 夜雨聆风
夜雨聆风
当电厂有了 "AI 大脑":一套真正落地的智慧电厂智能助手长什么样?
抛开概念堆砌,聚焦落地实效。本文依托落地项目实践,从 8 大功能模块、5 条核心数据链路,阐述人工智能技术如何深度融入电厂运维日常业务场景。
智慧电厂的概念说了很多年,但落到一线,工程师们核心诉求其实很朴素:搜规程能不能快一点?写报告能不能省点事?查数据能不能不用手写 SQL?
本产品并非空泛的数字化转型概念产品,而是立足于现场痛点打造的实用型效能赋能工具。下文从工程落地与技术实现的角度,拆解这套已经在电厂内网部署运行起来的 AI 智能助手。
系统按职责分为三层:
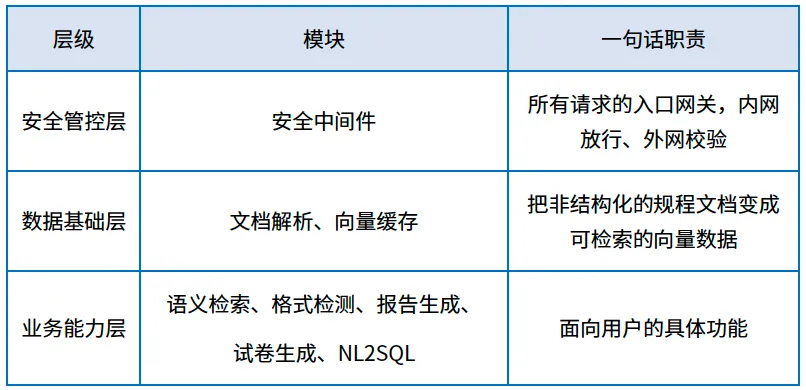
三层自上而下调用,每一层的设计都遵循公共能力下沉、业务模块共享研发准则,规避重复开发。
这是整套系统最核心的数据流转链路。
管理员将运行规程、安全制度、检修标准、应急预案等 Word/PDF 文档放入指定目录后,系统自动按章节标题规则(正则匹配 "第 X 章"、"第 X 节"、中文序号 "一、" 等)切分文本。每个文本块携带四项元数据:文档名、章节标题、文档类型、页码。
不是简单的全文分词,而是以章节为最小检索单元—— 这样用户搜 "汽轮机超速保护动作条件" 时,返回的是一个完整的小节,而不是零散的句子片段。
切分后的章节文本块,调用 BGE-M3 模型编码为 1024 维稠密向量(同时生成稀疏权重向量用于关键词增强),连同元数据序列化为独立文件存储在本地磁盘。
BGE-M3 相较通用多语种模型有三个关键提升:原生中文优化,对电厂术语("两票三制""MFT 动作条件 " 等)的语义表征更精准;8192 token 上下文窗口,完整覆盖长章节条款不被截断;1024 维高区分度,对相似但实质不同的条款(如"汽包压力保护" 与 "汽包水位保护")能有效区分。
这一步的关键设计在于缓存策略:向量文件一旦生成,后续检索不再经过文档解析和模型推理,直接从磁盘加载。只有在以下情况才触发重新计算:
指定目录下的文档发生新增、修改或删除
管理员主动发起强制重载指令
效果很直接:冷启动后的检索响应时间从分钟级压缩至毫秒级。
用户输入自然语言查询(比如 "受限空间作业审批流程"),系统采用混合检索策略,两路召回并行、结果融合:
- 稠密向量检索:将查询文本编码为1024 维查询向量,在FAISS 索引上执行近似最近邻检索,捕获语义层面的关联(如"受限空间" 与"密闭空间"" 容器内作业" 的语义等价)
- 稀疏关键词检索(BM25):保留精确关键词匹配能力,确保标准号("GB 26164.1")、设备编号("#3 锅炉")、参数值等不会被语义近似吞掉
- RRF 融合排序:两路召回结果通过Reciprocal Rank Fusion 融合,取Top K 返回
检索结果经 BGE-Reranker 交叉编码器做精排 —— 对候选条款与查询逐对评分,将 "语义近似但实质不相关" 的结果压到后面。这种 "粗排 + 精排" 两阶段结构将检索精度从单纯向量检索的 80% 级别提升至 95% 以上。
整条链路的衔接逻辑还做了一层兜底:如果本地缓存为空(首次使用或缓存被清理),检索模块会反向驱动文档解析和向量缓存模块,走完 "解析→向量化→缓存→检索" 的完整流程,并把结果写回本地缓存。
plaintext

如果说语义检索解决的是 "怎么找",这个模块解决的就是 "怎么写才对"。它在基础格式检测之上,扩展了两项有电厂特色的深度审查能力。
复用文档解析模块的底层能力,四个维度自动比对:
- 1.页面设置:页边距、页眉页脚距离与标准值比对,偏差超阈值即标
- 2.文本格式:标题和正文的字体、字号、颜色、首行缩进、行距逐项合规判断
- 3.页码检测:页码存在性和格式规范性校验
- 4.文本纠错(可选):调用私有化部署的大语言模型逐句推理,识别用词不当和错别字
所有不合规项精确到哪一个段落的哪一个属性偏离了多少,不是笼统地告诉你 "格式不对"。
格式正确不代表内容合规 —— 这是两回事。合规性检查做的是 "内容实质审查"。
系统预置了合规规则库,分三个层次:国家 / 行业法规标准(如《电力安全工作规程》、二十五项反措)、上级主管单位的管理制度、电厂内部的三大标准(管理标准、技术标准、岗位标准)。每条规则标注了适用文档类型和强制性标记。
检查流程:
将待审文档拆分为条款单元 → 对每条条款,用语义检索从规则库中召回相关的合规基准 → 拼接 Prompt 调用LLM 逐条比对 → 输出 "合规 / 不合规 / 缺失" 判断
每条不合规项附带:违规条款位置、应遵循的法规名称和条款号、偏差说明、修改建议
场景举例:安监部修订了《锅炉运行规程》,上传后系统自动检索到《电力安全工作规程・热力机械部分》中关于 "锅炉水压试验" 的四条强制性要求,发现新规程漏掉了 "试验前安全阀应解列" 这一条,直接标红提示 —— 这类遗漏靠人工审很难全部捕获,但合规规则库不会漏。
电厂里不同部门、不同时期编制的规程制度,条款之间的矛盾是个老大难问题。比如安全科说 "必须这样做",运行科的规定是 "可以那样做"—— 该听谁的?
这个模块的执行逻辑是:
将待审文档及关联文档集的所有条款抽取为独立单元(每个单元带文档名、章节、页码) 对每条条款,通过向量索引在全库范围检索语义最接近的候选条款对 对高相似度条款对,用LLM 做语义级冲突分析,判断五种冲突类型—— ◆ 直接矛盾:A 说"必须执行X",B 说"禁止执行X"
◆ 阈值不一致:A 说"汽包压力不超过18MPa",B 说"不超过19MPa"
◆ 程序冲突:同一操作的执行步骤或前置条件不一致
◆ 权责冲突:同一事项的责任主体规定不同
◆ 覆盖范围差异:一个条款的要求明显宽于或窄于另一个
冲突结果按风险等级(高 / 中 / 低)排序输出,附带两条原文、出处和修订建议
场景举例:新编《消防应急处置预案》提交审核前,系统扫描已入库的《集控室运行规程》和《全厂消防安全管理规定》,发现 "电气火灾处置流程" 的前置条件 —— 一份要求 "先断开上一级电源开关",另一份表述为 "确认断电后方可灭火"—— 这在执行层面是两个不同的操作顺序,可能造成现场人员无所适从。冲突报告直接列出了两份文档的原文、页码和建议统一的措辞。
这个功能的底层依赖语义检索模块做相似条款召回、向量缓存模块提供跨文档索引、私有化大语言模型做语义冲突判定,再加上 BGE-Reranker 精排确保召回的 "相似条款对" 是真正语义相关的而非噪音 —— 三条核心链路的能力在这里交汇,构成了整个系统技术密度的最高点。
用户选择报告类型(周安全管理报告、安委会纪要、隐患排查报告等),系统执行三步操作:
匹配预置模板(模板内用占位符标记)
从 CSV 文件或 SQL 数据库拉取对应业务数据
批量替换占位符,生成 Word 文档,返回下载链接
模板引擎是通用的,数据源是可配置的。新增一种报告类型,只需要新增一个模板文件,不需要改代码。
用户设定试卷标题、科目、总分及各题型(单选、多选、判断、简答)的数量与分值后,系统从 SQL 题库对应题型表中执行随机抽题 SQL,按题型和分值排序,套用排版规则生成标准化 Word 试卷。
与报告生成模块共享同一套 Word 文档生成能力(模板填充 + 排版输出),与 NL2SQL 模块共享 SQL 连接池。
这是最 "AI" 的一环。用户输入 "查今年二季度各机组隐患整改率",系统执行五步:
关键词映射:从预配置的业务关键词表匹配数据表("隐患"→隐患数据表)
表结构获取:拉取候选表的 DDL 或表描述文档
Prompt 拼接:将表结构、用户查询、当前日期拼接为固定格式 Prompt
LLM 推理:调用私有化部署的大模型生成 SQL 语句
结果回显:执行 SQL,字段名自动替换为数据库 COMMENT 注释值(如 rectification_rate → "整改率")后返回前端
同时保留直接输入 SQL 的入口,懂技术的工程师不受限制。
系统设计上刻意收敛了公共能力,避免了模块各自为战:
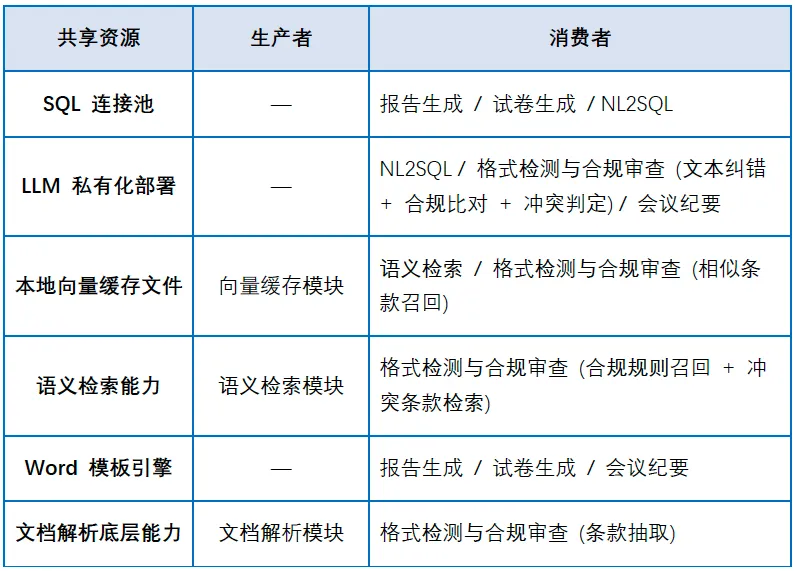
一台服务器部署一套 LLM 实例,三个模块共用,不用每个模块各自调云 API。数据不出内网,模型私有化部署,这也是电厂场景下的硬性要求。
所有请求的第一站不是业务逻辑,而是安全中间件:
内网请求:IP 属于电厂内网网段 → 直接放行,仅记录审计日志
外网请求:先做敏感路径匹配(命中 /admin 等管理路径返回 403),再做请求参数 / 请求体 / 请求头的敏感关键词扫描(命中则脱敏或拦截)
业务模块不需要自行处理安全逻辑,安全与业务解耦。
以电厂安监部工程师准备周安全例会为例:
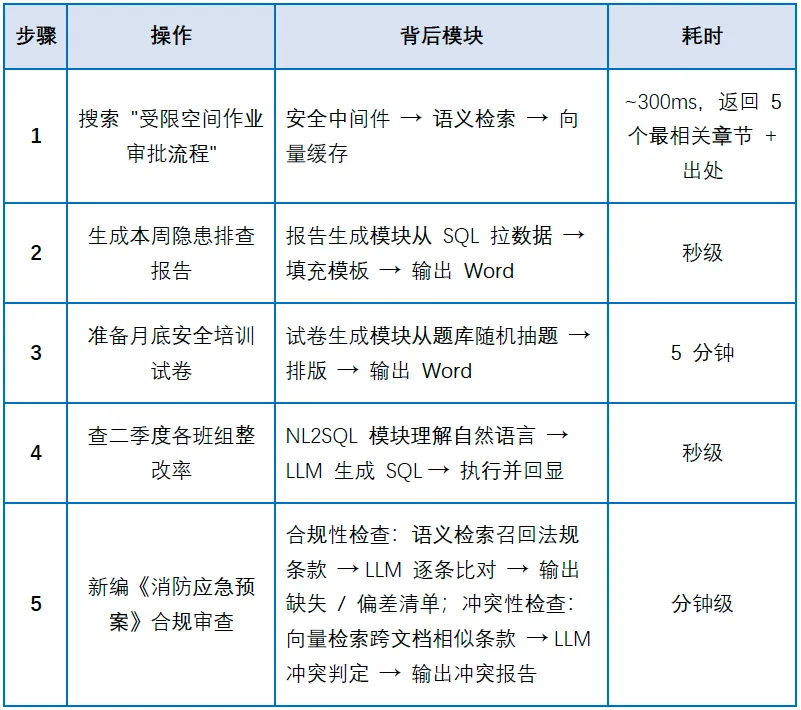
五个操作在同一套系统内完成,数据共享、权限统一、全程不离开内网。
全部本地化、全部私有化部署。不依赖外部 API,不过公网,这是电厂场景下 AI 落地的正确姿势。
本产品研发思路摒弃了技术堆砌,而是把 AI 的能力拆解成一个个具体、可复用的工程模块,嵌入到电厂已有的工作流中。搜规程、写报告、出试卷、查数据 —— 每个单点功能都无颠覆性创新,但全链路组合,覆盖了一线运维的各类高频工作场景。
目前系统已在电厂内网稳定部署运行,后续迭代方向将聚焦:扩充合规规则库覆盖面、打通冲突检查结果与制度修订流程闭环、补充会议纪要的语音转文本能力、以及 NL2SQL 多表复杂关联查询能力。

往期回顾



点击“在看”鼓励一下吧

