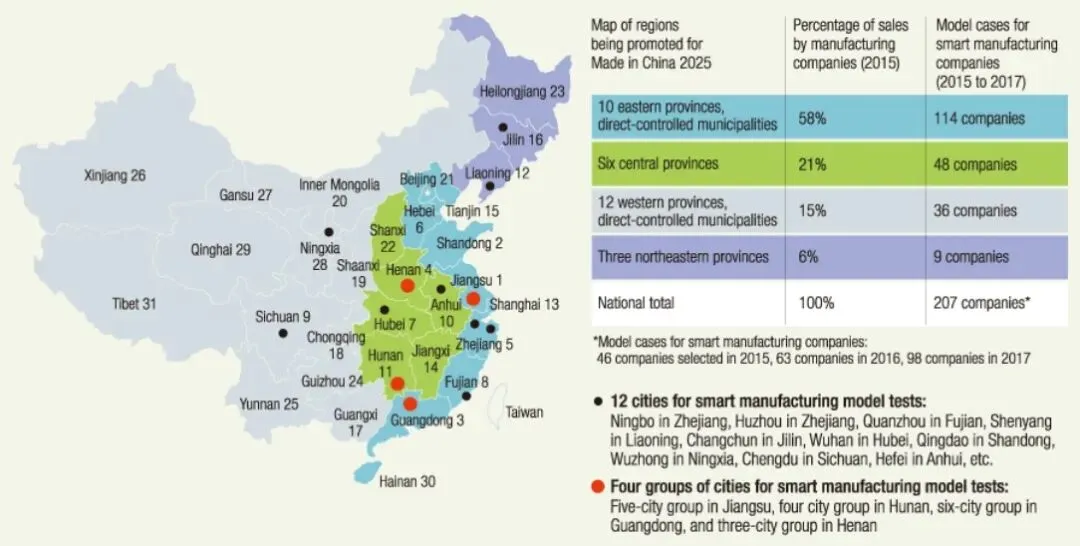
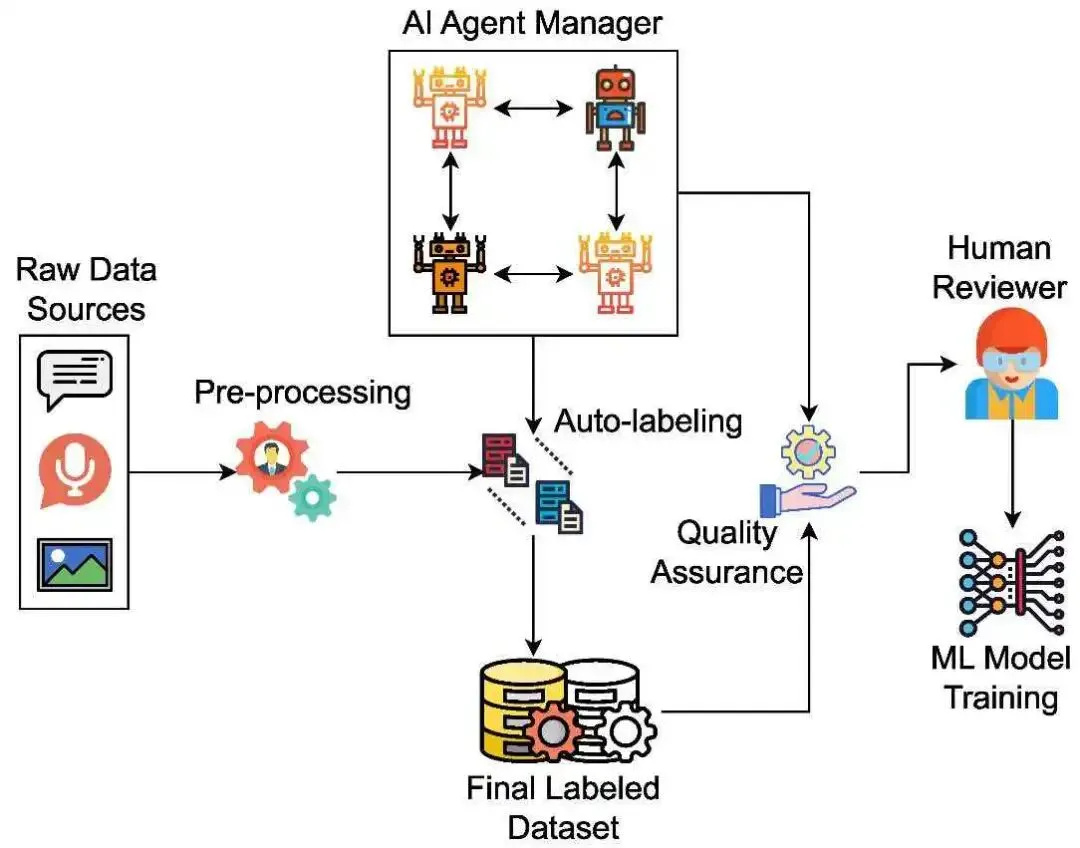
AI的"启蒙老师":百亿数据标注产业背后,站着一群隐形人ChatGPT能写诗,Midjourney会画画,自动驾驶汽车能自己上路。但你可能不知道,这些AI在"开窍"之前,都得先上一门课——数据标注课。而给它们上课的人,正站在整个科技浪潮最安静的角落里。一、先搞明白:数据标注到底在标什么?用最土的话说,数据标注就是教AI认世界。就像你教两岁小孩看图说话,指着一张图说"这是猫,那是狗","红灯停,绿灯行"。数据标注员干的就是这个——只不过他们的"学生"是AI。一张街景照片,他们得用鼠标把行人、汽车、交通灯一个个框出来;一段客服录音,他们得逐字听写并标上情绪标签;一段医学影像,他们得圈出肿瘤可能的位置。没有这些标注,AI就是瞎子、聋子、傻子。你手机里的人脸解锁、导航里的路况识别、医院里的AI辅助诊断,背后全是标注员一笔一画喂出来的。二、产业爆发:国家押注的百亿赛道这几年,数据标注已经从"散兵游勇"变成了"正规军"。2025年,中国数据标注市场规模冲到117.53亿元,十年翻了十倍还多。国家数据局一口气在成都、沈阳、合肥、长沙、海口、保定、大同布局了七大标注基地,到2025年3月,这七个基地攒下了17282TB的数据,做出了335个高质量数据集,直接喂饱了121个国产大模型的研发。从业人员5.8万人,带动产值超过83亿元。政策也在狂踩油门。2025年初,国家发改委等四部门联合发文,明确提出到2027年产业年均复合增长率要超过20%。各省都在抢这块蛋糕,连职业技能大赛都开到了数据标注赛道。看起来,这是一片金光闪闪的新蓝海。三、但钱去哪了?时薪2美元的"幽灵工作者"产业百亿,不代表干活的人能分到一杯羹。美国一项针对ImageNet(计算机视觉领域最权威的图像数据库之一)的研究发现,参与标注的工人平均时薪只有约2美元,只有4%的人能挣到超过美国联邦最低工资(7.25美元/小时)。而在肯尼亚,为OpenAI、Meta等巨头做数据标注和内容审核的工人,时薪低至1.16美元,每周高强度工作45小时,完不成目标还得无偿加班。国内也没好到哪去。兼职标注员一天干三四个小时,时薪也就30到60块钱。外包岗位月薪大多在9K-17K,大厂正式岗15K-25K——听着还行,但跟算法岗一比,连零头都算不上。学术界给这群人起了个名字叫"幽灵工作者"(Ghost Workers):他们的劳动创造了AI系统的核心价值,却在利润分配里彻底隐身。正如一位肯尼亚标注员说的:"他们赚着几十亿,用我们来制造亿万富翁。"四、不止穷,还伤身:被AI"榨干"的人比低收入更狠的,是这份工作对人的消耗。在肯尼亚,很多标注员做的是内容审核,每天盯着暴力、血腥、色情、自残的图片和视频看。长期暴露在这种内容下,焦虑、抑郁、创伤后应激障碍(PTSD)成了职业病。有工人说:"看完心理医生后,我开始感到愤怒和恐惧……那些内容以我从没想象过的方式影响了我。"可公司给的心理支持?几乎等于零。国内的情况则是"没有成长性的重复劳动"。有985毕业生入行后自嘲是"给AI拧螺丝":每天拉框、打点、勾选,干两年除了鼠标手什么都没攒下。更可怕的是,这份工作的壁垒太低了——"你不干,有的是人肯干",所以价格永远上不去。而自动化标注工具一来,连这点拉框的活儿都可能被机器抢走。标注员亲手把AI教聪明,然后AI转头就把他们的一部分饭碗砸了。五、更隐蔽的雷:你的隐私,正在被人标注很多人没意识到,数据标注还踩着一个更危险的线——隐私与伦理。标注员每天接触的是什么?可能是你的病历片、你的人脸照片、你的聊天记录、你的购物习惯。医疗影像标注需要看到真实患者CT,语音标注需要听到真实通话录音。虽然企业说会"脱敏",但2023年ChatGPT就被爆出过数据泄露漏洞,重复一个词就能把别人的个人信息"诈"出来。更深层的问题是偏见。标注员带着自己的认知去教AI,AI就会继承这些偏见。如果标注团队里某种文化背景的人占绝对主导,AI就可能对少数群体"脸盲"或"误判"。你以为是机器在歧视,其实是人的偏见被代码放大了。六、行业在变,但人跟上了吗?当然,这个行业不是一成不变的。现在最前沿的方向是"人机协同"——机器先自动预标注,人工只做审核和修正。效率高了,对标注员的要求也从"手快"变成了"眼毒、懂业务"。自动驾驶需要标注员懂点车辆运动学,医疗标注需要懂点解剖学,金融标注需要懂业务逻辑。政策也在补位。2023年《生成式人工智能服务管理暂行办法》明确要求:数据标注得定规则、做质检、培训标注员。2025年的《关于促进数据标注产业高质量发展的实施意见》更是把"专业化、智能化"写进了目标。可问题是:机器升级了,人的待遇和尊严升级了吗? 从"劳动密集型"转向"知识密集型"是好事,但如果转型只是让少数人拿高薪、多数人直接失业,那不过是换了一种方式制造"幽灵"。七、写在最后:喂饱AI的人,不该只配喝汤我们老在讨论"AI会不会替代人类",却很少回头看看:在AI还没长大的时候,是人类在一笔一画地喂养它。数据标注产业从11亿涨到117亿,证明这条路走通了。但一个产业的成熟,不能只看市场规模和赋能了多少大模型,还得看最底层的劳动者能不能体面地活下去。117亿的蛋糕,不能只让平台和算法工程师吃饱,而那些拉框、听音、审图的人,连一块像样的面包都分不到。技术当然可以向前狂奔,但奔的时候,至少回头看看是谁在给它系鞋带。毕竟,如果教AI认世界的人,自己都不被这个世界善待——那AI学到的,恐怕也不只是知识。关于「数据标注」,你还好奇哪些不为人知的冷知识?纠结标注靠人工判断,还是算法辅助修正?欢迎评论区留下想法,🔗 转发AI好友一起探讨~
 夜雨聆风
夜雨聆风