 夜雨聆风
夜雨聆风
上一篇文章说到,AI 加速了每个环节的生产动作,但判断和验证的节奏没跟上:局部快不等于整体快。AI 产出的方案、代码、测试能不能直接用,靠的是工程判断,而这套判断能力到目前为止还是锁在人的大脑和口口相传的经验里。
问题在于,经验只存在于人脑里,就很难被 AI 稳定读取;判断只依赖个人经验,就很难在团队里规模化复用。要让 AI 真正参与工程链路,系统不能只提供工具入口,还必须把上下文、规则、验证和反馈组织起来。
于是,问题从“AI 能不能生成更多内容”,转向了“系统如何支撑工程判断的规模化运作”。
很多团队的第一反应,是搞一个更强的 Chat 入口:让 AI 能调更多工具、查更多数据、生成更多内容。
但这只是把 AI 的手变长了,并没有解决它能不能进生产的问题。真实软件工程不是问答系统,而是一个由权限、策略、审计、验证和回滚构成的控制体系。AI 能调用工具,与 AI 能安全参与工程链路之间,隔着一套必须被设计出来的控制结构。
你买的每一台云服务器都有 SSH,但没人会因为 SSH 很好用,就给一个刚入职的工程师 root 账号,让他随便改生产配置。问题从来不在于 SSH 能不能完成操作,而在于谁可以操作、在什么条件下操作、操作前要不要审批、操作后怎么审计、出问题怎么回滚。
AI 调工具也是一样。不是工具能力不够强,而是这些工具调用还没有被纳入一套可验证、可审计、可回滚的工程治理结构里。
三条链,一张图
既然问题不在工具能力,而在工程治理结构,那这套结构应该怎么组织?
它不能只是一个更强的 Chat 入口,也不能只是一个工具调用网关。要支撑 AI 参与真实工程链路,系统至少要完成三件事:先让 AI 看见真实工程现场,再让 AI 的建议经过验证和授权,最后把执行结果沉淀回组织经验。
我把它叫做 AI-Native Engineering Operating System。听起来有点大,拆开就是三条链:
第一条是认知链。人的业务目标、架构约束、审批规则是起点;系统把代码、运行拓扑、组织结构、历史变更这些信息聚合成一张全景图;AI 在这个上下文里理解意图、评估风险、推导方案。关键词是「理解现场」——不是猜,是看见。
第二条是治理链。AI 能生成方案,不代表方案可以直接执行。方案必须先进入工程流编排——是需求交付流、CI/CD 管道,还是故障响应流程——再通过独立的验证网关。这个网关要检查策略有没有被违反、影响半径有多大、SLO 会不会被烧穿、降级和回滚有没有准备好。CI/CD、Kubernetes 这些只是执行后端,不是 AI 可以绕过治理直接调用的入口。
第三条是反馈链。执行完了,事情还没有结束。实时观测数据——指标、链路、日志、业务影响——要回到上下文里,让系统看见这次变更的真实后果。事故复盘、架构演进、策略更新这些长期经验,要沉淀到架构记忆(Architecture Memory)里,成为下一次 AI 推理的输入。
三条链的核心原则就一句:AI 不直接连生产。它只能通过上下文聚合、工程流编排、独立验证、受控执行这几道关卡,才能进入真实的工程链路。
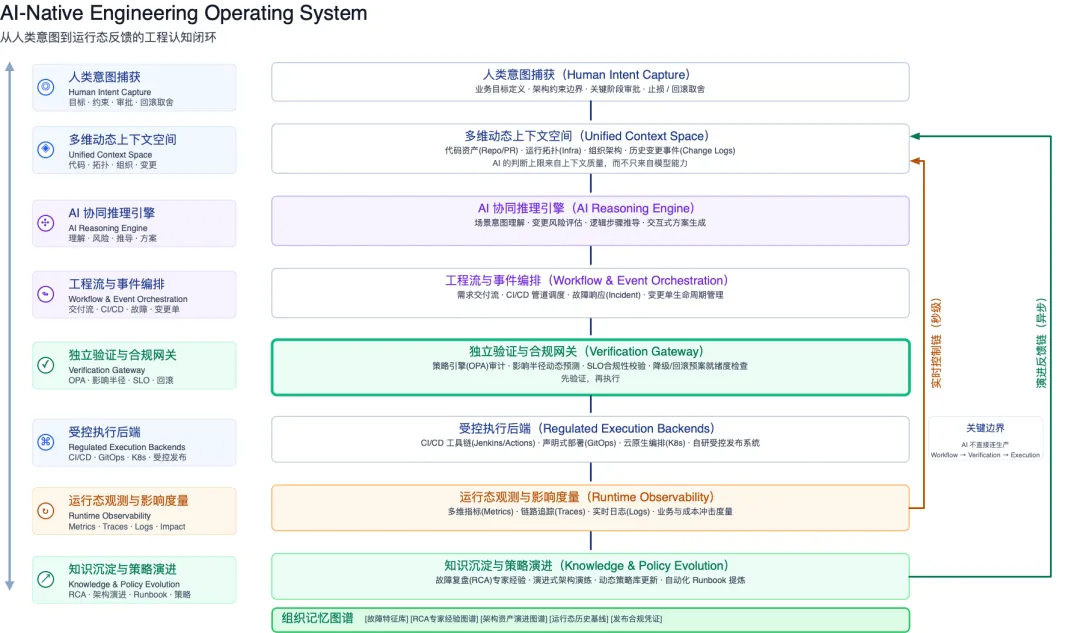
回到上一篇那个支付事故:一次连接池配置变更在灰度阶段引发 P99 飙升和支付超时。如果这次变更从一开始就被纳入这套 AI-Native OS,接受上下文、验证、审批和反馈机制的约束,后面的链路会完全不同。
认知链上,发布触发后,系统立刻聚合了四条信息:
•这次 commit 改了支付网关的连接池配置;•服务拓扑显示了受影响的上下游服务关系;•历史事件匹配到四个月前一次类似的连接池变更•那次也是灰度 10% 时 P99 飙升。 AI 不是等着人提问,而是主动关联这些信号,判定风险偏高,建议把灰度比例从 10% 降到 5%,延长观测窗口。
治理链上,这个建议没有直接执行。它先进入验证网关,策略引擎确认降灰度在允许范围内,审批闸门推送给值班 SRE 要求 5 分钟内确认,回滚预案被预加载,审计链记录完整的建议→验证→审批→执行路径。
反馈链上,降低灰度后,系统持续对比 5% 组和基线组的 P99、转化率、错误率。如果指标稳住了,扩大灰度;如果还在恶化,自动暂停并通知值班人员。同时,这次观测的全部数据——包括为什么暂停、什么条件触发,写入架构记忆。下一次同类发布,直接继承这次的经验。
三条链合在一起,不是「AI 替人做决策」,而是「AI 让决策有上下文、有约束、有证据、有记忆」。
四层结构,一道边界
三条链说的是系统层级的闭环——怎么理解现场、怎么治理动作、怎么沉淀反馈。它们回答了「AI-Native Engineering Operating System 如何运转」。但如果把镜头拉近到 Agent 这个执行单元本身,它怎么在安全边界内运转?这需要另一层结构。
落到具体执行层面,最关键的组件是 Agent Runtime:AI 真正跑起来的地方。现在 Demo Agent 已经展示出很强能力:读文件、查资料、调 API、生成代码,甚至自动提交变更。但真实工程现场关心的不是「能不能完成任务」,而是「能不能在安全边界内完成任务」。生产级 Agent 和 Demo Agent 的差别,不在它能调多少工具,而在它有没有完整的工程约束:能访问什么、能执行什么、什么时候必须停下来等人审批、执行过程怎么留痕、失败以后怎么回滚。
安全不能只靠 prompt 约束,要靠基础设施边界。这意味着 Agent 的架构本身需要一道不可绕过的隔离层。
生产级 Agent 的核心原则是:推理核心不能绕过控制边界,直接进入执行系统。
第一层是输入与上下文。人类目标、工程现场、运行态状态、历史经验和策略约束,构成 Agent 推理前的全景输入。
第二层是推理核心。Planner、Memory、Risk Reasoning 负责理解现场、检索记忆、评估风险、生成方案。它可以提建议,但绝对没有直接改生产环境的权限。
第三层是控制边界。验证引擎、策略引擎、审批闸门、审计与证据、回滚准备——这道墙决定了 AI 的建议有没有执行资格。
第四层是执行系统。CI/CD、GitOps、Kubernetes 只接收经过控制边界授权的动作。Agent 的推理从未直接触碰生产系统。
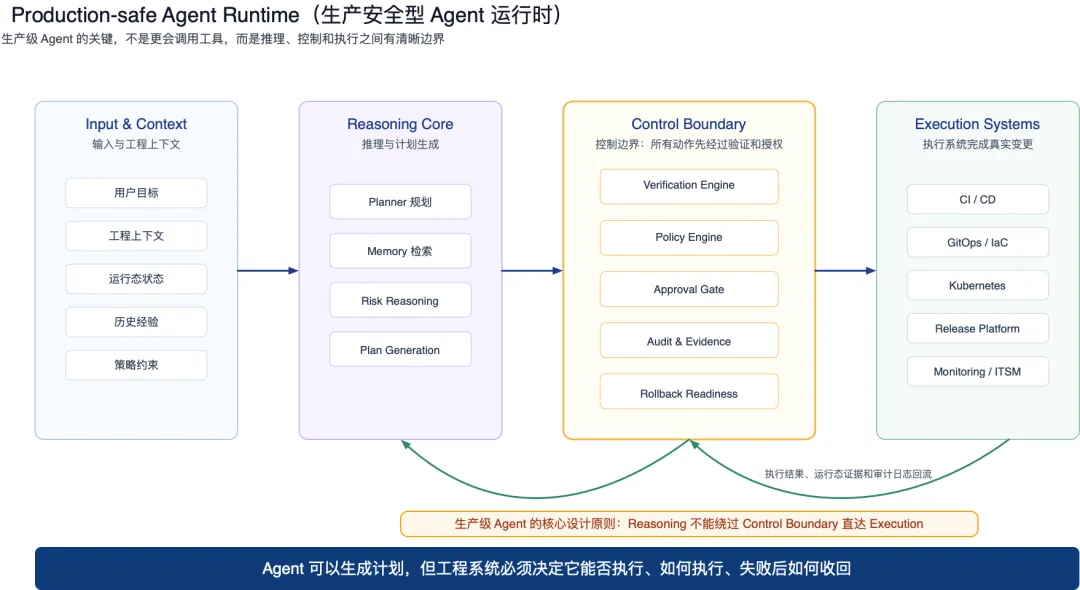
拿支付事故走一遍。事故发生后,输入层聚合了四条关联信号:commit diff(连接池变更)、服务拓扑显示的受影响服务、实时 P99 和转化率曲线、历史同类事故记录。推理层判定风险为「高」,连接池变更的历史故障模式、灰度阶段 P99 从 200ms 升至 1.2s、转化率偏离基线 8%,三组信号交叉验证。
控制边界层接手了三项检查:验证引擎先核数据——「P99 上升持续了 3 分钟还是瞬态抖动?刚才 1.2s 的采样基数够不够?」确认不是毛刺后,策略引擎对照变更策略表——「暂停灰度」在值班 SRE 授权范围内,不需要跨团队审批。最后审批闸门把摘要发给值班人员:「P99 200ms→1.2s,转化率下降 8%,建议暂停灰度。证据附件:最近 5 分钟时序图、同类事故索引、回滚预案。」同时回滚预案自动预加载到执行系统。
只有三个闸门全部放行后,执行层才执行降灰度动作。AI 的推理从头到尾没碰过生产系统。
关键不在于 AI 做了正确的暂停建议,而在于这个建议经过了多少道关卡才变成动作。
同一个机制,往前移一步
四层结构不只用于事故响应。如果把同样的机制前移到代码提交之前,故事完全是另一个版本,这次问题根本没机会变成事故。
还是那条连接池变更。假设它在提交 PR 时,四层结构就在运转:输入层聚合了架构约束记录(「连接池变更必须附带 SLO 影响评估」)、受影响服务拓扑(多个上游共享同一个连接池)、历史事故记录(四个月前同类变更导致 P99 恶化 6x,转化率下降 25%)。推理层发现方案缺少 SLO 评估和回滚预案,架构记忆命中——「此变更为 incident #2024-03-15 的根因,置信度 87%」。
控制边界层开始拦截:策略引擎对照约束,方案不满足提交条件。审批闸门推送给开发者,附带证据:「缺失项:SLO 影响评估、灰度观察窗口、回滚脚本。风险参考:历史同类变更导致 P99 恶化 6x」方案被打回。
开发者补齐后重新提交,三条约束全部通过,变更进入可控的灰度流水线:5% 起步 → 观测 10 分钟 → P99 稳定再扩量。以这个案例来说,从开发者补齐材料到灰度启动,全过程不到 15 分钟。而前一条变更从灰度到被发现,花了近三天。 两种结果的差距不在 AI 能不能推理,而在边界条件是在变更前被系统性地校验,还是等到现场出事才被偶然发现。
人的角色变了
这种架构改变的不只是 AI 的运行方式,也改变了人在链路里的位置。
拿连接池那条线来说,没有这套架构时,架构师要逐行评审 AI 生成的连接池配置,判断线程池大小合不合理、超时配置有没有踩坑——每个变更都得靠人的经验和精力去过滤。有四层结构之后,这些判断标准被搬进了策略引擎:线程池大小不能超过 X、超时配置必须走 Y 类模板、连接池变更必须附带 SLO 影响评估。AI 生成的方案先被规则过滤一遍,只有触达边界条件的才需要人来看。
人不再需要盯住 AI 生成的每一行代码,而是上移到更关键的位置:评审 AI 的关键输出靠不靠谱——比如推理层判定「风险高」的依据够不够充分;校准 Agent 的操作边界和策略偏好——线程池的阈值设在哪、什么情况下可以缩灰度不用等审批;设计让 Agent 可控运行的工程环境——把隐性约定变成可执行的规则。就像第一篇里说的:人要从「逐条做判断」变成「定义什么是对的」。
生产级 Agent 的重点,不是让 AI 更自由,而是让 AI 在清晰边界内更可靠。
下一篇
四层结构解决了「AI 的建议能不能进生产」的问题。但四层结构的每一层都依赖一个前提:有组织良好的工程现场数据可读。如果代码、拓扑、运行态指标、历史事故记录分散在六个不同的系统里,输入层聚合到的就是六份各自正确的碎片——认知链从一开始就是碎的。
上一篇:当AI 踩下加速踏板,然后呢?
下一篇:Engineering Context Flow,AI 凭什么理解真实软件工程。
参考资料
参考资料 1:思码逸博客,《一文讲透研发效能!您关心的问题都在这里》。
参考资料 2:DORA,《2025 年 AI 辅助软件开发现状》。
参考资料 3:Forsgren 等,The SPACE of Developer Productivity。
参考资料 4:Houck 等,The SPACE of AI: Real-World Lessons on AI's Impact on Developers。
