 夜雨聆风
夜雨聆风论文:https://arxiv.org/abs/2605.30363
GitHub:https://github.com/mingxuan-yi/regime_shift
2015年12月16日,美联储宣布加息25个基点。这是2008年金融危机之后,美国第一次加息。
如果你是一个美债交易员,你在12月16日的哪个时间点确认这件事?大概率是美联储公告发出来的那一秒。到那个时候,所有的价格已经反映了。
但是如果有人告诉你,2015年10月28日那天的FOMC会议纪要里,措辞已经悄悄变了。某个词从significant变成了notable,某个段落的语气从关切变成了审慎乐观。这些信号单独看微不足道,但放在一起,它们在10月就已经构筑了一个完整的加息叙事。等市场真正定价的时候,已经过去了将近两个月。
2026年5月,布里斯托大学和卡迪夫大学的团队发表了一篇论文,开了一个GitHub仓库。他们干了一件事:把2010年到2024年所有FOMC会议纪要喂给LLM,让它判断每次会议的前后,货币政策是不是要变天了。然后,再用14个宏观变量的真实数据反向验证LLM的判断。结果,26个历史拐点里,它准确标记了23个,F1分数0.82。更关键的是,它的检测几乎没有延迟,,大多数拐点在当天就被抓到了。
今天奇哥就把这套方法拆开看看。
一、为什么纯数据方法抓不住政策拐点?
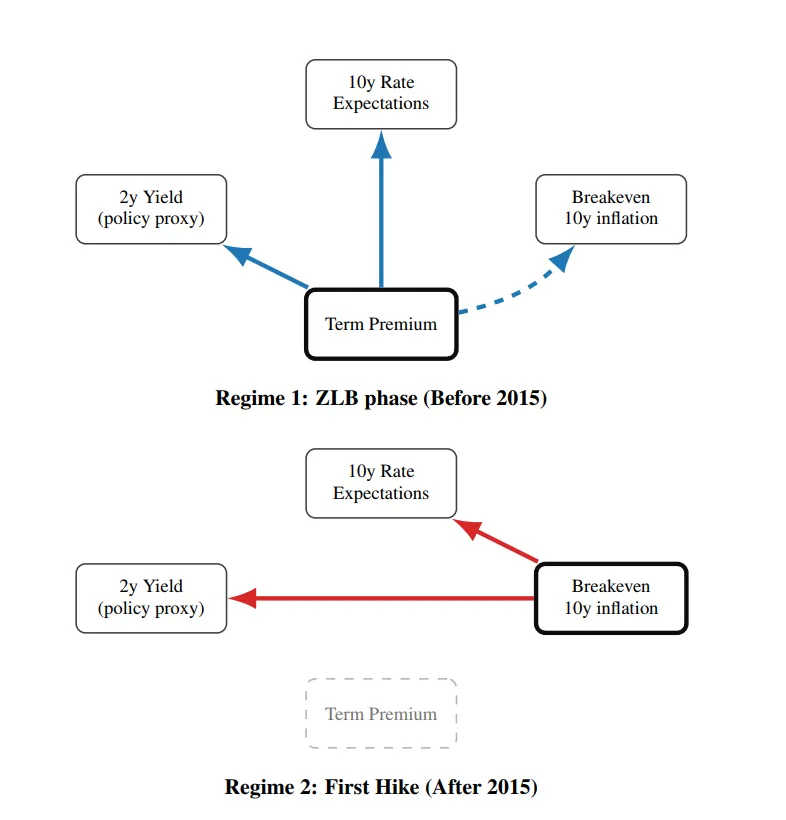
图1利率决议前后的因果关系网络:升息后,收益率、利差和波动率的关系网发生了质变(来源:论文 Figure 1)
先看一个硬伤。传统的制度转换检测方法,比如PELT、二元分割、Bai-Perron,它们的工作原理都是在搜索数据中突然的均值跳变或者方差变化。这个方法在检测金融危机、流动性冲击这些由市场自身驱动的拐点时效果不错。但在检测政策驱动的拐点时,问题就来了。
政策拐点有两个特点。第一,它是有预谋的。美联储不会今天早上起床突然决定加息,它在之前的会议纪要里反复释放信号。第二,它的数据信号往往是滞后的。12月16日加息,但收益率曲线可能需要几周甚至几个月才能充分反映新的加息路径。纯数据方法看到的是一个缓慢的偏移,不是一个瞬时的跳变,,而这正是结构断裂检测最怕的场景。
图1展示了这一点。美联储启动加息后,2年期、5年期、10年期收益率、期限溢价、信用利差之间的因果关系网络发生了质变。用论文的原话说:滞后的债券市场动态在货币政策制度边界两侧以质的方式不同。翻译成人话:同样的变量,加息前和加息后的互动模式完全不一样。但如果你只看数据不问文本,你根本不知道这个边界在哪。
二、四步流水线:文本说了算,数据来验货
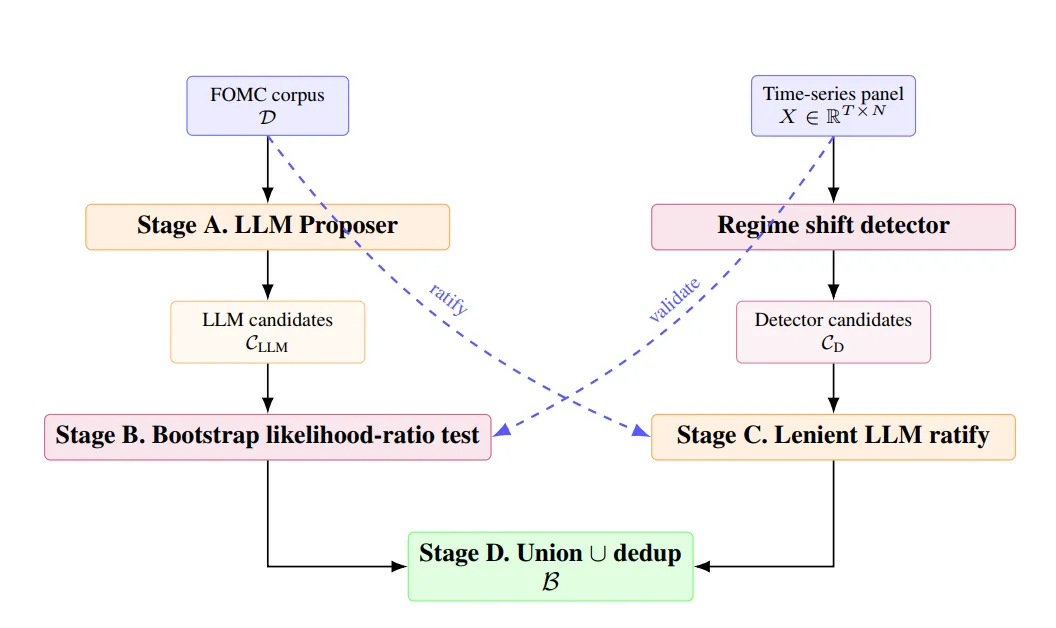
图2双向交叉验证流水线:LLM从文本提案→VAR统计验证→反过来数据检测器的候选也被LLM核验(来源:论文 Figure 2)
论文的核心设计是一个双向交叉验证流水线,一共四个阶段。奇哥用大白话翻译一下。

表1四阶段流水线概览
Stage A: LLM读文本。把FOMC会议纪要喂给Claude Sonnet 4.6(温度0.2),提示词很简单:判断这次会议前后是否发生了重大货币政策转向。注意,LLM只读会议纪要的文本,完全不看数据。输出是一个候选日期列表。
Stage B: 数据来验货。LLM说2015年12月拐了,但口说无凭。这一阶段取出12月前后的14个宏观变量(国债收益率、信用利差、MOVE波动率指数、CPI、失业率等),跑一个VAR自助法似然比检验。简单说就是:把这些变量拆成拐点前和拐点后两段,算它们的互动模式是否真的有结构性差异。用500次残差自助抽样,p值小于0.05才算通过。
Stage C: 反向验证。前面是文本说、数据验。这一层反过来:用四个不同的纯数据检测器(PELT、二分分割、Bai-Perron、PCMCI)各自独立扫描数据找候选拐点,然后把每个候选点丢给LLM,让它用一条更宽松的提示词检查:这两次FOMC会议前后,有没有任何实质性的货币政策内容?宽松提示词的设计非常关键。论文发现,如果用严格提示词(要求必须是重大转向),会丢掉两个重要拐点,2021年3月美联储点阵图首次显示2023年加息预期,和2023年3月硅谷银行危机期间的加息。宽松提示词保住了这两个锚点。
Stage D: 合并去重。文本通道的结果和数据通道的结果取并集,去掉重复的,输出最终拐点列表。
三、26个拐点,踩中了23个
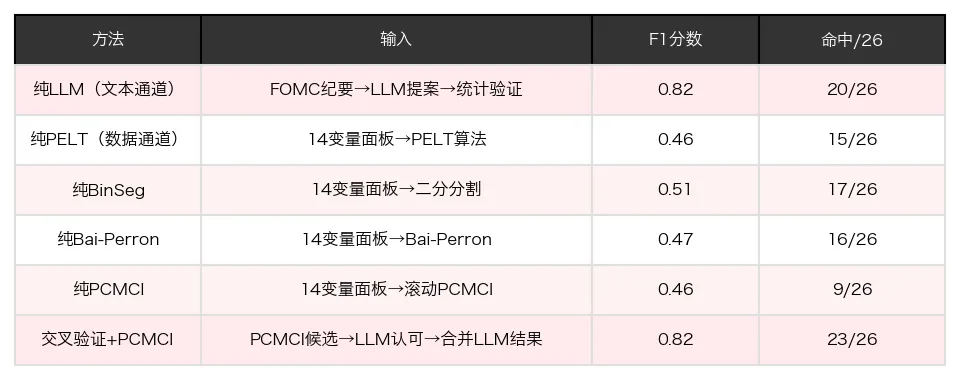
表2各方法F1分数对比:纯文本通道0.82,纯数据通道最高0.68,交叉验证+PCMCI达到0.82
表2是整篇论文最核心的数据。几个数字值得盯着看。
单独用LLM读文本,不靠任何数据支撑,F1就已经是0.82。26个锚点里踩中了20个。平均检测延迟只有+3天。大部分拐点,,2010年到2024年之间的量化宽松、加息、缩表、新冠紧急降息,,都是在FOMC公告当天就被抓到了。
单独用数据方法呢?PELT 0.46,BinSeg 0.51,Bai-Perron 0.47,PCMCI 0.46。没有一个超过0.68。差距将近20个百分点。
把两路合并之后,交叉验证+PCMCI达到了0.82,,和纯LLM持平,但比纯数据通道最高的0.68高出了14个百分点。PCMCI单独跑的时候只能打中9个锚点,加上LLM认可之后打中了23个。这个0.46到0.82的跨越,完全来自文本通道的贡献。
论文还特别分析了一个有趣的细节。纯LLM漏掉了6个拐点。其中两个,,2021年3月点阵图显示加息和2023年3月硅谷银行危机期间的加息,,并不发生在常规FOMC会议上,而是散落在会议之间的经济预测摘要和危机应对声明中。数据通道在这两个点上捡到了。这意味着文本和数据并不是冗余的,它们是互补的。文本擅长抓有预谋、有公告的政策拐点,数据擅长抓散落在非正式文件中、隐藏在价格波动中的异常。两者结合的效果超过了各自单独。
四、最诚实的地方:这篇论文没有硬吹LLM
奇哥特别喜欢这篇论文的一个品质:它非常清楚自己用了LLM的什么能力,也清楚LLM在这里不是万能的。
LLM在Stage A里做的事其实很简单:读文本,输出一个判断。没有多轮推理,没有Agent调用工具,没有RAG检索外部知识。就是Anthropic Claude Sonnet 4.6,temperature 0.2,一条提示词。论文作者对此毫不遮掩,甚至把提示词全文放在了图3和图4里。
那为什么效果还这么好?因为LLM最擅长的一件事,恰好是制度转换检测最缺的东西,,从非结构化文本中提取高层语义判断。你不需要让LLM预测收益率,那太难了。你只需要让它回答一个问题:这篇会议纪要是鸽还是鹰?和上一篇相比有没有明显变化?这恰好是语言模型最舒服的工作区间。
论文的另一个诚实之处是,它的主要贡献声明不是我们超越了所有方法,而是我们把文本信号纳入了检测流程,并且证明这种纳入是稳健的。四个可互换的数据检测器在装上文本通道之后,F1全部超出了最强的纯数据基线。这说明文本的价值是通用的,不依赖于某个特定的检测算法。
项目代码也体现了这种诚实。整个仓库是零API,,所有LLM的判断结果都已经缓存好了,不需要任何API密钥也不需要联网,下载下来就能跑。Table1到Table4的复现脚本一共就四个Python文件,加上Figure 1的一个Jupyter Notebook。26个基准锚点单独存成了一个CSV文件,每一个都附带了从federalreserve.gov官网核实过的原始来源。
五、总结
回到开头那个问题。美联储2015年12月加息这件事,纯数据方法可能要到2016年2月才能确认这是一个制度拐点。但FOMC会议纪要在2015年10月就已经开始铺垫了。中间的三个月,就是信息差的价值。
这篇论文做对了两件事。第一,它没有试图让LLM做超出能力范围的事。不让LLM预测价格,只让它判断政策立场的文本信号。第二,它没有把希望全部押在LLM上。每一个LLM的判断都经过了统计检验的交叉验证。反过来,每一个数据检测器的发现也会反过来找文本证据。你说是,我要验。我说是,你也要验。
它的局限也很明显。LLM只用了Claude Sonnet 4.6一个模型,没有做模型之间的对比,不确定是否所有的LLM都有同等级别的FOMC纪要理解能力。锚点列表本身是由另一个LLM(GPT-5.5)提议、再由作者手动验证的,存在一定的主观性。另外,14个变量的面版虽然比单变量方法强,但仍然高度简化了真实的宏观环境。
但这不妨碍它给出一条清晰的方法论方向:金融领域有很多问题,数据只能告诉你一部分答案,文本里藏着另一部分。把两路拼在一起,比各自单干要好。这个框架不限于美联储,日本央行、欧央行、中国人民银行的会议纪要同样适用。也不限于货币政策,财报电话会、监管公告、信用评级报告,任何需要从非结构化文本中嗅出拐点的场景,都可以复用这个流水线。
