜雨聆风《AI时代的软件测试》发布:重构测试团队的 AI 能力
现在关于 AI 测试的内容已经很多。
有人讲大模型,有人讲 Prompt,有人讲 Agent,也有人讨论自动生成测试用例、自动化脚本生成、AI 测试平台,以及测试人员未来会不会被替代。
这些内容当然有价值。但当一个测试团队真正开始把 AI 放进项目里时,往往会发现:概念并不难理解,难的是落到真实流程里以后,很多问题会重新浮现。
例如,AI 可以根据一段需求快速生成几十条测试用例。第一次看到结果时,团队通常会觉得效率确实提升了。但真正进入评审时,大家很快会开始追问:这些用例依据的是哪条需求?哪些是模型根据上下文推断出来的?哪些场景必须由业务方确认?哪些测试点看起来合理,但其实没有覆盖核心风险?
这就是 AI 测试落地中最容易被忽略的问题。
很多团队以为自己要解决的是“AI 能不能生成测试用例”。但在企业现场,真正更重要的问题是:AI 生成的结果能不能进入正式测试流程,能不能被团队信任,能不能被持续复用。
这也是我们写《AI时代的软件测试》的原因。

这本书并不是想再做一本“AI 工具使用手册”,也不是简单告诉大家如何写 Prompt、如何生成更多测试用例。我们更希望讨论的是:当 AI 开始进入软件测试,测试团队应该如何重新理解自己的方法、知识、流程和协作方式。
为什么 AI 测试在企业里没有想象中简单?
很多团队第一次接触 AI 测试,都会从最直接的场景开始:把需求输入给 AI,让它生成测试用例。
这一步很容易看到效果。
如果需求比较清晰,AI 通常可以很快给出主流程、异常流程、边界条件、权限校验、兼容性等测试点。对于个人提效来说,这已经很有帮助。尤其是在测试人员需要快速整理初版测试思路时,AI 的确能节省不少时间。
但企业落地和个人试用并不是一回事。
个人使用 AI,更关注这一次回答有没有帮助。企业使用 AI,则必须关注结果能否稳定进入正式流程。用例生成得快只是第一步,后面还要经过评审、执行、维护、复盘和团队复用。
这时,问题就不再是“有没有生成出来”,而是“生成出来的内容是否有依据”。
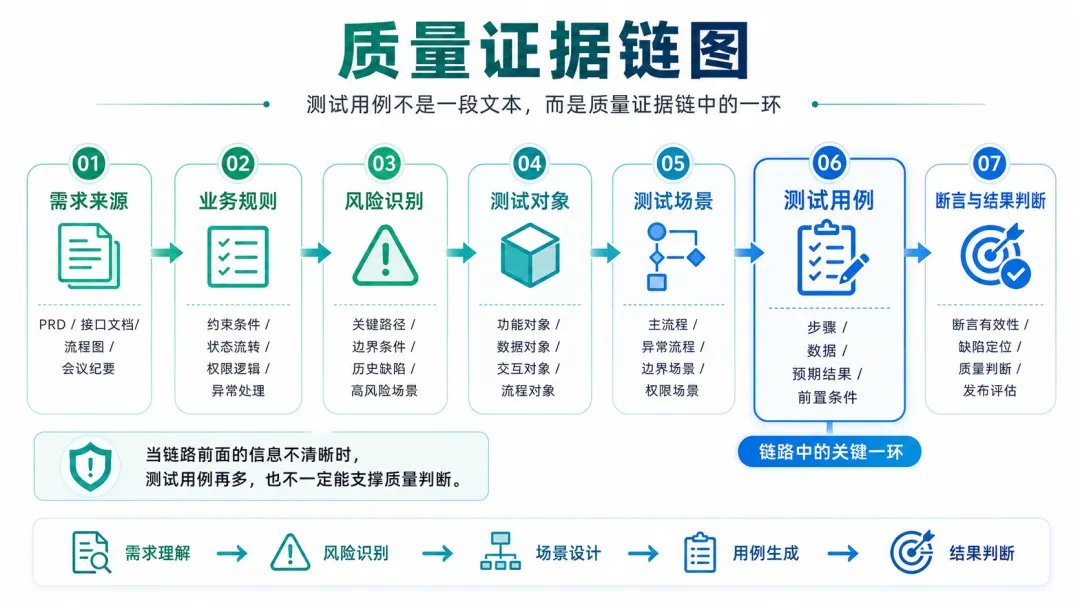
测试用例不是孤立存在的文本。它之所以有价值,是因为它能支撑一次质量判断。一个测试场景为什么存在,它覆盖了哪个业务风险,它验证了什么系统行为,它的断言是否明确,未来需求变化时是否还能维护,这些问题决定了测试设计的质量。
如果 AI 生成的测试用例无法回答这些问题,数量越多,团队的评审成本反而可能越高。
这也是很多 AI 测试试点出现落差的原因。刚开始大家看到的是效率提升,进入项目后面对的却是可信度问题。
真实项目里的需求,通常不是一段干净的 Prompt
很多 AI 测试演示看起来效果很好,往往是因为输入材料本身已经被整理得很干净。
需求边界清楚,业务规则完整,输入输出明确,异常流程也写得比较充分。在这样的条件下,AI 当然更容易生成看起来不错的测试设计。
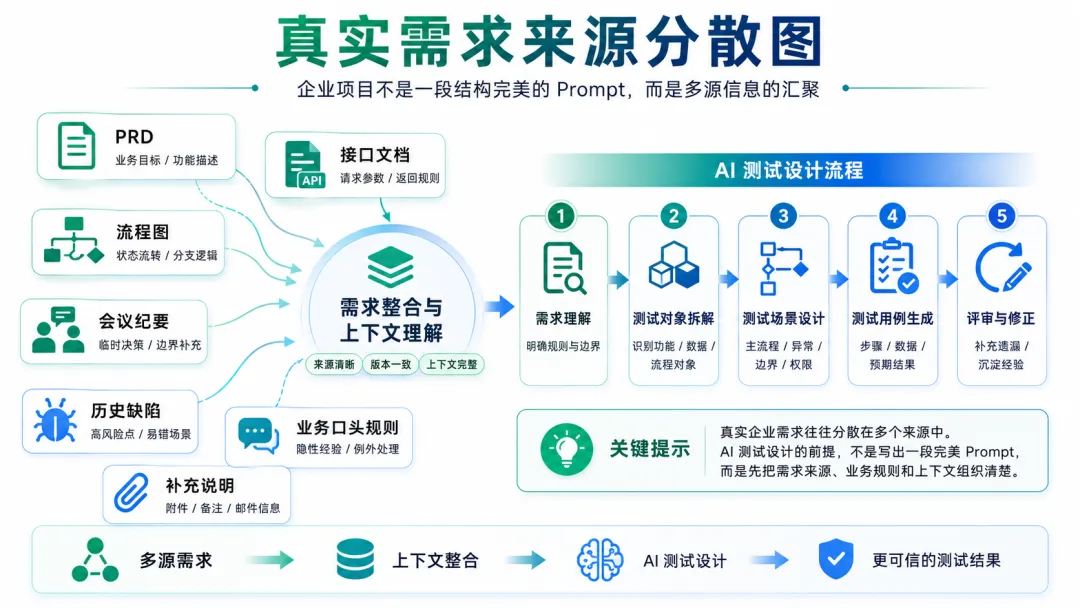
但真实企业中的需求材料通常没有这么理想。
一个功能的完整背景,可能分散在 PRD、接口文档、流程图、会议纪要、历史缺陷、补充说明,甚至业务人员的口头规则里。有些关键约束写在图里,有些规则隐藏在历史系统行为中,还有些风险只有资深测试和老开发知道。
这时,AI 并不是不能参与测试设计,而是必须先解决上下文的问题。
以审批流为例,需求文档里可能只写了“用户提交后由负责人审批,审批通过后进入下一流程”。如果只看这句话,AI 很容易生成提交、审批、通过、驳回等常规用例。但在真实系统里,审批流往往还涉及撤回、转交、超时、重复提交、权限变化、审批人离职、状态回退等情况。
这些场景并不是 AI 完全想不到,而是如果上下文没有给足,模型只能根据通用经验补全。通用经验有时有帮助,但在企业测试中,真正关键的往往是那些和业务规则、历史缺陷、系统边界相关的具体经验。
所以,企业使用 AI 测试时,不能只关注模型能力,还要关注输入材料的组织方式。AI 生成结果是否可信,很大程度上取决于它看到的上下文是否完整、来源是否清楚、版本是否正确,以及哪些内容需要人工确认。
测试经验如果不能沉淀,AI 只能放大个人差异
AI 对个人效率的提升已经很明显。
一个经验丰富的测试人员使用 AI,通常能得到比较好的结果。原因并不只是他会写 Prompt,而是他知道该给 AI 补充什么背景,也知道如何判断 AI 漏掉了什么。
例如,在支付系统中,资深测试人员不会只关注支付成功和失败。他会提醒 AI 注意回调幂等、重复通知、乱序回调、补偿机制、账务一致性和异常对账。在积分账户场景里,他也不会只看积分增加和扣减,而会关注冻结、回滚、并发扣减、过期清算和账户余额一致性。
这些判断背后,是长期项目经验形成的风险意识。
问题在于,这些经验通常没有被结构化沉淀。它们存在于资深人员的脑子里,存在于评审会议里的提醒中,也存在于过去的缺陷复盘和一些零散文档里。当资深测试人员自己使用 AI 时,他可以不断修正模型输出;但换成新人或其他团队成员,效果就会不稳定。
这不是新人不会用 AI,而是团队还没有把测试经验转化成 AI 可以理解和复用的方法。
因此,AI 测试真正要解决的,不只是让某个人写得更快,而是让团队的测试经验能够被表达、被调用、被复用。否则,AI 只是让强的人更强,却不一定能让整个团队变强。
这也是我们非常重视 Skills 的原因。
在测试设计场景中,Skill 不应该只是一个提示词模板。它更应该是一类测试经验的结构化表达。它告诉 AI,在某类业务、某类系统、某类风险下,应该如何拆解测试对象,关注哪些边界,避免哪些常见遗漏,并按照团队认可的方法生成结果。
当这些经验逐步沉淀下来,AI 才有可能从个人工具,变成团队能力的一部分。
企业级 AI 测试,离不开治理
个人试用 AI,通常只需要判断这次结果有没有帮助。
企业使用 AI,则必须多考虑一层:这些结果能不能被纳入流程,能不能被追溯,能不能被复盘,出了问题以后责任边界是否清楚。
这听起来像管理问题,但实际上直接决定了 AI 能不能长期使用。
如果一个团队允许 AI 生成的测试知识直接进入知识库,却没有审核机制,那么错误经验就可能被反复复用。如果 AI 在高风险业务中生成了不完整的测试设计,却没有标记哪些内容来自需求、哪些内容来自推断,后续评审就会很困难。如果不同团队各自使用不同的 Prompt 和标准,短期看效率提升了,长期看反而会造成更大的不一致。
所以,企业级 AI 测试必须考虑治理。
治理不是为了限制 AI,而是为了让 AI 能够被安全、稳定、持续地使用。它至少包括数据权限、输出追溯、人工确认、版本管理、知识回滚、成本控制和责任边界。
当 AI 开始参与需求分析、测试设计、测试数据生成、E2E 测试、回归测试和非功能测试时,这些机制会变得越来越重要。
没有治理,AI 很容易停留在个人工具层面。每个人都觉得有帮助,但团队无法形成统一标准;每次生成都很快,但无法复盘和复用;短期看很热闹,长期看很难进入组织流程。
因此,AI 测试落地本质上不是买一个工具,也不是培训几句 Prompt。它更像是一次测试工程体系的升级。
我们为什么写《AI时代的软件测试》
正是因为看到这些问题,我们整理了《AI时代的软件测试》。
这本书来自我们在 Treeify 产品建设、企业客户交流、测试团队共创和 AI 测试实践中的观察与复盘。
我们见过很多团队第一次看到 AI 生成测试用例时非常兴奋,也见过这些用例因为无法评审、无法追溯、无法复用,最后没有真正进入测试流程。
我们也见过测试人员个人效率提升很明显,但企业因为缺少评价标准、知识沉淀和治理机制,始终无法把这种效率提升扩展到团队层面。
还有一些团队,一开始就希望做 Agent、自主测试和自动回归,但基础的需求理解、测试对象建模、测试经验沉淀还没有建立起来。这样的路径很容易让 AI 看起来很先进,但落地时支撑不住。
这些经历让我们越来越确定,AI 测试转型不能只靠工具。
工具当然重要,但工具只是能力的承载方式。在工具之前,测试团队需要先想清楚:什么是好的测试设计,如何判断 AI 输出是否可信,哪些经验值得沉淀,哪些场景必须人工确认,哪些知识可以复用,哪些错误不能进入正式流程。
如果这些问题没有被回答,AI 工具越强,团队反而越容易产生新的混乱。
因为生成变得太容易之后,真正稀缺的能力就变成了判断能力。
这也是这本书想讨论的核心问题:AI 进入测试以后,测试团队应该如何重新组织自己的方法、知识和流程。
这本书主要讲什么?
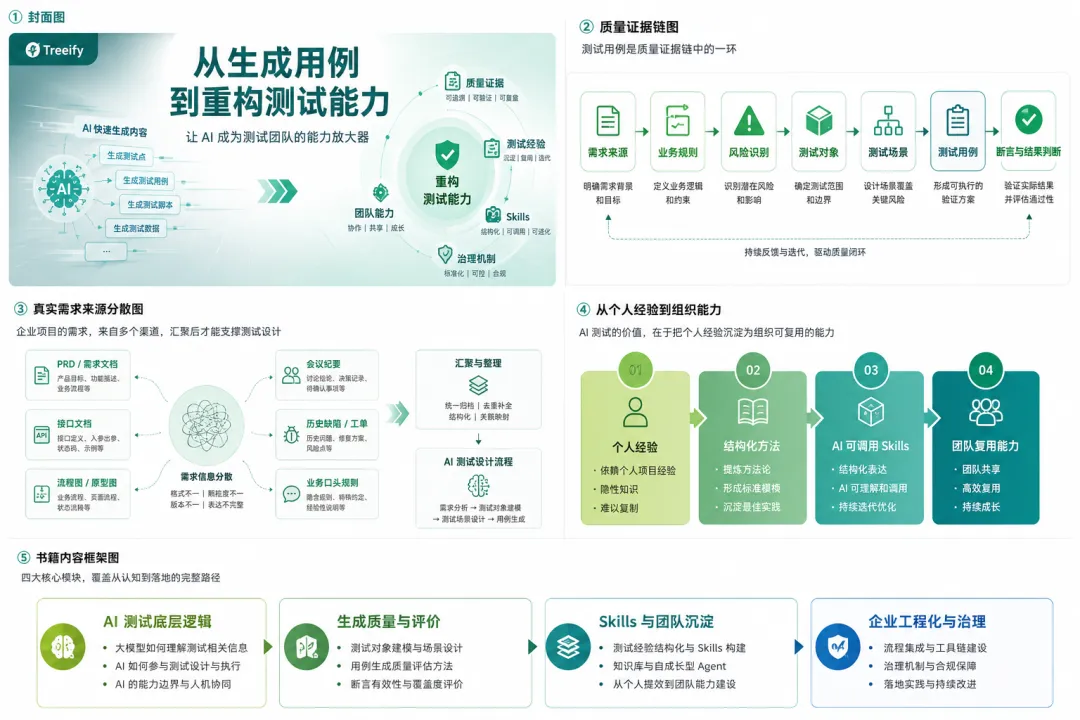
《AI时代的软件测试》覆盖的是从个人提效到企业落地的完整路径。
它不会只停留在某一个工具、某一个 Prompt 或某一个测试类型上,而是围绕 AI 测试转型中的几个关键问题展开。
首先,它会帮助读者理解 AI 测试的底层逻辑。
很多人谈 AI 测试时,会很快进入技巧层面,例如如何写 Prompt、如何生成测试用例、如何生成自动化脚本。但如果缺少底层理解,很容易把 AI 看成一个更快的输入输出工具。
所以,书中会讨论大语言模型如何理解需求、代码、测试、日志和系统行为,也会讨论 AI 为什么能够参与测试设计,又为什么不能简单替代测试人员的判断。
这部分的重点不是追逐概念,而是建立一个基本判断:AI 在测试中的价值,不只是生成文本,而是辅助人理解系统、拆解风险、组织知识和执行任务。
其次,它会讨论 AI 生成结果的质量问题。
很多人使用 AI 生成测试用例后,真正关心的不是能不能生成,而是生成得对不对、全不全、有没有用。
如果 AI 生成的场景很多,却没有覆盖核心业务风险,它的价值就有限。如果断言写得很宽泛,执行后无法判断系统是否真的正确,这样的测试也很难支撑质量判断。如果测试场景无法追溯到需求和风险,团队评审时就很难接受。
因此,书中会从需求理解、测试对象建模、测试场景设计、断言有效性、覆盖率评价等角度,讨论如何判断 AI 生成结果是否真的有价值。
再次,它会讨论如何从个人提效走向团队沉淀。
AI 可以帮助个人更快整理测试点,但企业更关心的是,这些能力能不能被团队复用。如果每个人都依靠自己的 Prompt 和经验使用 AI,短期看效率提升了,长期看却可能形成新的不一致。
因此,书中会重点讨论 Skills、知识库、测试经验沉淀、自成长型测试 Agent,以及如何避免错误经验进入知识体系。
最后,它也会讨论企业落地中的工程化和治理问题。
当 AI 进入真实测试流程后,成本、权限、隐私、合规、流程接入、数据安全和责任边界都不能回避。企业真正需要的不是一次惊艳的生成结果,而是一套能够持续运行、持续复盘、持续改进的 AI 测试工作方式。
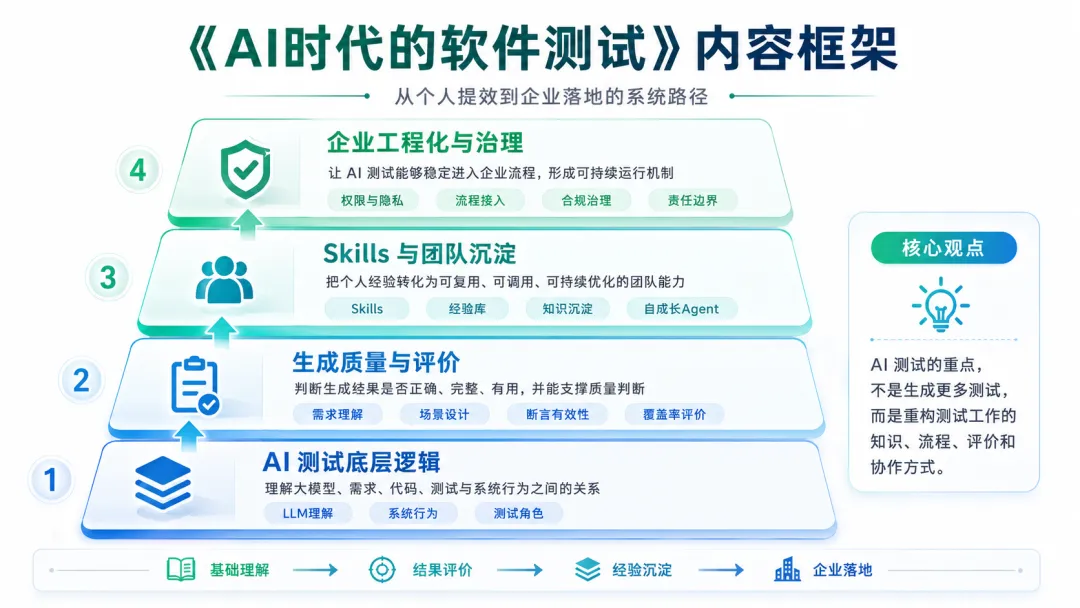
AI 测试的重点,不是生成更多测试
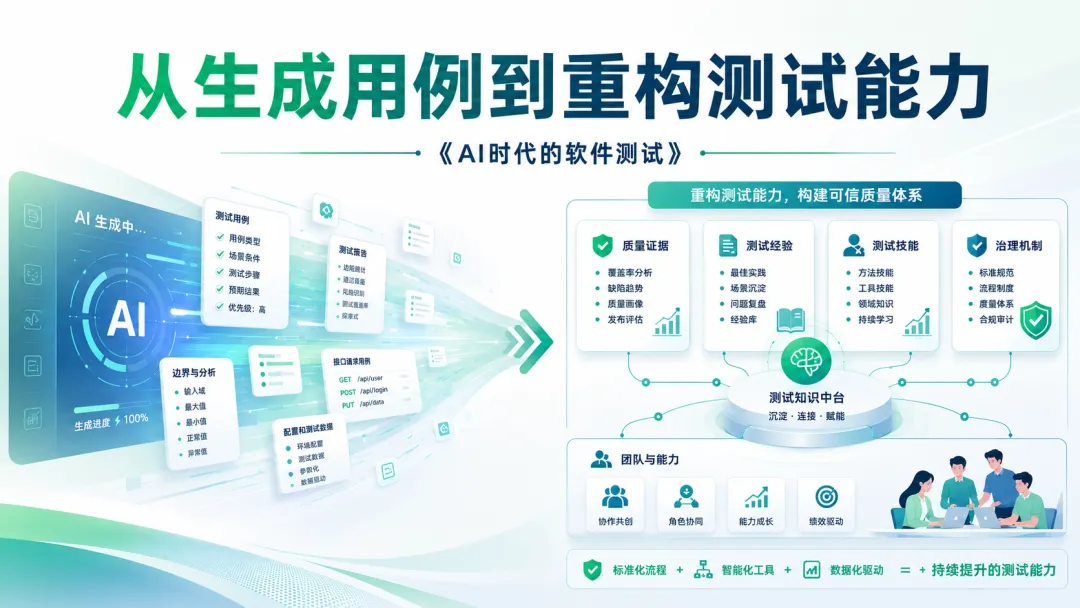
这本书最核心的观点是:AI 测试的重点,不是生成更多测试,而是重构测试工作的知识、流程、评价和协作方式。
原因很简单:当生成成本越来越低,测试工作的瓶颈会发生变化。
过去,测试团队需要花很多时间写测试点、整理用例、补充表格和维护文档。AI 出现以后,这些基础生成工作会被明显加速。测试人员可以更快获得初稿,更快补充场景,也更容易形成结构化结果。
但这并不意味着测试人员的价值降低了。
相反,当 AI 可以生成大量内容时,测试人员的判断能力会变得更重要。测试人员需要识别哪些场景真正有价值,哪些断言过于宽泛,哪些结果只是模型推断,哪些风险必须人工确认,哪些经验应该沉淀为团队资产。
所以,AI 时代的软件测试,不是从“人写用例”简单变成“AI 写用例”。
更准确地说,它会逐步变成一种新的工作方式:人定义方法,AI 执行过程,人负责判断、修正和沉淀。
这才是测试人员真正需要关注的转型方向。
Treeify 是这套方法的一次产品化实践
这也是我们做 Treeify 的原因。
Treeify 不是单纯的“测试用例生成器”。
如果只是让 AI 一次性生成一批测试用例,短期确实可以节省时间,但它很难解决企业真正关心的问题:结果是否可信,过程是否可控,经验是否可复用,团队是否能持续变强。
Treeify 更关注的是,如何帮助测试团队把测试设计过程变得清晰、可审查、可修改、可沉淀。
在 Treeify 中,团队可以把需求文档、业务规则、设计说明、流程图、接口说明等材料作为输入。系统不会直接跳到最终用例,而是先帮助团队理解需求,再拆解测试对象,最后生成结构化测试场景。
这个过程之所以重要,是因为测试设计本身并不是简单的文本生成。
一个好的测试设计,背后一定有拆解逻辑。团队需要先理解系统行为,再识别测试对象,然后设计测试场景,最后形成可执行、可审查、可维护的测试结果。
Treeify 希望把这个过程显性化。
当测试设计过程被拆开,团队才能更清楚地看到 AI 在哪一步理解错了,哪个测试对象遗漏了,哪个测试场景需要补充,哪些经验应该沉淀下来,下一次如何生成得更好。
这就是 Treeify 和普通“一步生成测试用例”最大的不同。
我们不希望 AI 只是替测试人员多写几条用例,而是希望它帮助测试团队形成可自我学习的测试设计能力。
比如,审批流应该如何测试,订单状态流转应该关注哪些异常,积分账户应该覆盖哪些边界,接口异常应该补充哪些场景,不同行业的常见风险应该如何进入测试设计。过去这些经验往往依赖资深测试人员反复提醒,未来它们应该逐步沉淀成 Skills,成为团队下一次可以复用、可以优化、可以持续成长的能力。
所以,如果说《AI时代的软件测试》讲的是 AI 测试落地的方法论,那么 Treeify 就是我们把这套方法产品化的一次实践。
加入 Treeify AI 测试设计共创星球
为了让《AI时代的软件测试》不只是一次性阅读资料,我们会把它放在「Treeify AI 测试设计共创星球」中,和后续的 Skills、案例拆解、Treeify 使用实践一起持续更新。
我们希望这个星球不是一个单向资料库,而是一个面向 AI 测试实践者的共创社区。
如果你只是想快速下载一份资料,这里未必是最适合你的地方。但如果你正在认真思考 AI 如何进入测试设计流程,如何帮助团队提升测试质量,如何把个人经验沉淀成团队能力,那么这里会更适合你。
加入星球后,你可以获得《AI时代的软件测试》完整内容,系统了解 AI 测试、AI Agent、测试设计方法、企业落地路径,以及测试人员在 AI 时代的能力升级方向。
你也可以获得 Treeify 1 个月会员体验,包含 5500 积分,用真实需求文档体验从需求分析、测试对象拆解到测试场景生成的完整流程。
除此之外,我们会持续分享不同行业和场景下的测试用例 Skills,包括金融、电商零售、互联网、汽车、医疗健康、智能制造等方向。这些 Skills 不是简单的测试点清单,而是希望把行业中的测试经验、风险判断和设计方法,逐步整理成 AI 可以理解和复用的能力。
星球也会围绕 Treeify 使用案例、AI 测试方法、测试设计经验和真实业务场景展开共创交流。我们会持续更新书籍内容、测试 Skills、实战案例和 Treeify 使用经验,也欢迎更多测试同行加入讨论,一起把 AI 测试从概念真正推向实践。
星球年费为 199 元。

写在最后
AI 不会只改变测试用例。
它会改变软件测试行业的工作方式。
但这种改变不会自动发生。它需要测试团队重新思考自己的工作方式:哪些内容可以交给 AI 加速,哪些判断必须由人负责,哪些经验值得沉淀,哪些流程需要重新设计。
如果我们只是让 AI 生成更多内容,测试工作可能会变得更快,但不一定变得更好。
如果我们能借助 AI,把测试设计中的方法、经验、判断和协作方式重新组织起来,那么 AI 才有可能真正帮助测试团队建立新的能力。
这正是《AI时代的软件测试》想讨论的问题,也是 Treeify 想长期解决的问题。
我们希望和更多测试同行一起,把 AI 测试从概念真正推向实践。
