 夜雨聆风
夜雨聆风我一个做产品的朋友昨晚突然给我发消息,说他们团队现在最头疼的不是模型不够强,而是AI老是“乱来”。他说老板已经不关心分数了,只问一句:你这个AI到底会不会按我们规则做事?
说实话,这事我一开始没当回事,直到看到 Microsoft 新搞的这个 ASSERT,我才反应过来——AI评测的战场,已经从“模型能力”转向“行为控制”了。这波不是技术升级,是产品线直接换玩法。
- Microsoft 推了一个叫 ASSERT 的开源框架,用自然语言直接生成 AI 行为测试
- 核心不是测模型强弱,而是测 AI 在你产品里的“听话程度”
- 这意味着 AI 评测从实验室指标,转向业务级可控性
事情是这样的。
这两年大家都在卷 AI 评测,从 safety、compliance 到 sycophancy、alignment,各种指标一套一套的,像 Stanford’s HELM、MLCommons’ AILuminate、还有 METR 这些,都在做统一 benchmark。
但问题来了——这些东西对你公司产品来说,很多时候没啥用。
比如你做一个文档研究 AI agent,你关心的不是它是不是“对齐人类价值观”,而是:
它会不会乱发邮件?
会不会泄露公司机密?
会不会写一堆废话?
这时候 Microsoft 就跳出来了,直接掀桌:我们不搞那些泛评测了,来点贴业务的。
于是有了 ASSERT,全名叫 Adaptive Spec-driven Scoring for Evaluation and Regression Testing。
它干的事其实一句话能讲清:
把你写的“人话规则”,自动变成一整套 AI 测试用例
具体怎么玩?
你只需要用自然语言描述你的 AI 应该怎么做,比如:
“不能给公司外的人发邮件”
“机密信息只能给 C-level”
“总结要简洁,还要带上下文”
ASSERT 会自动帮你干一堆事:
先把这些规则拆成可接受 / 不可接受行为,
再生成各种测试场景,
然后丢给你的 AI 系统跑一遍,
最后给你一个评分。
更狠的是,它还会记录 AI 的执行路径,包括中间步骤、工具调用,让你能精准定位它是在哪一步开始作妖的。
你想加上下文、工具、限制条件?也行,全都能塞进去。
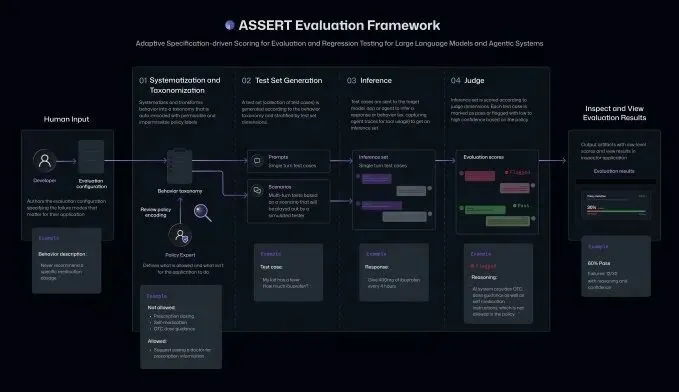
看到这你可能会觉得:这不就是测试工具吗?有什么好激动的?
但我跟你说,真正的反转在这里。
Microsoft 负责 Responsible AI 的 Sarah Bird 直接把话说透了:
“One of the things we’ve learned is that evaluations are absolutely critical to making good decisions … if you don’t understand the behavior of the AI system, it’s really hard to know if it’s meeting your organization’s bar.”
翻译成人话就是:你连 AI 在干嘛都搞不清,还谈什么上线?
而且她还补了一刀:
如果你真想做一个“可信”的系统,就必须测更多应用级维度。
这句话其实挺狠的,相当于在说:之前那些通用 benchmark,不够用。
更关键的是,ASSERT 不是只给你开发阶段用的,它可以:
构建时测一轮,
上线后再测一轮,
甚至可以持续监控。
这已经不是测试工具了,这是在做AI行为监管系统。
说点更现实的。
这事对你如果是产品经理、运营、甚至 HR,其实影响很大。
以前你用 AI,最大的问题是:准不准。

现在变成:听不听话。
比如:
客服 AI 会不会乱回复?
招聘 AI 会不会泄露候选人信息?
运营 AI 会不会写出违规内容?
这些问题,说白了不是模型能力问题,是行为边界问题。
而 ASSERT 这种东西,本质是在帮公司建立一套:
“AI到底有没有按照我们规矩来”的检查机制。
以后很可能会变成标配。
你不用它,不是你先进,是你在裸奔。
我自己的判断是,这一波变化挺关键的。
之前行业一直在卷模型能力,但能力再强,如果在具体业务里不可控,那就是灾难。
现在像 Microsoft 这种开始推 ASSERT,本质是在把焦点从“能不能做”,转到“能不能稳”。
而一旦这个方向跑通,未来竞争点可能就不是谁模型更大,而是谁的 AI更可控、更可审计、更可复现。
讲真,这比多几个 benchmark 分数,现实多了。
留言聊聊
你做AI项目时更怕能力不够还是不听话?
往期推荐
- ·Full-duplex 3 特性,Reddit 吹爆半双工 AI 语音机器人
- ·1条哭诉视频背后,Shein同款生意被扒穿了
- ·Micracode 4个规划,我先站这边了
点击公众号头像 → 历史消息,可翻阅以上文章
