 夜雨聆风
夜雨聆风 前两篇,一篇画了数据流全貌,一篇钻了EKF2。数据怎么流转的清楚了,大脑怎么工作的清楚了,但有一个东西我一直跳过了——数据是怎么从一个模块飞到另一个模块的。
前两篇,一篇画了数据流全貌,一篇钻了EKF2。数据怎么流转的清楚了,大脑怎么工作的清楚了,但有一个东西我一直跳过了——数据是怎么从一个模块飞到另一个模块的。
GPS数据怎么到的EKF2?EKF2的姿态估计怎么到的控制器?控制器的输出怎么到的执行器?
答案就三个字母:uORB。
uORB是PX4的消息总线。PX4里所有模块间的通信,100%通过uORB完成。没有共享内存,没有函数回调,没有直接调用。发布者往uORB里扔数据,订阅者从uORB里取数据,双方互相不知道对方是谁。
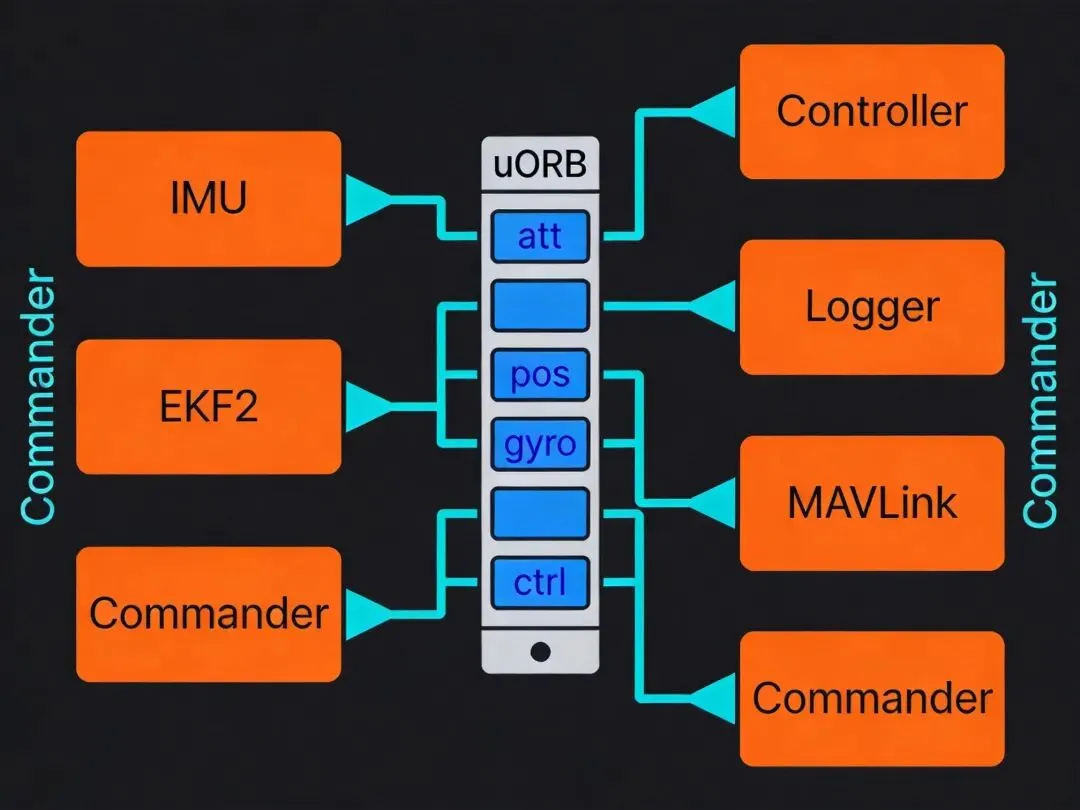
这个设计让PX4的模块可以独立开发、独立测试、独立替换。但它也让调试变得困难——数据流是隐式的,看代码调用链找不到数据流向,必须看uORB的订阅关系。
这篇拆uORB的内部机制:它怎么做到零拷贝,怎么处理多订阅者,怎么管理消息的生命周期,以及那些藏在原子操作里的性能代价。
uORB不是消息队列
最常见的误解:uORB是一个消息队列,发布者往里塞消息,订阅者从队列头取消息,先进先出。
不是。
uORB是一个多播订阅系统。每个"主题"(topic)在内存里只有一份实例。发布者写数据时直接覆盖这个实例。订阅者读取时直接读这个实例的内存地址。
┌──────────┐ write ┌──────────────┐ read ┌──────────┐
│ Publisher │ ──────────► │ Topic Instance │ ──────────► │Subscriber│
└──────────┘ └──────────────┘ └──────────┘
│ │
read │ │ read
▼ ▼
┌────────┐ ┌────────┐
│Sub B │ │Sub C │
└────────┘ └────────┘
没有队列,没有缓冲(默认情况下),没有排队。发布一次,所有订阅者共享同一块内存。这是uORB零拷贝的基础——数据不复制,只传递指针。
但这带来一个后果:如果订阅者没来得及读,下一次发布就覆盖了。 发布者不会等你。这就是为什么uORB的文档说"uORB提供的是最新值,不是历史值"。
主题注册:编译期确定的元数据
uORB的主题不是运行时动态创建的。每个主题在编译时通过ORB_DEFINE宏注册,元数据存在Flash里:
// src/modules/ekf2/ekf2_main.cpp
ORB_DEFINE(vehicle_attitude, struct vehicle_attitude_s);
// 展开后实际上是:
conststructorb_metadata __orb_vehicle_attitude = {
.o_size = sizeof(struct vehicle_attitude_s), // 消息大小
.o_name = "vehicle_attitude", // 主题名
};
orb_metadata结构只有两个字段:消息大小和主题名。没有队列长度、没有订阅者数量、没有QoS策略——这些uORB都不关心。
主题名是字符串,但它在编译时就确定了,运行时不会变。PX4用主题名做唯一标识,所以命名有严格的层级结构:
vehicle_attitude — 姿态
vehicle_local_position — 本地位置
sensor_gyro — 陀螺仪原始数据
sensor_combined — 融合后传感器数据
actuator_controls — 执行器控制量
vehicle_前缀是导航相关,sensor_前缀是传感器原始数据,actuator_前缀是执行器。这个命名规范让你看到主题名就知道数据属于哪个层级。
发布:不是你想的那么简单
发布一个主题分两步:声明(advertise)和发布(publish)。
// 声明:在uORB系统里注册自己为这个主题的发布者
orb_advert_t att_pub = orb_advertise(ORB_ID(vehicle_attitude));
// 发布:把数据写到主题实例
structvehicle_attitude_satt;
att.q[0] = 1.0f; // 四元数
att.q[1] = 0.0f;
att.q[2] = 0.0f;
att.q[3] = 0.0f;
orb_publish(ORB_ID(vehicle_attitude), att_pub, &att);
orb_advertise返回一个不透明的handle,后续发布用这个handle定位主题实例。为什么不让发布者直接持有主题指针?因为主题实例的内存位置在运行时才确定(它在堆上分配),编译时不知道。
orb_publish内部做了什么?
intorb_publish(const struct orb_metadata *meta, orb_advert_t handle, constvoid *data)
{
// 1. 找到主题实例
structorb_object *obj = (structorb_object *)handle;
// 2. 把数据复制到主题实例的内存
memcpy(obj->data, data, meta->o_size);
// 3. 递增版本号(原子操作)
atomic_fetch_add(&obj->generation, 1);
// 4. 通知所有订阅者(如果有等待队列)
for (int i = 0; i < obj->subscriber_count; i++) {
px4_sem_post(&obj->subscribers[i].sem);
}
return OK;
}
第四步通知订阅者,只在订阅者用orb_copy阻塞等待时才有意义。大多数情况下PX4的订阅者是轮询模式(poll),不走信号量。所以第四步经常是空操作。
关键的第二步:memcpy。等一下,不是说零拷贝吗?
"零拷贝"的真相
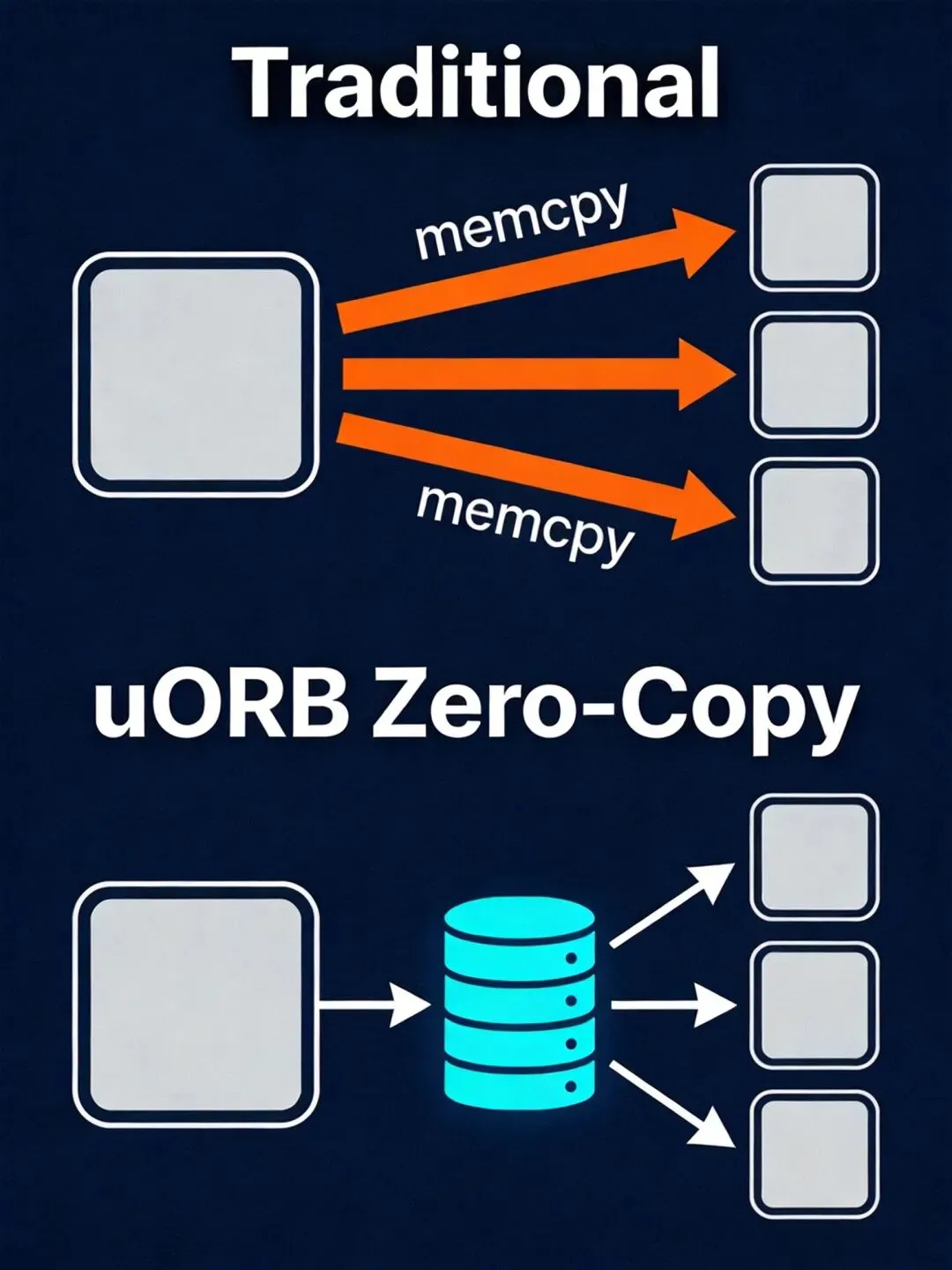
uORB的零拷贝不是"发布时不复制数据",而是"订阅者读取时不复制数据"。
发布者调orb_publish时,数据从发布者的栈/堆复制到uORB主题实例的堆内存——这次复制不可避免,因为发布者的数据可能随时释放。
零拷贝发生在订阅者这一侧。订阅者读取数据时,直接读主题实例的内存地址,不需要把数据再复制一份:
// 订阅者代码
int sub = orb_subscribe(ORB_ID(vehicle_attitude));
// 读取:直接拿到主题实例的指针,没有memcpy
structvehicle_attitude_satt;
orb_copy(ORB_ID(vehicle_attitude), sub, &att);
orb_copy内部:
intorb_copy(const struct orb_metadata *meta, int handle, void *buffer)
{
structorb_subscriber *sub = get_subscriber(handle);
structorb_object *obj = sub->object;
// 直接memcpy从主题实例到订阅者buffer
memcpy(buffer, obj->data, meta->o_size);
// 更新订阅者已读的版本号
sub->generation = obj->generation;
return OK;
}
等等,这里有memcpy——从主题实例复制到订阅者的buffer。这算哪门子零拷贝?
严格说,这不是零拷贝。uORB的"零拷贝"指的是:N个订阅者共享同一份主题实例内存,发布者只写一次,不需要为每个订阅者复制N份。 相比"发布者给每个订阅者发一份"的模式,复制量从N降到1。
但如果订阅者真想零拷贝(连那一次memcpy都省掉),PX4提供了orb_copy_nocopy接口:
// 真正的零拷贝:直接拿到主题实例的指针
constvoid *data_ptr;
orb_copy_nocopy(ORB_ID(vehicle_attitude), sub, &data_ptr);
// 直接读取,没有memcpy
conststructvehicle_attitude_s *att = (conststructvehicle_attitude_s *)data_ptr;
这个接口在PX4代码里很少使用。原因很简单:拿到的是主题实例的直接指针,如果发布者在读取过程中更新了数据,就会读到半新半旧的脏数据。uORB的memcpy虽然不是零拷贝,但保证了每次读取的原子性——memcpy的源地址不会被发布者并发修改吗?
会。这就是下一个问题。
原子性:uORB最大的坑
orb_publish里的memcpy和orb_copy里的memcpy不是原子的。两个线程可能同时操作同一块主题内存:
时间线:
Publisher线程 Subscriber线程
t1: memcpy 50%
t2: memcpy开始读
t3: 读到前半新+后半旧
t4: memcpy 100%
这是一个经典的数据竞争。在多核处理器上,两个线程真的可以同时执行,结果就是订阅者可能读到不一致的状态——四元数的前两个分量是旧的,后两个是新的。
PX4怎么处理这个问题?
没有处理。
这不是玩笑。uORB的设计哲学是:数据竞争的窗口极小(memcpy一个vehicle_attitude_s大约200ns),而PX4的传感器更新频率最高250Hz(4ms周期),冲突概率极低。即使冲突了,4ms后下一次发布就会覆盖,错误不会累积。
这对姿态和位置数据来说可以接受。但对某些数据结构就不行——比如一个包含"有效标志+数据"的结构体,如果标志更新了但数据没更新,订阅者会读到"数据有效但数据是旧的"这种逻辑错误。
实际代码里,PX4的解决办法是:把关键数据结构设计成冲突无害的。比如vehicle_attitude_s里的四元数,就算读到半新半旧,归一化后误差也在1e-3量级,一个控制周期后就被新值覆盖。而那些有标志位的结构体,标志位总是最后写,利用x86和ARM的store ordering保证读到的标志位对应的的数据至少是上一拍的。
这不是严格的并发安全,是工程上的务实妥协。
多实例:同一个主题,多路数据
有些传感器有多个实例。比如双IMU的飞机有两个陀螺仪,两个sensor_gyro主题实例怎么区分?
uORB用实例编号解决:
// 发布第一个陀螺仪
orb_advert_t gyro0 = orb_advertise_multi(ORB_ID(sensor_gyro), 0);
// 发布第二个陀螺仪
orb_advert_t gyro1 = orb_advertise_multi(ORB_ID(sensor_gyro), 1);
订阅时也指定实例编号:
int sub0 = orb_subscribe_multi(ORB_ID(sensor_gyro), 0);
int sub1 = orb_subscribe_multi(ORB_ID(sensor_gyro), 1);
多实例在uORB内部就是一个对象数组。sensor_gyro的实例0和实例1是两块独立的内存,各自有独立的generation计数器和订阅者列表。
但这里有个设计选择:优先级。sensor模块在融合多个IMU时,怎么知道用哪个实例?答案是不在uORB层解决——uORB只是传输管道,优先级选择是sensor模块自己的逻辑。上一篇EKF2里讲的选优策略,就发生在uORB之上。
Poll:订阅者的等待机制
订阅者怎么知道有新数据?两种方式:
1. 轮询(Poll)
structpollfdfds[2];
fds[0].fd = sub_att; // 姿态订阅
fds[0].events = POLLIN;
fds[1].fd = sub_status; // 状态订阅
fds[1].events = POLLIN;
// 阻塞等待,直到任一主题有新数据
int ret = poll(fds, 2, 1000); // 超时1秒
if (fds[0].revents & POLLIN) {
orb_copy(ORB_ID(vehicle_attitude), sub_att, &att);
}
if (fds[1].revents & POLLIN) {
orb_copy(ORB_ID(vehicle_status), sub_status, &status);
}
Poll的实现基于uORB的generation计数器。订阅者记住上次读取时的generation值,poll时检查当前generation是否大于上次——大于就说明有新数据。
2. 非阻塞检查
bool updated;
orb_check(sub_att, &updated);
if (updated) {
orb_copy(ORB_ID(vehicle_attitude), sub_att, &att);
}
orb_check也是检查generation,但不阻塞。适合高频轮询的场景。
PX4里大部分模块用poll模式,因为poll可以同时等多个主题,而且不消耗CPU。非阻塞检查只在极少数场景使用(比如启动阶段的初始化检查)。
Publication的生命周期
一个主题实例从创建到销毁的完整流程:
1. orb_advertise() → 分配主题内存,注册发布者
2. orb_publish() → 写数据,递增generation,通知订阅者
3. orb_publish() → 写数据,递增generation,通知订阅者
4. ... → 循环发布
5. orb_unadvertise() → 释放发布者handle,但主题内存不释放
注意第5步:orb_unadvertise只释放发布者handle,不释放主题内存。为什么?因为可能还有订阅者持有这个主题的引用。如果释放了内存,订阅者下次读取就会访问已释放的内存。
主题内存什么时候释放?答案是:永远不释放。uORB没有提供释放主题内存的接口。一旦一个主题被advertise过,它的内存就永久存在,直到进程退出。
这在嵌入式系统上不是大问题——PX4的主题数量是固定的(编译时确定),内存总量可控。但在PC仿真或SITL环境下,如果有模块反复advertise/unadvertise同一个主题,就会产生内存泄漏。实际上PX4没有这种使用模式,所以不是真实问题。
但也有一个隐患:主题的generation是uint8_t类型。255次发布后回绕到0。如果订阅者的上读generation恰好是254,发布两次后generation变成0,订阅者判断"0 < 254",认为没有新数据——这就是一个丢更新。
PX4处理回绕的方式是:generation比较用模运算。
boolorb_check_updated(int handle)
{
structorb_subscriber *sub = get_subscriber(handle);
// 模256比较:如果当前generation比上次读的大(模256意义下),就是有更新
return (sub->object->generation - sub->generation) > 0;
}
uint8_t的减法天然模256。只要发布间隔内订阅者至少检查一次(也就是不超过255次发布不检查),回绕就不是问题。PX4最高频率的主题是sensor_combined(250Hz),订阅者每个周期都检查,不存在255次不检查的情况。
性能:uORB到底多快
在STM32H743(480MHz)上实测:
publish和copy的耗时主要花在memcpy上。200字节的消息,memcpy在H7上大约200ns,加上generation递增和订阅者通知的开销,总共350ns。
一次控制循环(250Hz)里,EKF2大约发布3个主题(attitude + local_position + global_position),同时订阅6个主题。uORB的总开销大约是 3×350 + 6×300 = 2.85μs,占4ms周期的0.07%。可以忽略。
但如果消息很大呢?PX4最大的主题之一是camera_capture(含JPEG缩略图,可达4KB)。publish一次4KB消息,memcpy大约4μs。如果有10个订阅者同时orb_copy,总耗时40μs——仍然可以接受,但已经不是零了。
这就是uORB零拷贝的真正含义:不是没有拷贝,是拷贝次数不随订阅者数量线性增长。 publish拷贝一次,每个subscriber各自拷贝一次,总共N+1次。如果用传统消息队列给每个订阅者发一份,是N次publish拷贝。省的不是拷贝本身,是发布者侧的重复开销。
队列模式:uORB的扩展
前面说的都是uORB的默认模式——只保留最新值。但有些场景需要历史值。比如日志模块,如果发布频率高于日志写入速度,中间的数据就会丢失。
uORB v2增加了队列模式:
// 声明时指定队列深度
orb_advert_t pub = orb_advertise_queue(ORB_ID(sensor_gyro), 0, 10);
队列深度10,意味着最近10条消息都会保留。订阅者可以逐条读取,不会跳过中间值。
但队列模式有代价:
内存:10个实例的内存 = 消息大小 × 10。sensor_gyro大约100字节,队列模式占1KB。主题多了就不少。 拷贝:发布时需要判断队列是否满,满了要丢弃最旧的。这个判断逻辑比直接覆盖慢。 一致性:队列模式下,多个订阅者可能处于队列的不同位置。发布者写第10条时,快的订阅者已经在读第8条,慢的可能还在第3条。没有机制保证所有订阅者同步。
PX4里只有日志模块和MAVLink模块大量使用队列模式。控制相关的模块(EKF2、控制器)都用默认的"最新值"模式——控制只关心当前状态,不关心历史。
代码阅读路径
uORB的源码比EKF2好读得多,因为它的逻辑是线性的。建议按这个顺序:
uORB/uORB.h— 公共接口定义。orb_advertise、orb_publish、orb_subscribe、orb_copy的声明。先看这个文件,知道有哪些API。uORB/uORB.cpp— 核心实现。主题注册、内存分配、发布/订阅逻辑。600行左右,一口气能读完。uORB/Subscription.hpp— C++封装层。PX4推荐用这个类而不是裸API,代码更干净。重点看它的update()方法——它把orb_check + orb_copy封装成一次调用。uORB/Publication.hpp— 发布者的C++封装。RAII管理handle生命周期,析构时自动unadvertise。
如果只看一个文件,看uORB.cpp。600行,把uORB的核心逻辑讲完了。
和ROS Topic的对比
做过ROS的人可能会觉得uORB很像ROS的Topic——发布/订阅模型、主题名路由、多对多通信。确实,设计思想是一样的。但实现差异巨大:
uORB是单进程内的共享内存通信,零序列化,亚微秒延迟。ROS Topic是跨进程的网络通信,需要序列化,毫秒级延迟。
这个差异的本质是:PX4跑在单片机上,没有进程隔离,所有模块共享地址空间;ROS跑在Linux上,进程间需要序列化和网络传输。
uORB牺牲了灵活性和安全性(一个模块写越界可以破坏另一个模块的数据),换来了极致的低延迟和确定性。在飞控这个场景下,这个取舍是对的——1ms的通信延迟可能就是坠机和安全的区别。
小结
uORB的设计可以压缩成一句话:共享内存上的多播发布/订阅,只留最新值,不保证一致性,追求最低延迟。
核心机制:
主题实例只有一份内存,发布者写、所有订阅者共享读 零拷贝的真相是"发布者侧不重复拷贝",不是"全程无拷贝" 并发安全靠数据结构设计成冲突无害,不靠锁 generation计数器(uint8_t模256比较)驱动更新通知 队列模式是扩展功能,只有日志和MAVLink用 主题内存不释放,生命周期等于进程生命周期
uORB不是完美的消息系统。它不跨进程、不支持动态发现、并发安全性靠约定而不是机制。但它足够简单、足够快、足够可靠。在飞控这个场景里,这三条就够了。
代码基于PX4 v1.14,uORB模块路径:src/modules/uORB/
