 夜雨聆风
夜雨聆风一句话摘要:今天的主线不是单个模型参数更新,而是智能体、企业采购、本地算力和垂直行业方案开始进入真实工作流。
今日重点
为什么值得看:AI 工具正在从“能不能回答”转向“能不能被管理、部署、采购和复用”。对开发者、内容团队和企业运营来说,下一步要看的不是演示效果,而是它能不能接住稳定任务。
- 开发工具开始强调智能体管理,而不是只提供一个聊天入口。
- Windows PC、本地集群和物理 AI 模型栈,正在把智能体能力推向本地和边缘设备。
- 企业市场开始把 AI 当作可采购、可治理、可嵌入组织流程的基础能力。
- 科研、电网等垂直场景说明,真正的落地价值来自数据、流程和专业知识的结合。
开发工具:智能体开始被管理
为什么值得看:当一个人或一个团队同时使用多个智能体,核心问题会从“哪个模型更强”变成“任务、上下文、权限和结果如何管理”。这会直接影响开发、运营、研究和内容生产的日常效率。
1. Hermes Desktop:个人智能体产品继续细分
发生了什么:Hermes Desktop 登上 Product Hunt Developer Tools,产品摘要强调“会随你成长的智能体”。目前素材信息有限,但它的定位指向个人桌面端智能体,而不是一次性问答工具。
为什么重要:桌面端智能体如果能持续理解用户的项目、偏好和任务历史,就可能替代一部分重复整理、资料归纳和轻量执行工作。对个人创作者和独立开发者来说,这类工具的关键不在“回答更长”,而在能否记住上下文并减少切换成本。
你可以怎么用/学什么:适合经常做资料整理、需求梳理、写作提纲和轻量项目管理的人关注。可以先用一个低风险场景试用,例如让它维护一份项目待办、整理会议纪要、跟踪一个选题的资料变化,再判断它是否真的减少了重复劳动。
来源:Product Hunt Developer Tools
2. Devin Desktop:多智能体管理浮出水面
发生了什么:Devin Desktop 的摘要是“从一个界面管理本地和云端智能体队列”。这说明智能体产品正在从单个编码助手,转向统一调度多个本地与云端 agent 的工作台。
为什么重要:对开发团队来说,未来的瓶颈可能不是有没有编码 agent,而是多个 agent 同时跑任务时如何排队、审查、回滚和验收。能统一管理本地与云端 agent 的界面,有机会成为开发团队的新型控制台。
你可以怎么用/学什么:适合已经在尝试用 agent 处理代码修复、测试补齐、文档生成或批量重构的团队关注。可以从“把 issue 拆给多个 agent 并人工验收结果”这类流程开始试,而不是一上来交给它修改核心业务代码。
来源:Product Hunt Developer Tools
本地算力:个人电脑也在承接智能体
为什么值得看:智能体任务往往需要长上下文、持续运行和多步骤调用。把一部分能力放到本地,可以降低延迟、保护数据,也能让开发者在没有完整云端环境时先搭建原型。
3. Microsoft 与 NVIDIA 推出 Windows PC 智能体工具
发生了什么:NVIDIA 介绍了与 Microsoft 相关的新工具,用于在 Windows PC 上构建个人 AI agents,面向创作者、开发者和 AI 爱好者。
为什么重要:这代表个人电脑正在从“调用云端模型的终端”变成“运行、编排和测试智能体的本地环境”。如果本地工具链成熟,开发者可以更方便地做原型验证,创作者也能把资料处理、素材归档、脚本生成等任务放在自己的设备上完成。
你可以怎么用/学什么:适合 Windows 用户、独立开发者和内容生产者关注。可以尝试把一个固定流程拆成 agent 任务,例如读取本地资料、总结重点、生成待办、输出草稿;同时学习本地模型部署、权限隔离和文件访问控制。
来源:NVIDIA Generative AI

4. DGX Spark 强调本地智能体与多节点集群
发生了什么:NVIDIA 提到在 DGX Spark 上运行本地 AI agents,并支持更快模型与多节点集群,面向长时间运行、大上下文和并发任务这类新计算需求。
为什么重要:智能体不是一次推理结束的任务,它可能要保留上下文、并发调用工具、持续等待外部反馈。多节点和本地集群能力,说明企业和高级开发者会需要更专门的算力架构来承接 agent 工作负载。
你可以怎么用/学什么:适合做私有化部署、企业内部知识库、代码 agent 平台或高敏数据流程的团队关注。今天就可以检查自己的 agent 原型是否记录了上下文长度、并发数量、执行时长和失败重试成本,这些会直接影响后续算力预算。
来源:NVIDIA Generative AI
企业办公:助手变成组织流程
为什么值得看:企业 AI 的重点正在从“某个员工会不会用”变成“组织能不能统一配置、授权和审计”。这会影响办公软件、开发工具、采购流程和岗位技能要求。
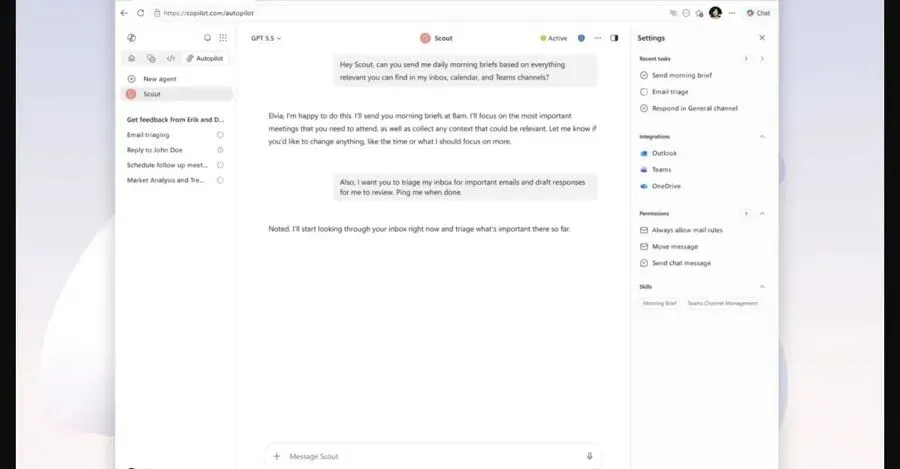
5. Microsoft Scout 进入 Microsoft 365 工作流
发生了什么:The Verge 报道,Microsoft Scout 是一个基于 OpenClaw 的个人助手,集成到 Outlook、OneDrive、Teams 等 Microsoft 365 应用中,可帮助处理日历、报销、邮件草稿等任务。
为什么重要:这类助手如果被放进企业办公套件,影响的不是单个工具,而是员工的默认工作方式。日历、邮件、文件和会议本来就是组织协作的核心入口,助手进入这些位置后,企业会更重视权限、数据边界和结果可追责。
你可以怎么用/学什么:企业运营、行政、人事和项目管理岗位可以优先关注。可先梳理自己团队中“重复、规则明确、需要跨多个办公软件”的任务,例如会议后行动项分发、费用材料收集、邮件初稿和文件归档,判断哪些适合交给助手半自动处理。
来源:The Verge AI
6. Microsoft 与 OpenAI 的关系进入竞争阶段
发生了什么:The Verge 分析称,Microsoft 在 Build 大会上发布或扩展了一系列 AI 项目,包括超级应用、自研推理模型、网络安全工具和类 OpenClaw 的 AI agents,显示其正在强化自身 AI 位置。
为什么重要:平台厂商不再只依赖单一合作伙伴,而是会同时发展模型、应用、agent 和安全能力。对开发者来说,这意味着生态选择会更复杂:同一个工作流可能有 OpenAI、Microsoft 自研能力和第三方 agent 平台多个入口。
你可以怎么用/学什么:开发者和企业技术负责人应避免把关键流程绑死在单一模型接口上。可以优先学习抽象模型调用、工具权限、日志审计和评测机制,让未来切换供应商或混合使用不同模型时成本更低。
来源:The Verge AI

7. Anthropic IPO 叙事指向企业级基础设施
发生了什么:AI News 报道称,Anthropic 的 IPO filing 被视为生成式 AI 从研究驱动阶段走向稳定企业级工具的信号。文章强调,基础模型供应商上市会让产品节奏、采购流程和企业计费方式变得更标准化。
为什么重要:企业采购 AI 时关心的不只是模型能力,还包括价格可预测、服务稳定、合规支持和发布节奏。基础模型公司进入公开市场叙事后,客户会更期待它像云服务一样可预算、可审计、可长期依赖。
你可以怎么用/学什么:企业运营和采购团队可以开始把 AI 成本从“试验预算”改成“业务单元成本”来核算。普通从业者也要意识到,未来会用 AI 只是基础,更重要的是能说明它节省了多少时间、减少了哪些错误、改善了哪个流程指标。
来源:AI News
垂直行业:专业场景决定上限
为什么值得看:通用模型的能力只有进入专业数据和业务流程后,才会变成可衡量的生产力。生命科学、机器人和能源基础设施这些场景,都在提醒我们:行业知识和系统集成能力会变得更值钱。
8. GPT-Rosalind 增强生命科学能力
发生了什么:OpenAI News 介绍了 GPT-Rosalind 的新能力,包括更强的生物推理、药物化学、基因组分析和实验工作流能力,面向生命科学研究。
为什么重要:这类产品说明 AI 在科研场景中的角色正在从“辅助阅读论文”走向“参与实验设计和专业分析”。它不会让非专业人士直接替代研究员,但会提高研究团队处理文献、生成假设、整理实验路径的效率。
你可以怎么用/学什么:科研人员、医药行业从业者和做垂直 AI 产品的人应关注“领域推理+工作流”的组合。可学习如何把专业术语、实验步骤、数据格式和审查机制写进提示词或工具链,而不是只让模型泛泛总结资料。
来源:OpenAI News
9. NVIDIA Cosmos 3 面向物理 AI
发生了什么:NVIDIA 介绍 Cosmos 3,用于发展物理 AI 的推理模型、世界模型和行动模型,面向机器人、自动驾驶和智能空间等需要理解真实世界再行动的系统。
为什么重要:物理 AI 和普通文本助手不同,错误不只是回答不准,还可能影响设备动作和现实安全。世界模型和行动模型的进展,意味着未来机器人与自动化系统会更依赖仿真、感知、预测和安全验证。
你可以怎么用/学什么:机器人、自动驾驶、工业自动化和空间智能相关开发者应关注仿真数据、动作规划和评测体系。即使不做硬件,也可以学习世界模型的思路:先建立环境状态,再预测变化,最后决定行动。
来源:NVIDIA Generative AI

10. E.ON 用 SAP S/4HANA 统一电网数据
发生了什么:AI News 报道,能源企业 E.ON 通过 SAP S/4HANA 标准化电网数据,以支持基础设施现代化和 AI 部署。文章提到其业务覆盖能源电网、客户解决方案和能源基础设施解决方案等领域。
为什么重要:这类案例说明,大企业落地 AI 的前提往往不是先买模型,而是先整理核心数据和业务系统。电网这种高复杂度场景尤其依赖标准化数据,否则模型很难稳定参与预测、维护和运营决策。
你可以怎么用/学什么:企业数字化、数据治理和运营团队可以把它当作提醒:AI 项目前先检查数据口径、系统字段、权限和维护流程。普通从业者也可以补上业务系统理解能力,因为未来很多 AI 项目会卡在“数据能不能被正确调用”这一步。
来源:AI News
今日观察
今天的几条动态可以合成一个判断:AI 正在从“工具试用”进入“工作流重构”。开发者工具在解决多 agent 管理,本地算力在承接长任务,办公平台在抢默认入口,基础模型公司在对齐企业采购,垂直行业则把焦点放到数据和专业流程。
这对个人最直接的影响是,单纯会提问的优势会变薄。更有价值的是能把任务拆清楚,知道哪些步骤适合交给模型,哪些环节必须保留人工审查,并能用日志、指标和结果验收来证明效率提升。
今日可执行清单
1. 选一个重复流程,拆成“输入、处理、验收、归档”四步,判断哪一步最适合交给智能体。
2. 试用或关注一个桌面端 agent 工具,重点观察它是否支持项目上下文、历史记忆和结果复盘。
3. 检查团队正在使用的 AI 工具是否有权限控制、日志记录和失败回滚方案。
4. 如果你做开发,抽象出模型调用层,避免业务流程过度绑定单一供应商。
5. 如果你在企业或垂直行业,先列出最影响 AI 落地的数据问题,例如字段不统一、权限不清、流程没有标准出口。
留言聊聊
- 如果工具开始按用量收费,你会先限制哪些高频场景?
- 你觉得算力和能源成本,会不会影响你所在行业上工具的节奏?
- 哪些决策你愿意交给工具辅助,哪些必须保留人工确认?
欢迎留言聊聊。
