 夜雨聆风
夜雨聆风AI 的高考成绩单很诡异:文科过一本线,理科全体不及格。
这不是一种巧合。这是两套完全不同的智能范式,在标准化考试这个照妖镜下,露出了各自的真面目。
一张离谱的成绩单

2024 年高考新课标 I 卷大模型评测, GPT-4o 文科总分 562 分,在河南文科考生中排前 2.45%。国产豆包 542.5 分,文心一言 4.0 拿了 537.5 分。三款国产大模型全过了文科一本线( 521 分)。
语文作文方面, GPT-4o 拿了高分。阅卷老师是北京市级骨干教师,她的评价很精准:"AI 作文有清晰完整的结构,有逻辑性,语言通顺流畅,但缺乏感情和感染力"——换句话说,它写出了一篇满分范文,但读起来像一具完美的空壳。
英语更夸张,九款大模型在客观题上几乎全满分。但在 40 分的写作考试中,最高分只有 29 分——老师给出的理由是"表达空泛,缺少细节"。
然后我们翻到理综。
数学满分 150 分,只有三款大模型拿到了 60 分以上。物理满分 110 分,平均分 39 分。化学满分 100 分,平均分 34 分。
这不是"还有进步空间"。这是完全不会。
文字接龙的数学后果
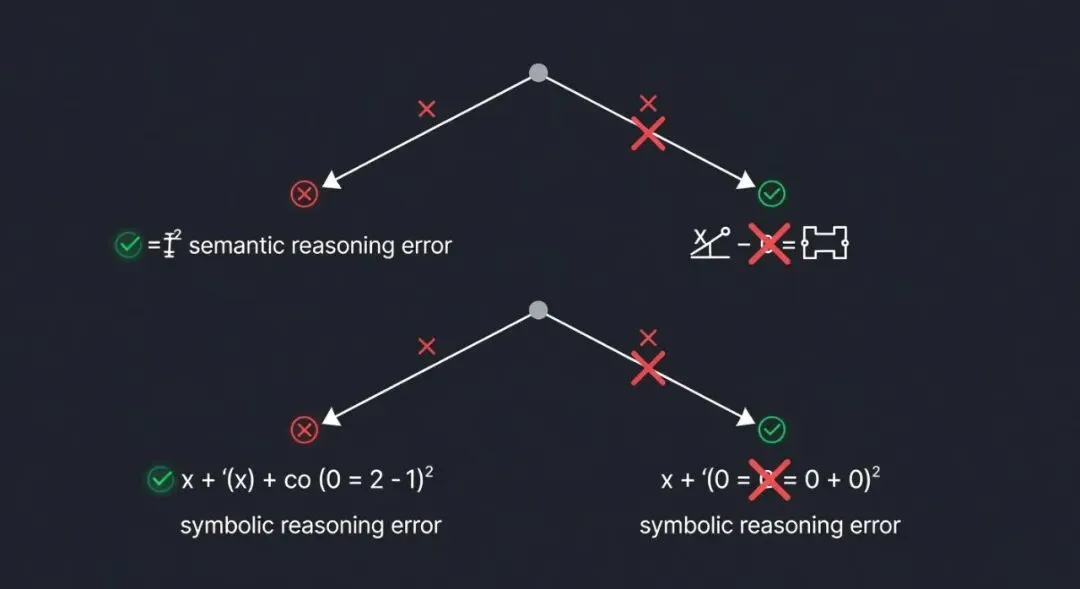
一位国内大模型研发专家给了最简单的解释:"目前的大语言模型本质上是文字接龙。基于海量语料,预测下一个最可能出现的词句。"
这句话很轻,但拆开是地震。
你问 AI"一个物体从斜面滑下,已知初速度……",它读到"已知"后,下一个字最可能是什么?在它训练数据里,可能是"摩擦系数""斜面角度""质量"……它顺着概率最高的路径往下走。它不会停下来想:"等等,这个物体到底什么情况?斜面是无限长还是有限长?物体有没有可能飞出斜面顶端?"
北京大学计算语言学研究所的穗志方教授说得更系统:"在大模型内在机理没有探究清楚的情况下,我们目前的评测路径只能依靠从外部表现来推测内在能力。"换句话说,我们看到的 AI 的"思维",可能根本不是思维——只是一个输出格式恰好长得像推理步骤的东西。
北大物理学院的研究团队把这个现象量化了。他们在 PHYBench 评测中发现,超过 90%的错误发生在"语义推理"环节,即"从物理原理推导出应该用什么方程"这一步——而不是后续的数学计算。 AI 在纯数学运算上反而表现不错。它的短板不是计算能力。是不知道什么时候该算什么。
文科为什么就过了
文科的评分逻辑和理科完全不同。
一个作文好不好的判断,依赖的是语言流畅度、结构完整性、论据的丰富程度。这些正好是"文字接龙"擅长的——它读过的语料里,"流畅""完整""丰富"的文本太多了,它只需要在概率空间里找到那条最像"高分范文"的路径。
而用词稍微不准,或者用了不太恰当的近义词,在文科评分里不太影响大局。作文没有唯一正确答案——老师不会因为你把一个比喻写成了另一个比喻而整段判错。
但物理不一样。
物理的每一步推导都必须准确。方程一旦列错一个符号,后面的计算就算全对也是零分。而且物理题不能靠"见过类似的"套答案——耶鲁大学的研究者验证过:用已经训练过的问题去测大模型,准确率很高;但用全新的、谁都没见过的问题去测,成绩立刻跳水。
2024 年高考真题,没有一个大模型在训练时见过。所以它们裸考的成绩,就是它们真正的物理理解水平——高于随机,低于人类后 30%。
杨立昆的预言

Meta 首席 AI 科学家杨立昆在 2025 年的一个访谈里说了一句很重的话:"我们永远不可能仅仅通过训练文本来达到人类水平的 AI 。动物和人类并不是通过这样学习世界的——我们通过与物理世界的交互来理解世界。"
他举了一个通俗的例子: ChatGPT 可以详细描述"如何骑自行车"——保持平衡、蹬踏板、控制方向……但如果让一个搭载大语言模型的机器人真正去骑自行车,问题就暴露了。它不理解重力。不理解惯性。不理解为什么身体往左倾的时候车会往左倒。这些对人类来说不需要学习、不需要思考的物理直觉,对语言模型来说是不存在的——因为从来没有一段文字需要解释"为什么人会从自行车上摔下来"。
这就是作文和力学的根本分界线。
作文在语言里面。语言有规则,但规则是软的。换一个词,换一个句式,换一个比喻,只要读起来通顺就算合格。力学在物理里面。物理的规则是硬的。重力加速度永远是 9.8——你写成 9.81 可以,写成 9.8 可以,写成 10 可以,但写成 20 就全错了。而且这个错误会像传染病一样,从第一步一直传染到最后。
一个可以容错的系统和一个零容错的系统, AI 在前者表现优异,在后者原形毕露。不是 AI 变笨了。是考试换了科目。
