 夜雨聆风
夜雨聆风字数 2010,阅读大约需 11 分钟
DBeaver 又卡了。
不是第一次。点开一个 MySQL 连接,等它把 Java 虚拟机搓热了,我倒完一杯水回来,loading 还在转。内存吃了 1.2G,就一个三张表的测试库。
Navicat 倒是快,四位数价格,每次续费都觉得在被抢。TablePlus 挺好,macOS 限定,我这 Windows 和 Ubuntu 不配。
然后我在 GitHub trending 刷到了 dbx。
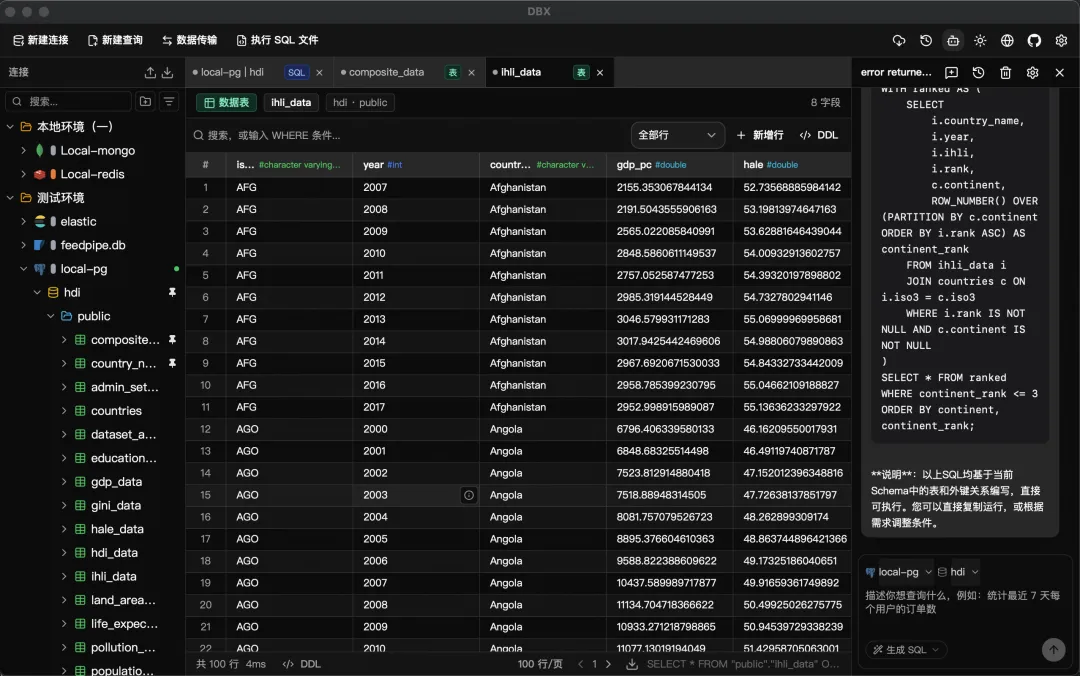
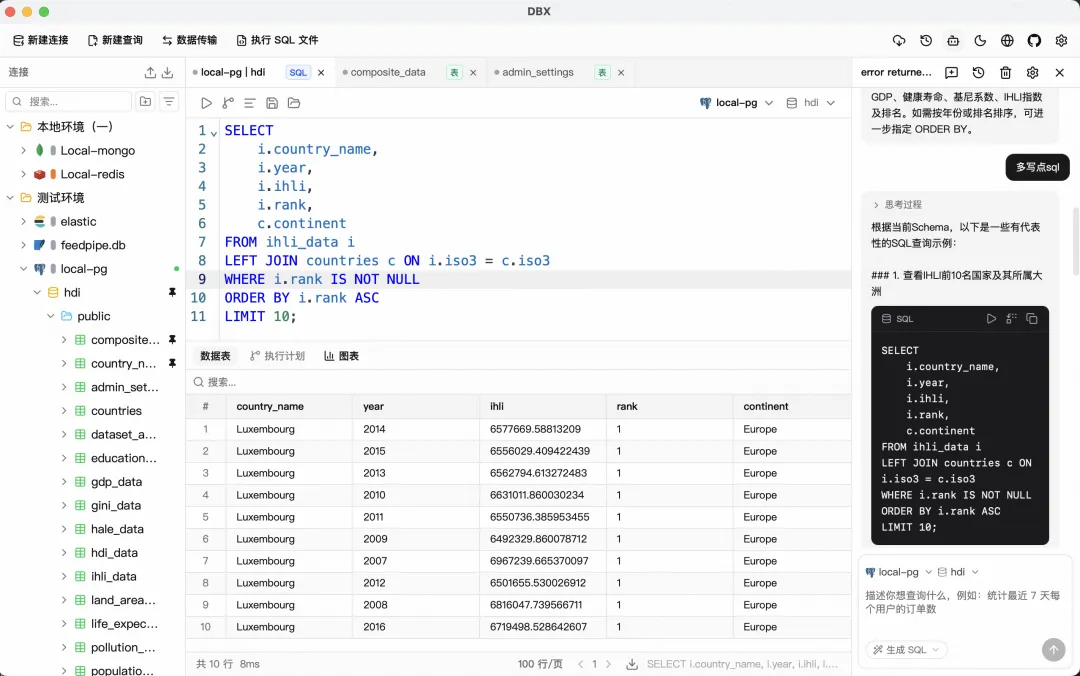
dbx,GitHub 开源,3.6K Star。说它是客户端不太准确。桌面版、Web 版、Docker 自托管版、CLI 命令行版,还内置了 MCP Server 让 AI 编程助手直接读你的数据库。五种形态,一个工具。
但最狠的是体积:15MB。
DBeaver 安装包 400MB 起步(还不算 JRE),Navicat 200MB+,DataGrip 就别提了。dbx 一个二进制文件,双击打开,不用装 JDK,不用装 Python,不用装 Node。
能做到 15MB,技术栈起了关键作用。Rust + Tauri 2 + Vue 3。Rust 写后端驱动层,Tauri 2 直接调系统原生 WebView 做渲染,不打包 Chromium。DBeaver 为什么慢?它是跑在 JVM 上的 Eclipse,启动要加载几百个插件,光框架本身就比 dbx 大十倍。Navicat 虽然 C++ 写的,二十年代码债堆在那,新功能硬往上摞,体积收不住。
我测了一组数据:
• 冷启动到主界面出现:不到 2 秒 • 空闲内存占用:80MB 左右 • 打开一个 10 万行的查询结果,滚动不卡
同样的查询在 DBeaver 上,先是等了 3 秒才出结果,滚动的时候还有半秒延迟。工具响应快慢直接影响工作效率。你查一个东西,等 3 秒和等 0.5 秒,脑子里的思路是完全不同的状态。
体积小归小,功能要是阉割得太厉害,那就从"轻量"变成"简陋"了。dbx 还算拎得清这点。
它支持 40+ 种数据库。MySQL、PostgreSQL、SQLite、SQL Server、Oracle 这些标配不用说了。Redis、MongoDB、Elasticsearch 也都有专门的浏览器页面。ClickHouse、DuckDB、Doris、StarRocks 这些 OLAP 引擎也在列表里。甚至达梦、人大金仓、openGauss 这种国产数据库也支持。
关系型、NoSQL、OLAP 一个窗口全管。以前我得开三个软件:DBeaver 连 MySQL,RedisInsight 看缓存,MongoDB Compass 查文档。现在一个窗口全搞定。
查询编辑器用的是 CodeMirror 6,SQL 语法高亮、自动补全、Cmd+Enter 执行、选中部分执行,这些基操就不啰嗦了。有一个细节我很喜欢:它的自动补全是元数据感知的。你连上数据库后,表名、字段名会被索引,打几个字母就弹出来,不用翻左边的目录树。
数据表格用了虚拟滚动,查 50 万行也不会卡。支持行内编辑,改完的数据会按颜色标记(绿=新增,橙=修改,红=删除),批量保存前还能预览要执行的 SQL。这个设计比 DBeaver 那种直接改直接提交的方式安全多了。
导出格式也很全:CSV、JSON、Markdown、XLSX、INSERT 语句。导出走 Rust 后端流式处理,大表导出不会卡 UI。
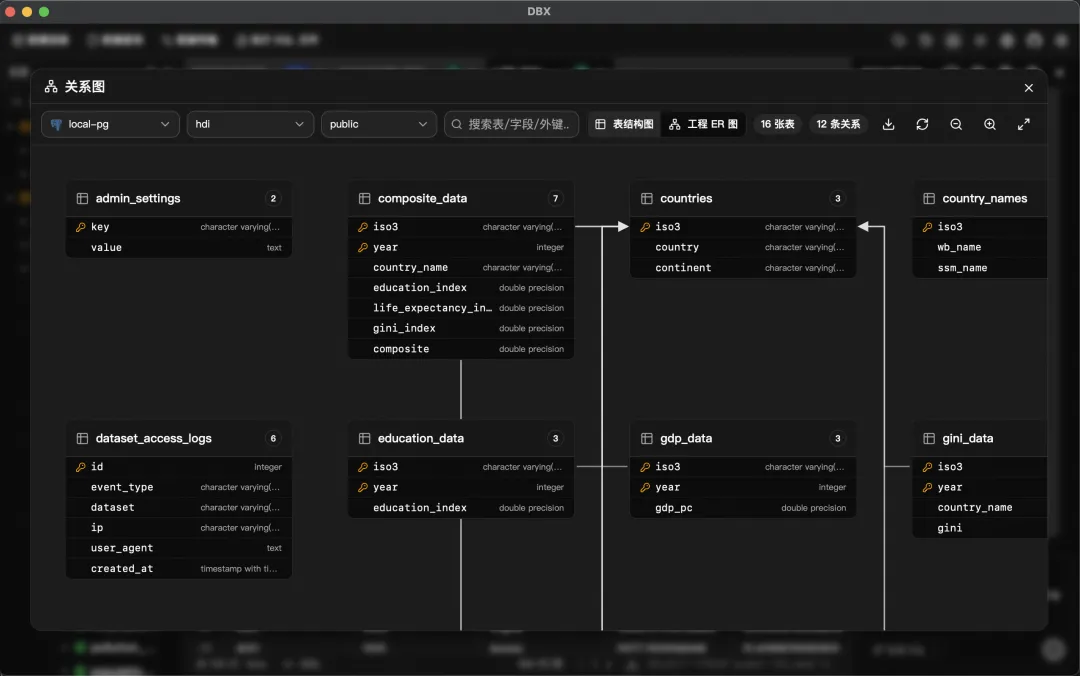
Schema 工具这块,ER 图可以直接生成表关系视图。Schema Diff 能对比两个库的表结构差异,自动生成 ALTER 语句。还有执行计划可视化、字段血缘分析。这些功能 Navicat 得加钱买 Premium 才有。
还有一个我经常用的:直接把 CSV、JSON、Parquet 文件拖进窗口,dbx 用内置的 DuckDB 引擎预览内容,不用先导入数据库。临时看个数据文件非常方便。
上面这些,算是一个数据库客户端该有的基本功。下面这些,才是 dbx 跟 DBeaver、Navicat 拉开身位的地方。
很多数据库客户端现在也号称"集成 AI",做法就是嵌个聊天窗口,让你把 SQL 复制过去问。这不叫集成,这叫贴了个聊天框。
dbx 的 AI 助手是嵌在编辑器里的。选中一段 SQL,右键点"AI 解释",它会直接告诉你这段查询在干什么、有没有性能问题、索引建议是啥。更实用的场景是:在编辑区用自然语言描述你要什么数据,它生成 SQL,生成完还自动跑一遍安全检查。DROP、TRUNCATE 这种危险操作会有二次确认。
可以接 OpenAI、Claude、DeepSeek,也兼容 Ollama 本地模型。自己带 Key,数据不出你指定的 endpoint。
说实话,这个 AI 功能的准确率取决于你用的模型本身,不是 dbx 的功劳。它真正做对了两个事:把 Schema 上下文塞进 prompt 里(所以生成的 SQL 表名字段名是对的),以及生成后帮你做安全检查。这两点恰恰是你在 ChatGPT 网页里写 SQL 最痛苦的。你得先把表结构抄过去,然后祈祷它别给错表名。
这个功能是我装上之后才发现的黑马。
dbx 内置了 MCP Server(Model Context Protocol)。你在 dbx 里配好的数据库连接,可以直接被 Claude Code、Cursor、Windsurf 这些 AI 编程工具调用。
启动 MCP Server 就一行命令:
npx @dbx-app/mcp-server然后在 .mcp.json 里配置一下:
{ "mcpServers": { "dbx": { "command": "npx", "args": ["-y", "@dbx-app/mcp-server"] } }}配好之后,你在 Cursor 里跟 AI 说"帮我查一下 users 表里最近 7 天注册的用户数量",AI 可以直接通过 dbx 的 MCP 服务连上你的数据库、执行查询、把结果拿回来。不需要你手动导出数据再丢给 AI。
dbx 还提供了一个 CLI 工具:
npm install -g @dbx-app/clidbx connections list --jsondbx query local "select 1" --json这在写脚本和自动化场景里很有用。比如 CI/CD 里跑完部署后自动验证数据库连接是否正常。
桌面版直接去 GitHub Releases 页面下载对应系统的安装包:
• macOS: brew install --cask dbx• Windows: scoop bucket add dbx https://github.com/t8y2/scoop-bucket && scoop install dbx• Linux:AppImage 或 Snap,自行选择
也可以从 GitHub Releases 直接下载压缩包,解压即用。macOS 上首次打开如果提示安全问题,跑一下 xattr -cr /Applications/dbx.app。
Docker 部署也很简单,适合团队共享连接配置的场景:
docker run -d --name dbx -p 4224:4224 -v dbx-data:/app/data t8y2/dbx浏览器打开 http://localhost:4224 就是完整的 Web 版,功能跟桌面端一致。amd64、arm64 都支持,树莓派上也能跑。
用 docker-compose 的话,项目里自带了 deploy/docker-compose.yml,拿过来直接用就行。
夸了这么多,该说说不满意的地方。
• 触发器、存储过程的编辑支持还比较弱: 大部分数据库能浏览,但编辑体验跟 DataGrip 还是有差距。如果你日常大量写存储过程,dbx 目前只能算"能看不能打"。 • ER 图能力弱: ER 图虽然能生成,但只支持基础的 Chen 模型视图,没法做复杂的关系布局调整。导出也只有 SVG,不能导出 PNG。 • 插件生态还在早期: DBeaver 最大的护城河就是它的插件市场,各种数据库驱动、扩展功能。dbx 虽然有插件系统,但数量和质量都还没起来。 • 不支持数据库性能监控面板: 没有慢查询分析、没有连接池监控、没有实时 QPS 看板。如果你想在 dbx 里做 DBA 的工作,目前还不够。
不过换个角度想,15MB 的工具跟 400MB 的比功能深度,本来就不公平。dbx 的定位更像是"日常开发的数据操作终端"而不是"专业 DBA 运维平台"。
如果你跟我一样,每天在 MySQL、PostgreSQL、Redis 之间切来切去,受够了工具的启动速度和资源占用,dbx 是一个值得花十分钟装上试试的东西。它不完美,但在 "又快又小还能干活" 这个维度上,目前的开源选项里它排第一。
开源协议是 AGPL-3.0,所有功能免费。没有企业版、没有付费墙、没有功能阉割。
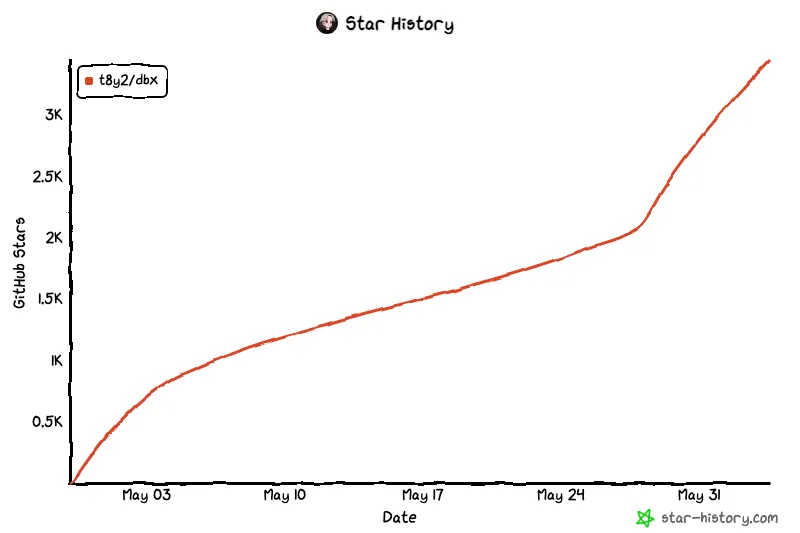
项目还在高速迭代,GitHub Issues 200 多个,Skyler 的提交频率很高,过去几个月几乎每天都有 commits。
GitHub 地址:
https://github.com/t8y2/dbx
