 夜雨聆风
夜雨聆风论文原文标题:
Thinking in Blender: Staged Executable Inverse Graphics with Vision-Language Models
今日一句话:这篇论文最值得看的,不是“AI 也能做 3D”这句空话,而是它把单张图片还原成可编辑 Blender 程序,直接打通了新视角、改物体和换灯光三件事。


图注:原文 Figure 1 直接把单图输入、Blender 代码、novel view、editing、relighting 串成一条可传播的故事线。
为什么这篇值得点开?
这两年讲 AI 生成 3D 的内容很多。
但大部分讨论,最后都会停在两个方向:
生成一个网格、NeRF 或 latent 表示; 做一个能看但不太能改的结果。
问题是,普通读者真正能理解技术价值的,不是“它能不能重建 3D”,而是:
它重建完之后,能不能继续当成一个正常 3D 项目去改。
这篇 Thinking in Blender: Staged Executable Inverse Graphics with Vision-Language Models 的切口就非常适合传播。
它不是在说“我训了一个更强的 3D 模型”,而是在问:
如果我只给你一张图,预训练 VLM 能不能直接写出一份 Blender 场景程序,让这个场景后续还能继续改、继续打光、继续换视角?
这和很多只能“生成一张差不多的图”或“吐出一份不太可控的 3D 表示”的方法,完全不是一回事。
因为 Blender 代码一旦成立,后面的操作就不再只是论文指标,而是标准图形学工作流:
换镜头 改材质 调布局 重新打光 甚至继续做物理模拟
这也是它最容易引发讨论的地方:
AI 不只是会看图说话了,而是开始把图翻译成可以执行、可以编辑、可以复用的 3D 工程对象。
这篇论文解决什么问题?
逆向图形学这件事,说白了就是:
给你一张图,反推出这个场景的几何、材质、布局和光照。
这件事很老,也一直很难。
因为单张图片天然是欠约束的。你只能看到一个视角,却要猜出背后的完整三维结构。
过去常见的路线,往往依赖这些东西:
专门的 2D / 3D foundation model differentiable rendering 多视图监督 针对某个几何表示的专门优化
这篇论文故意换了一条更“Agent 化”的路:
不专门训一个 3D 模型,而是让现成的预训练 VLM,直接在 Blender 代码空间里一步步写场景。
这里的关键,不只是“写代码”。
更关键的是,作者认为当前 VLM 不是完全不会做 3D,而是如果你让它一次性同时搞定几何、材质、构图、光照,它会在一个过于纠缠的问题里一起出错。
所以他们把整个任务拆开,让模型别再一口气做完,而是像一个真的 3D 艺术家那样,按阶段推进:
先搭粗结构 再修几何 再补材质 再调布局 最后调灯光
这就是论文里的 SEIG,全称 Staged Executable Inverse Graphics。
核心技术是什么?
这篇论文最值得拆的,是它把“图到 3D”变成了一个 staged generator-verifier loop。
1. 先做初始化,不直接追最终答案
方法一开始不是硬解一个唯一场景,而是先采样 4 个粗糙 scene rollout。
然后通过 selector 选一个更合适的起点,顺手给场景里的对象和部件打上 scene graph 标签。
这个 scene graph 后面会贯穿整个流程。
它的作用很现实:
如果你连“杯子”和“杯托”都没分清楚,后面谈材质和构图基本都没法收敛。
2. 四个阶段顺序细化,而不是一锅炖
论文把后续 refinement 拆成四段:
Geometry Refinement Material Refinement Composition Refinement Lighting Refinement
这四段并不是形式主义拆分。
它们分别只处理一类问题。
比如 geometry 阶段负责物体轮廓、部件层级、空间结构; material 阶段再去碰 PBR 材质、roughness、specular、纹理; composition 阶段只改相对位置、尺度、旋转和镜头布局; lighting 阶段最后才动光源类型、位置、强度、色温和曝光。
这种拆法的好处是:
每一步的错误面变窄了。
模型不用再在“我到底是该改物体形状,还是该改光照”之间来回打架。
3. 每个阶段都不是只生成一次,而是生成器 + 验证器反复迭代
这篇论文不是简单的 stage-by-stage prompt chaining。
它更像一个小型 agent loop:
generator 写 Blender 代码 执行代码并渲染结果 verifier 对照参考图检查差异 再把待修问题喂回下一轮
作者明确写了每一段的回合预算:
geometry 5 轮 material 3 轮 composition 3 轮 lighting 2 轮
如果预算耗尽还没完全满足 checklist,verifier 也必须在现有结果里选一个“最能往前走”的版本,而不是死循环。
这点很工程化。
它说明作者已经意识到:让模型一直自我批改,不一定越改越好,反而可能被上下文拖垮。
4. 产物不是隐含表示,而是可执行 Blender 程序
这是整篇论文最值得传播的一句人话:
它输出的不是一个黑盒 latent,而是一份 Blender scene program。
这意味着很多下游能力不是额外训练出来的,而是自然继承自 Blender 这个宿主:
novel-view synthesis object editing relighting rearrangement
只要几何、材质、灯光是分开存的,你就能直接重排、换灯,不用重新跑整条重建链。
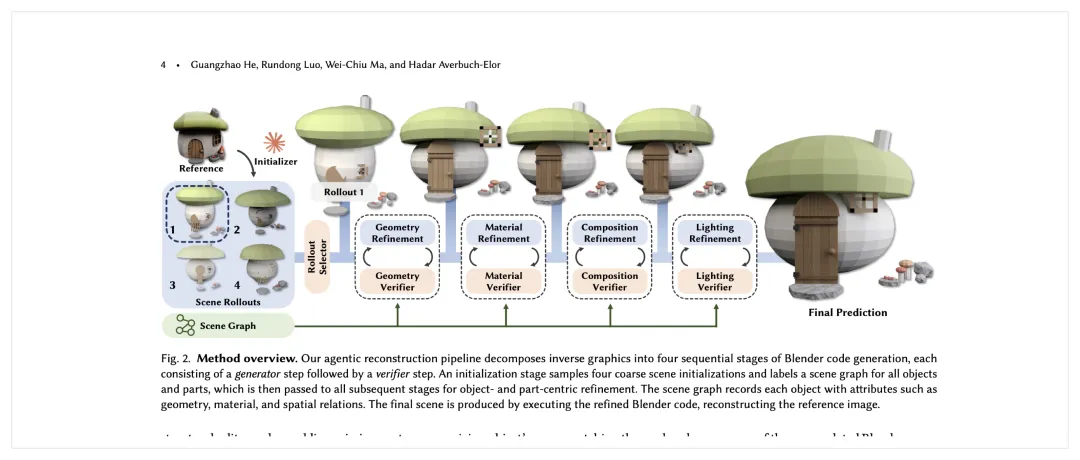
图注:原文 Figure 2 是全篇最重要的一张图,清楚展示了 initializer、scene graph、四段 refinement 和 verifier 闭环。
它比已有方法强在哪里?
这篇论文没有把自己包装成“全面碾压一切 3D 方法”。
它的对比更聚焦:
和 VIGA 这条可执行 inverse graphics 路线相比,单靠更好的流程设计,能不能把结果再往上推。
作者刻意控制了一个很重要的变量:
实验里 generator 和 verifier 都基于同一个基础 VLM,文中写的是 Claude Opus 4.7,而且 没有做额外微调。
这意味着结果差异主要来自 harness design,而不是换了一个更强的专门模型。
论文第 5 页两组表最值得记。
NeRF synthetic scenes
作者报告:
VIGA VLM-only的 PSNR 是 12.33VIGA full是 11.18Ours提到 13.58
同时在 LPIPS、DreamSim、DINO、CLIP 这些指标上,作者的方法也拿到最好或更稳的结果。
其中一个很有传播性的点是:
不用专门 2D / 3D foundation model,反而还能压过用了外部 3D 工具链的版本。
Edit3D
第二张表里:
VIGA VLM-only的 PSNR 是 11.52VIGA full是 12.48Ours是 12.65
DreamSim 也从 0.3847 / 0.4441 降到 0.3433,语义相似度的 DINO 和 CLIP 也更高。
作者给出的解释也很明确:
当前 agentic 3D pipeline 的主要瓶颈,不一定是“有没有更多外部工具”,而更可能是 视觉精度和分阶段控制能力。
换句话说,这篇论文最有启发的一点不是“VLM 什么都能替代”,而是:
当问题拆分得足够对,通用模型也能在复杂图形任务里做出比预想更强的工程结果。
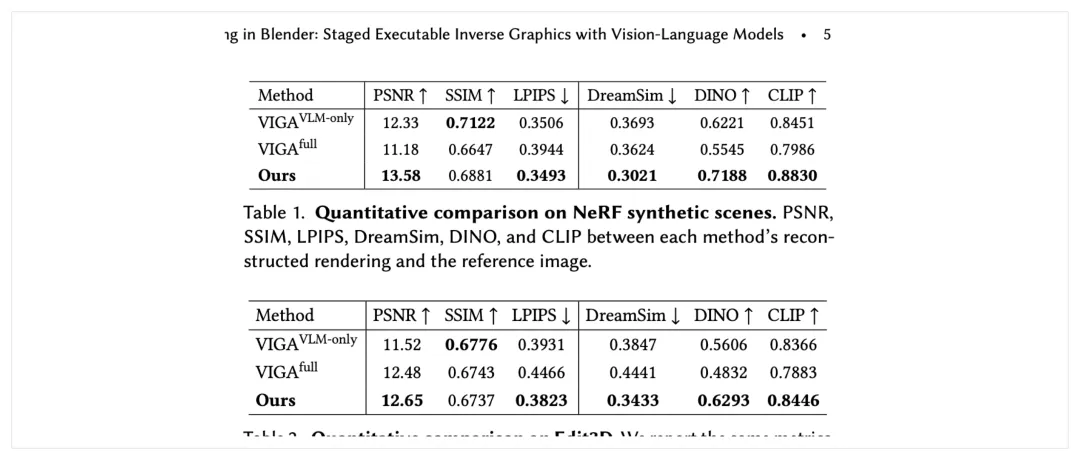
图注:右上两张表是最硬的证据区,NeRF synthetic 和 Edit3D 两组都能看到 staged pipeline 的增益。
它为什么容易传播?
因为这篇论文不是只给技术人看的。
它天然带一个特别适合社交传播的钩子:
“AI 现在不只是会画图,而是开始会写 Blender 场景。”
普通读者即使不懂 inverse graphics,也能立刻理解几个结果:
以后单图转 3D 的门槛可能会继续下降 场景一旦变成 Blender 代码,就有更强的后编辑能力 多视角、调灯光、改布局,不再一定要重做整套资产
更关键的是,论文在应用页把这件事讲得很直观。
你能直接看到:
同一个场景被换了新视角 同一个场景被重新打光 同一个物体被重排位置 中间阶段的结果还能被单独检查
这比很多只报一个 benchmark 分数的论文更容易让人形成“哦,这东西已经能拿来当工作流组件看了”的直觉。

能不能复现?
复现状态:D 级。
这不是说论文不值得看,而是要把边界说清楚。
截至我这次整理发布包时,公开一手来源里能确认到的是论文 PDF 和作者官方个人主页摘要,但没有看到公开代码仓库、权重、可运行 demo 或 Blender 工程模板链接。
我这次能做的“验证”,主要是事实层核验,而不是端到端复现。
已验证
arXiv 官方页面可访问,论文编号 2606.02580官方 PDF 可下载 论文明确写出方法结构、四段 refinement 和回合预算 论文明确写出实验 backbone 使用 Claude Opus 4.7,且未做额外微调 作者官方主页已挂出该论文条目,并描述为从单张图渐进式重建 Blender scene code 的 agentic framework
目前不能验证的部分
没有公开仓库,无法检查 prompt、tool wrapper、verifier checklist 和 Blender 执行细节 没有公开 benchmark 运行脚本,无法直接复跑表 1 和表 2 没有公开 scene assets 或生成脚本,无法核验 novel view / relighting 的具体实现细节 文中使用的底座 VLM 是商业闭源模型,成本和 API 状态会影响可复现性
这类论文现在该怎么看?
如果你是研究者,这篇值得看的点是方法分解思路; 如果你是做产品或 workflow 的,这篇值得看的点是:
图片输入以后,是否应该尽早转成“可编辑宿主格式”,而不是一直停留在黑盒视觉表示。
不能写过头的地方
第一,这不是“AI 已经能自动替代专业 3D 艺术家”。
论文展示的是一条很有启发的研究路线,不是成熟商用生产线。
第二,这篇论文的实验范围仍然有限。
它证明 staged executable inverse graphics 在给定对比里有效,但不能直接外推到任意复杂真实场景。
第三,论文结果不等于“任何 VLM 都能复现”。
文中明确使用的是 Claude Opus 4.7,而且大量效果依赖 generator-verifier loop 的具体设计。
第四,没有公开代码,就不能把本次整理写成“已成功复现”。
现在更准确的表述是:
这是一篇方法很新、传播很强、但开源复现条件还没跟上的新论文。
今天的判断
如果你在看 AI + 3D、design agent、scene editing 或图形学工作流,这篇论文真正值得记住的一句判断是:
单张图转 3D 的下一个竞争点,可能不只是“重建得像不像”,而是谁能最快把结果变成可编辑、可复用、可执行的宿主代码。
来源链接
论文:https://arxiv.org/abs/2606.02580 PDF:https://arxiv.org/pdf/2606.02580.pdf 作者官方主页:https://www.guangzhaohe.com/
