 夜雨聆风
夜雨聆风你有没有这种感觉——AI越用越贵?
刚开始用觉得挺划算,问几个问题几分钱。后来用多了,长对话、代码分析、写方案,月底一看账单,怎么比手机话费还高?
问题不是AI贵。是你用最贵的模型回答了最简单的问题。
就像出门买瓶水都叫专车——我之前真的是这么干的,所有问题都丢给最贵的模型,觉得"反正也不多"。直到有天翻了账单才发现,90%的问题根本不需要那么大的模型,但我每条都在为"深度推理"买单。
AI工具大部分没给你"选车型"的机会——所有问题都走最贵的模型,简单问题也用大模型推理,token就这么烧掉了。
最近我在GitHub上发现一个开源项目,专门解决这个问题。它叫OpenSquilla,核心就一句话:同样预算,让AI干更多活。
它的智能路由会自动判断问题复杂度——简单问题走便宜模型,复杂问题才上贵的。官方测试数据:3个prompt共28万token,只花了0.0094美元,其中80%命中缓存。相当于同样的事,别人花10块,它花1块。
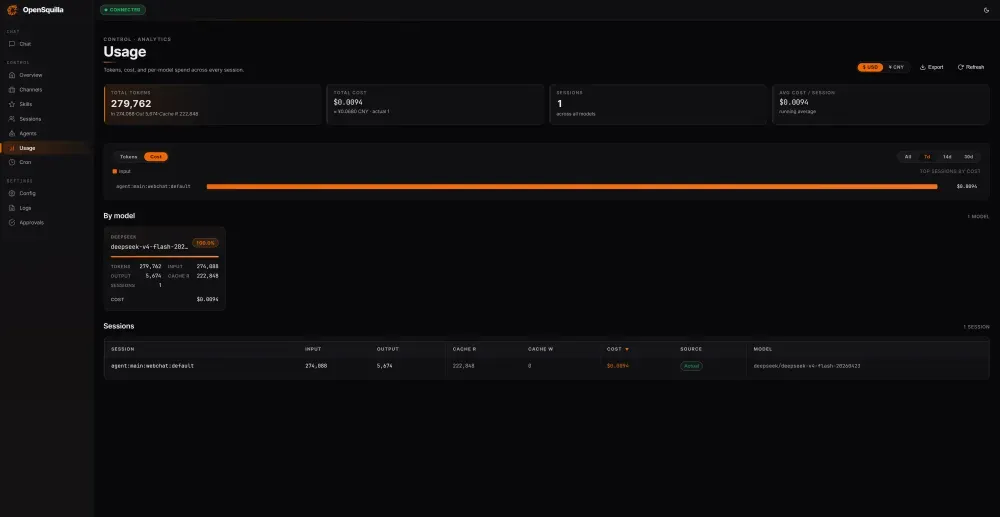
智能路由:不是所有问题都该用最贵的模型
这是OpenSquilla最核心的能力,叫SquillaRouter。
它内置了一个机器学习分类器,会自动给每个问题打分——问题短、没有代码、关键词简单,就归为"轻量级",走便宜模型;问题长、有代码块、需要深度推理,才走贵模型。
打个比方,你问"今天邵阳天气怎么样",它帮你叫经济型;你问"帮我分析一下这个代码为什么内存泄漏",它才帮你叫专车。
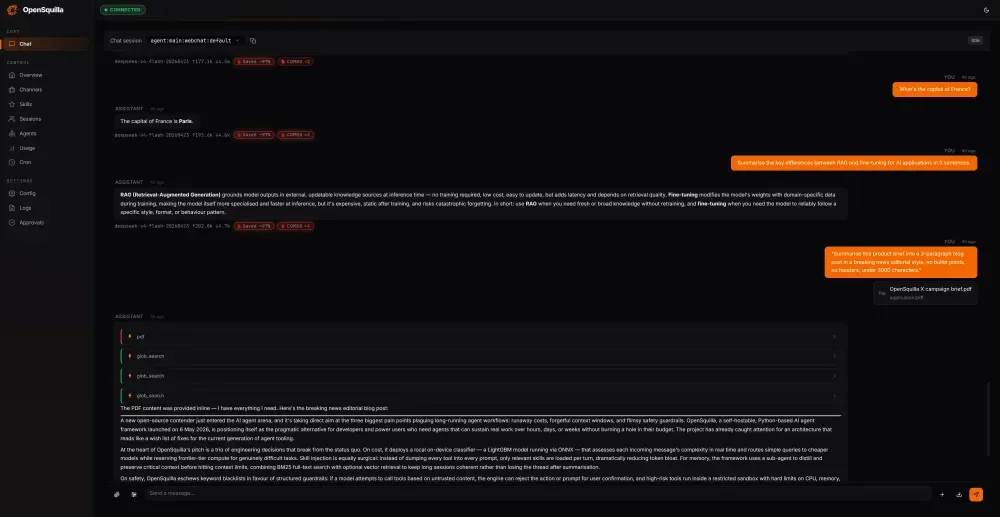
而且深度推理模式不是默认开启的。简单问题自动关掉,只有真正需要"想"的任务才开。这意味着你不会为"AI在思考但想的东西跟你无关"而买单。
官方的基准测试说综合这些策略,token开销能砍60%到80%。说实话我自己体感没到80%,但日常对话确实省了一大截,尤其是那种"问一句答一句"的轻度场景。
四层记忆:AI也该像人一样"睡觉整理"
省token不光靠路由,还得靠"别重复读"。
大部分AI工具每次对话都重新加载一遍上下文,你昨天聊过的东西,今天它又从头读一遍。读一次花一次钱,但那些上下文其实没变。
OpenSquilla的思路是,给AI装一套像人脑一样的记忆系统。四层——工作记忆、情景记忆、语义记忆、原始记忆。听着挺唬人,其实逻辑很简单:
工作记忆就是你当前在聊的事,随用随取,不额外花token。
语义记忆是你已经确认的事实和规则,比如"Python里缩进是语法"——这类东西常驻,不用每次重新学。
中间两层,情景记忆帮你回忆"上次碰到类似的bug怎么解决的",原始记忆是完整对话备份。不是每次都翻——工作记忆直接用,语义记忆常驻,只有需要细节的时候才去翻情景记忆和原始记录。
最有意思的是它有个"梦境整理"机制——每24小时自动跑一次,把散乱的对话碎片压缩成更精炼的知识。就像人睡觉的时候大脑在整理白天的记忆一样。高频使用的记忆自动"升级",长期不用的慢慢"褪色"。
MetaSkill:你说目标,它自己找工具拼流程
这是6月初刚上的新功能,也是我觉得最有想象力的部分。
以前用AI Agent,你得手动写工作流——先调A工具,再调B工具,最后调C工具。工具少了还好,工具一多,光编排流程就够喝一壶。我自己折腾过一阵,说实话经常搞到一半发现漏了个步骤,又得重来。
MetaSkill的做法是:你用自然语言说你要干什么,它自己去发现、排序、组合合适的技能,拼成一条可检查、可回放的工作流。
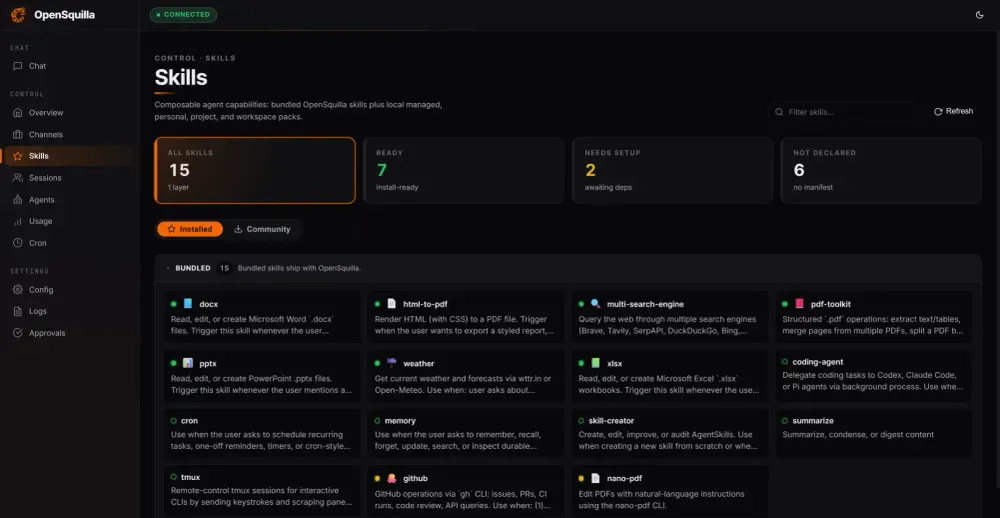
它自带的"研究→报告"和"项目规划"工作流开箱即用,而且空闲的时候会回顾自己的执行记录,把反复出现的模式提炼成新的工作流模板。
当然,自动编排也有风险——万一它组合出来一条不靠谱的流程呢?OpenSquilla的应对方式是:每个自动生成的流程都有"提案门",运行前先过验证,工具使用有白名单限制,代码执行在系统级沙箱里隔离。三道保险。但也别太放心,0.1.0版本嘛,我试的时候偶尔还是会跑偏,遇到复杂流程还是建议人工检查一下。
怎么装?三步跑起来
说了这么多,你可能想知道怎么上手。最简单的方式:
第一步:去GitHub搜"OpenSquilla"项目,进Releases页面下载最新的预览包(支持Windows和Mac)。不用装Git,不用装Python,解压就能用。
第二步:双击启动脚本,首次运行会弹一个引导界面,选你常用的AI服务商(支持OpenRouter、OpenAI、Anthropic、DeepSeek、Gemini等二十多家),填上API Key。
第三步:打开浏览器访问本地控制台,就能开始用了。
如果你是命令行用户,也可以用源码安装方式,需要Python 3.12+和uv包管理器。但个人建议先用预览包试试,跑通了再折腾源码。
⚠️ 提醒:安全沙箱在Windows上是简化模式,完整隔离要跑在Linux上。如果你要让它执行代码,建议用Linux环境。日常对话和文本处理,Mac和Windows都没问题。
值不值得试?我的判断
OpenSquilla不是万能的。它现在还在0.1.0版本,有些功能不够稳定;MetaSkill的自动编排还需要更多社区验证;官方的省token数据是自家基准测试,不是独立第三方出的。
但至少对我个人来说,它的思路是对的——不是追求更大的模型,而是追求更聪明的调度。AI的未来不一定是谁的模型最大,有可能谁最会"花小钱办大事"谁就赢。也不一定啊,说不定哪天模型白菜价了,这套省钱的逻辑就没那么重要了。
如果你每天用AI超过1小时,token账单超过50块,我建议花半小时试试。就算最后不用,"智能路由"和"分层记忆"的思路也值得借鉴——在自己的工作流里,能不能也做类似的分层?简单任务走轻量模型,复杂任务才上大模型?
线上交流 · Club 专属群,相互交流、资源互通、互助答疑
每周一次 · 线上分享——成员轮流做AI小讲师,你学会了什么就教什么,教才是真会
每月线下 · 实战工作坊——面对面,手把手,做出来才是你的
想系统学AI工具和实战技巧?公众号底部点「服务菜单」,和我聊聊吧。
大智慧AI学习俱乐部
AI 学习 · 思维进化 · 智创未来
灵境未来 · 让每个人都能用AI降本增效
