 夜雨聆风
夜雨聆风四年前,OpenAI亲手解散了机器人团队。四年后,他们开出200万年薪,在硅谷疯抢机器人工程师。
这事儿真真切切发生在上周,OpenAI一口气放出电气工程师、仿真环境工程师、执行器设计工程师、控制系统软件工程师四大核心岗位。同一时间,清华AIR一个开源项目UniLab,在Mac电脑上3分钟就把人形机器人训得满地跑。复旦系团队眸深智能,半年拿了5轮融资,3亿Pre-A轮被超额认购5倍。VAST更狠,一口气融了将近2亿美元,甩出全新世界模型路线Project Eden。
我问了身边几个做机器人的朋友,大家的反应出奇一致:机器人赛道不是在加速,是在起飞。
但问题是,OpenAI为什么要回来?当年不是自己说不玩了吗?为什么偏偏是现在?清华凭什么能在Mac上3分钟训好机器人,英伟达的显卡不香了?VAST和眸深各走各的技术路线,谁才是对的?
这篇文章,我试着理一理这几天密集发生的事,把这股物理AI的暗流翻到台面上来。

Dactyl:一段被遗忘的往事,一把被重新捡起的钥匙
回到2017年,OpenAI的Dactyl项目是什么水平?我说几个数字,大家感受一下:他们用强化学习训练一只五指仿生手(Shadow Hand),在仿真环境里跑了海量数据之后迁到真机,不光能转积木,还能单手解魔方。这放在今天看依然很牛。当时几乎定义了"仿真训练→真机落地"这条后来被Google DeepMind、特斯拉、Figure AI广泛采用的技术路线。
但2020年,他们把这个团队砍了。
理由很简单:机器人数据太少了,训练数据稀缺、迭代太慢。而互联网上有近乎无限的文本和代码。大模型路线的进展比机器人快了不止一个数量级。当时的逻辑无懈可击,事实证明也对,ChatGPT的成功让OpenAI成了当时全球最值钱的AI公司。
所以现在的问题是:为什么又回来了?
我翻了一下OpenAI这次放出来的招聘信息和团队成员的背景,有三件事值得特别关注。
第一,时机。2020年说不玩机器人的时候,特斯拉Optimus还没影,Figure AI还没成立。到今天,特斯拉Optimus量产脚步越来越近,弗里蒙特工厂产线已经备好;Figure AI拿了近17亿美元融资,完成超长时间连续运转零故障测试;Google DeepMind从没停过机器人基础模型的研发。对手已经把赛道跑出来了,OpenAI不能再等。
第二,人。过去一年,OpenAI机器人团队悄悄塞进了一批顶尖华人研究者。林星宇(北大/CMU博士),业内知名低成本遥操作框架GELLO和HumanoidBench评测基准的核心开发者;何泰然(上交/CMU博士,坐拥50万+粉丝的科技博主),Omni H2O人形全身协调操控技术就是他搞的;还有从Meta FAIR挖来的前SAM和Llama核心参研者张鹏川(清华数学博士),加上斯坦福、MIT、伯克利的一系列新晋PhD。这帮人的简历叠在一起,硅谷哪家公司都得眼红。
第三,组织变化。由Aditya Ramesh(DALL-E的创造者之一)带队的世界模拟研究项目,已经正式转型为OpenAI Robotics部门。这个机构重组的信号非常明确:OpenAI不打算只是"试试水",而是要"稳住做"。四大工程岗位覆盖底层电路板到整套控制系统全链路,这绝不是随便玩玩。
奥特曼在X上的表态也很直白:翻译的好听点儿就是"AI本就该走进物理世界,在真实世界中为人类提供助力。"
说白了,语言模型的牌打得差不多了,下一局在物理世界。
清华这手操作:Mac上3分钟训好人形机器人,直接把英伟达的卡给解绑了
就在OpenAI发招聘的同一周,清华AIR DISCOVER Lab联合上交、创智学院等机构,开源了一个叫UniLab的东西。
这玩意儿做了什么事呢?一句话:把机器人强化学习训练从"必须绑在英伟达显卡上"的潜规则里解放了出来。
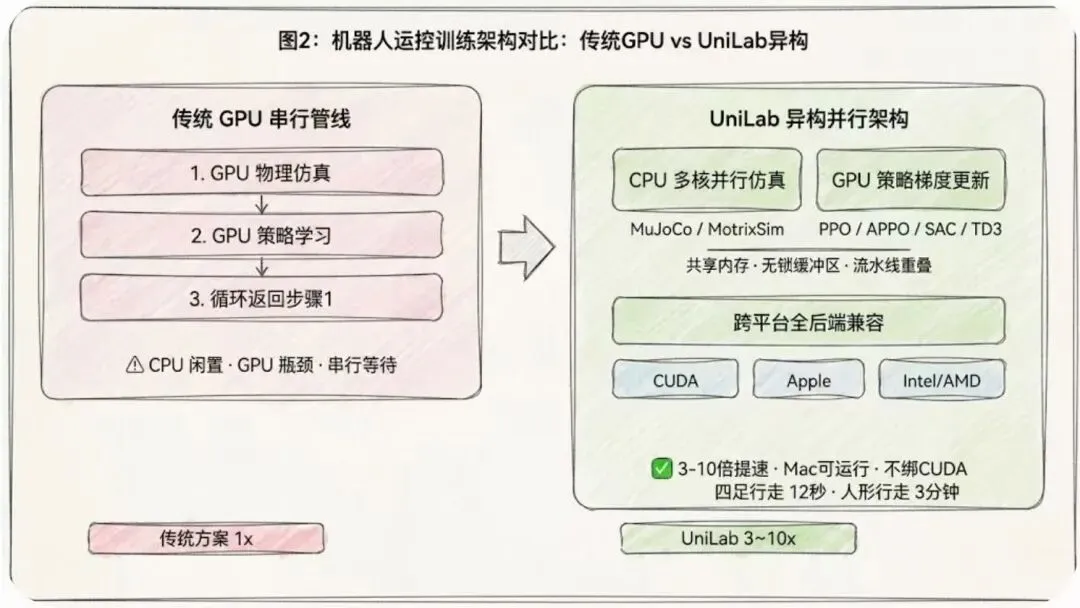
也就是说,以前的机器人训练有一条不成文的规定:物理仿真跑在GPU上,策略学习也跑在GPU上。GPU干完这步才能干下一步,串行执行,CPU一边凉快去。CPU多核算力就在那白等着,跟开着法拉利送外卖差不多(啊哈哈)。
UniLab的做法很粗暴:CPU专门跑物理仿真(利用多核并行),GPU专门跑神经网络策略学习。两边同时干活,通过共享内存做无锁数据交换。当GPU在跑当前批次的梯度更新时,CPU已经异步跑完了下一轮的环境仿真。这就把原来的"一方干、一方看"变成了"双方一起跑"。
在我的RTX 4090 + AMD 9950X 3D机器上,UniLab训一个四足机器人走路只花了12秒,训一个人形机器人G1学会走路只用了3分钟。同样的硬件上传统方案至少要半小时起。速度提升是3到10倍。
但真正让我觉得有意思的是另一个细节:UniLab去掉了对CUDA的硬编码依赖。它原生支持CUDA、Apple Silicon、AMD、Intel全后端。我在MacBook Pro上本地就能训人形机器人。不需要NVIDIA显卡,不需要租云GPU,不需要配驱动。一个M2芯片的MacBook,借助统一内存架构的低延迟特性,CPU仿真和GPU学习的传输开销比NVIDIA平台还小,因为不用过PCIe总线。
这说明什么?说明机器人的核心技术门槛正在被一层一层地剥掉。以前说"训机器人得要一堆A100",现在开源代码跑起来3分钟出结果。以前说"没有NVIDIA生态就别碰机器人",现在Mac上就能干。
团队说已经把这个系统在6类真机任务上完成了闭环验证——四足行走、人形全身运动(含翻跟头、攀爬)、灵巧手操作。论文挂在arXiv上,代码GitHub完全开源。
这事的影响可能比表面上大得多:训练门槛的降低,意味着更多课题组、更多创业者能进入这个赛道。卷的人越多,迭代速度越快。机器人产业的"chatGPT时刻",可能不远了。
世界模型的路线之争:到底什么叫"机器人的大脑"?
把话说大一点,机器人能不能干活,不只是一个电机和控制的问题,更深层的是:它怎么理解自己所在的这个世界。
这就引出了这两年AI领域最热也最模糊的概念之一,世界模型。
先别被这个词吓到。我给你一个最通俗的理解:你坐在沙发上,闭上眼,脑子里能"看见"茶几在哪、茶杯在茶几上、小猫在窗台上。你还能"推演"——如果现在站起来走过去,猫可能会跳走。这就是你的大脑在做的事:维护一个对周围世界的内部模型,并且随着时间的推进不断更新它。
机器人差就差在这一步。今天大部分机器人"看"到一个画面→"做出"一个动作,中间缺了"理解"和"推演"。这就是世界模型要解决的问题。
而现在,这个领域的技术路线分裂得很有意思。
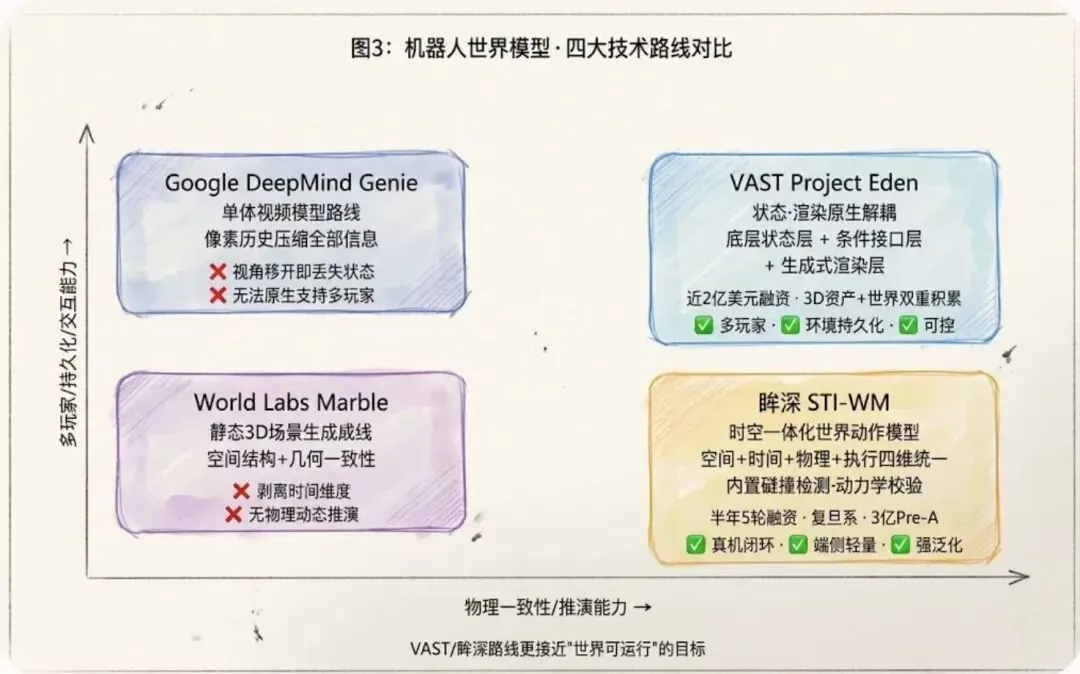
第一条路:Google DeepMind的Genie——"单体视频模型"。把空间、世界、交互、视角所有信息全部压缩进像素历史里,靠一段视频往前推。问题是镜头一转,模型就不知道之前那个地方发生什么了——缺乏独立的状态概念。你想搞多玩家在线互动?架构上几乎不可能。
第二条路:李飞飞的World Labs Marble——"静态3D场景"。强调空间结构和几何一致性,从一张图片就能生成持久的3D世界。但它剥离了时间维度和物理运行动态,你看到的世界很美、很准,但它不动、不演化。我认为这是一张"世界快照",不是"世界模拟"。
第三条路:VAST的Project Eden——"状态与渲染解耦"。这个思路比较底层:把"世界处于什么状态"和"状态长什么样子"彻底分开。底层维护一个跨时间存在的全局状态(物体在哪、门是开是关、灭火器喷了没有),它独立于任何相机视角。上层拿到状态约束之后再专心渲染画面。好处是状态和渲染各干各的,不会互相拖累。算一个物理变化不用同时操心"画面帅不帅",反过来渲染的时候也知道"位置不会错"。
VAST的首席科学家曹炎培举过一个例子:假设玩家按下灭火器,在一个紧凑的状态空间里推理"灭火器粉末喷出去了没有"这件事,给定足够的数据并不难。但如果让同一个模型既要推理物理状态、又要生成逼真的画面,两件事一起考,模型的负担指数级增加。
这个架构最大的工程红利是,多人在线世界在架构层面第一次成立了。底层状态被所有人共享同步推演,系统只需根据每个人各自的坐标分别渲染画面,算力成本是线性可控的,而不是像单体视频模型那样随人数指数爆炸。
第四条路:眸深智能的STI-WM,"时空一体化世界动作模型"。这是复旦系团队的路线。他们不觉得状态和渲染应该解耦,而是走了一条更"机器人原生"的路:空间结构、时间演化、物理一致性、执行鲁棒性四维一体化。底层基于点云直接还原三维物理空间,内嵌碰撞检测和动力学校验,上层输出全局轨迹规划和精细化动作。从"看懂世界"到"推演未来"到"规划动作"再到"执行纠错",要做成一个完整闭环。
这四条路,没有谁对谁错,因为现在还太早期了。但我注意到两个很有意思的共同点:
第一,都在强调"物理一致性"而非"视觉逼真度"。没人再说"我们要生成以假乱真的视频",那是过去的话题。今年所有人都在谈"碰撞检测""动力学校验""物理约束",因为真机落地的时候,画面像不像不重要,动作会不会把东西撞倒才重要。
第二,资本对这条路线极度看好。VAST拿了近2亿美元,眸深半年5轮融资、Pre-A获5倍超额认购,还有复旦系另外一支团队(新智具身)天使轮拿了近亿。整个具身智能赛道的融资正在从"投硬件"转向"投大脑"。
你以为的瓶颈不是你以为的那个瓶颈
聊到这,我想说一个可能和大家直觉相反的点。
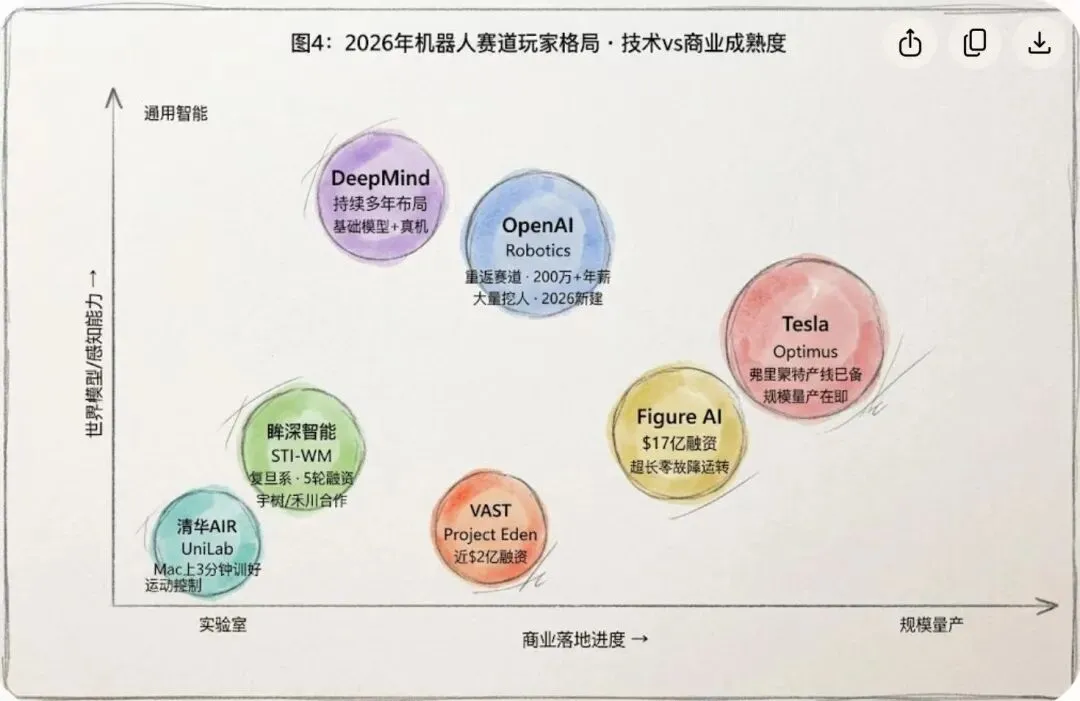
绝大多数人以为机器人的瓶颈是硬件。电机不够强、电池不够久、关节不够灵活。但如果你把这几天的新闻串起来看,你会发现一个完全不同的故事:OpenAI重返机器人抢的不是机械工程师,是"世界模拟"和"学习算法"方向的顶级研究者;清华UniLab在做的,不是更好的电机控制器,而是更好的强化学习训练框架;VAST融了近2亿美元做的,也不是机器人硬件,而是"世界底座",一个能让机器人理解物理世界的底层基础设施。
换句话说,机器人产业已经从"硬件军备竞赛"进入了"软件/智能军备竞赛"。
这就像2007年的手机行业。诺基亚把硬件做到了极致,键盘、摄像头、电池、信号,样样都是顶配。但iPhone做的事情是"重新定义人和设备的交互方式"。它的核心不是更好的硬件,而是多点触控+操作系统+应用商店这套软件生态。后来的故事大家都知道了。
机器人现在就在这个拐点上。机械臂、电机、传感器这些硬件已经够用了(宇树的四足机器人能后空翻,够不够用?),瓶颈转移到了"机器人的大脑"——它能不能理解一个杯子摔在地上会碎,能不能推理"先开门再进去"这个顺序,能不能在它看到一个从未见过的场景时做出合理的判断。
而这个问题,恰恰是AI模型,尤其是大语言模型和世界模型——真正擅长的。这也是为什么OpenAI、Google DeepMind这些AI公司突然都冲进来了。机器人不再是"机械工程问题",而是"AI问题"。
但也没那么简单,那些还没公开说的"坑"
别误会,我写这些不是说"机器人马上要取代人类了"。
第一,数据问题根本没解决。语言模型有互联网上近乎无限的文本和代码可以训练。机器人呢?真实物理世界的交互数据少得可怜,而且采集成本极高。这就是为什么图灵奖得主Yann LeCun坚持认为"纯靠大语言模型路线走不到通用机器人",缺乏真实物理世界的反馈闭环。VAST的策略是用AI Agent在游戏引擎里7×24小时自动探索来生成合成训练数据,但这个方案能覆盖真实世界的复杂程度吗?存疑。
第二,仿真到真机的迁移鸿沟。你可以在仿真里让机器人翻10000个跟头不受伤,但一旦上了真机,传感器噪声、关节磨损、地面摩擦系数的微小变化,全都会让训练成果大打折扣。清华UniLab做了6类真机任务的闭环验证,这是个很好的开始,但这6类任务离"走向千家万户"还差着十万八千里。
第三,商业闭环在哪里?目前人形机器人的BOM成本动辄几十万到上百万人民币。工厂里一个AGV小车几万块就能24小时不休息地干活,你让一台百万人形机器人替代它,老板的ROI怎么算?除非——除非它能做AGV做不了的事,比如精细装配、居家护理、灾难救援。但这些场景的技术成熟度,又回到了第一点和第二点的问题。
说白了:大家都在抢跑,但终点线在哪、要跑多长,没人知道。
最后的最后
我写这篇文章的时候一直在想一个问题:OpenAI为什么偏偏选现在?
我的判断是——这不是一个"现在到了最好时机"的选择,而是一个"再不入场就来不及了"的选择。
特斯拉Optimus已经在弗里蒙特工厂里跑了,Figure AI的机器人能连续运转好几个小时不故障,DeepMind积攒了多年的机器人基础模型有了系统性的突破。国内这边,清华UniLab把训练速度提了10倍,科大讯飞、宇树、眸深等一大堆玩家在用更低的成本、更快的速度往前推。VAST的3D生成能力已经把产业管道打通了一半。
OpenAI最大的优势是什么?是他们在语言和多模态模型上积累的能力——把文本理解和视觉感知迁移到物理世界的"大脑"上。如果这条路能走通,OpenAI依然有机会定义下一代机器人智能。如果走不通,那他们至少得坐上牌桌。
所以你看,奥特曼说的"AI就该走进物理世界",听着像理想主义宣言,背后其实是个残酷的竞争倒计时。
我最后问自己一个开放性的问题,也抛给你:如果5年后回头看今天,我们会不会觉得"2026年6月"就是那个机器人产业的ChatGPT时刻?
或者反过来,我们会不会发现,这不过是又一轮泡沫,真正的爆发还在十年之后?
我不确定。但我确定的是:不要只盯着大语言模型了。物理世界的战场,比你想的更热闹。
引用来源
量子位 — OpenAI重返机器人赛道!四大核心岗位开招 —https://www.qbitai.com/2026/06/427238.html 量子位 — 机器人运控训练步入分钟级时代!清华AIR开源UniLab —https://www.qbitai.com/2026/06/427729.html 量子位 — 近2亿美元!VAST完成新一轮融资,正式披露世界模型路线 —https://www.qbitai.com/2026/06/427516.html 量子位 — 机器人原生世界动作模型问世!首创时空一体架构,复旦系团队出品 —https://www.qbitai.com/2026/05/426984.html UniLab 论文 —https://arxiv.org/abs/2605.30313 UniLab 开源代码 —https://github.com/unilabsim/UniLab Sam Altman X帖子 —https://x.com/sama/status/2061117302528188712 Nathan Lambert / Interconnects —Open and closed models on different exponentials —https://www.interconnects.ai/p/open-and-closed-models-are-on-different
