 夜雨聆风
夜雨聆风别人发来一张截图,里面明明有一大段文字。
你想复制,却发现它只是一张图片。
合同扫描件、通知截图、PDF 文件、照片里的资料,看起来都能读,但就是不能直接复制。
最后只能一边看,一边手动敲。
字少还好。
如果是一整页材料,或者几十张截图,那就真的很折磨。
很多时候,我们不是缺资料,而是资料里的文字拿不出来。
今天这个软件叫 Umi-OCR,是一款免费、开源、离线的 OCR 文字识别软件。
它有中文界面,支持 Windows 和 Linux,可以识别截图、图片、PDF 里的文字。
官网显示,Umi-OCR 目前有 41K+ GitHub Stars,支持 100 多种语言,并且可以全程离线识别。
最烦人的,是明明看得见却复制不了
办公里经常会遇到这种情况。
别人微信发来一张截图,让你照着整理内容。
资料是扫描版 PDF,看起来像文档,实际上每一页都是图片。
一张通知、一份说明、一页合同,文字明明就在屏幕上,但鼠标怎么拖都选不中。
这种时候,手动输入其实很浪费时间。
尤其是遇到数字、编号、地址、条款、名单这些内容,手打不仅慢,还容易错。
Umi-OCR 解决的就是这个问题:把图片里的文字识别出来,变成可以复制、编辑、整理的文本。
截图里的文字,框一下就能识别
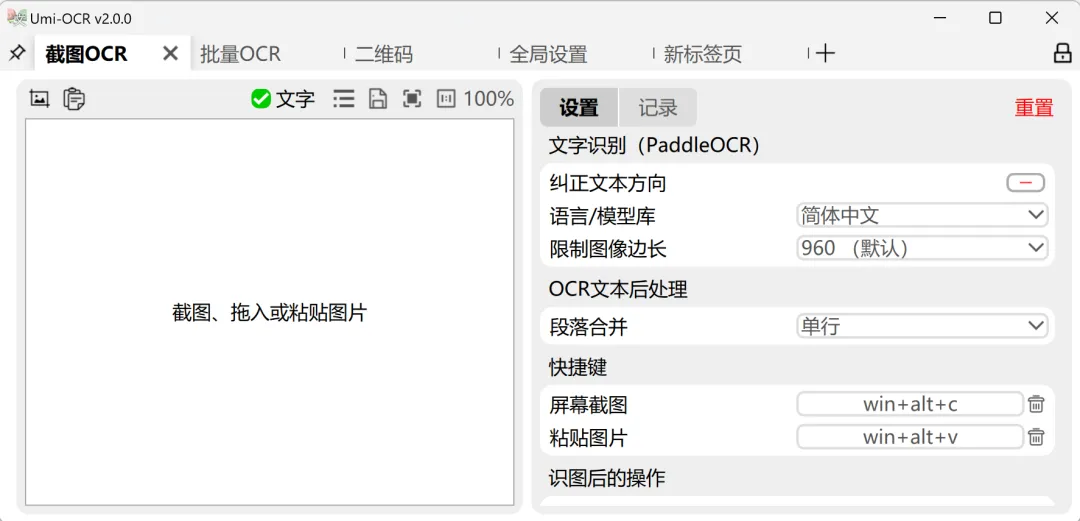
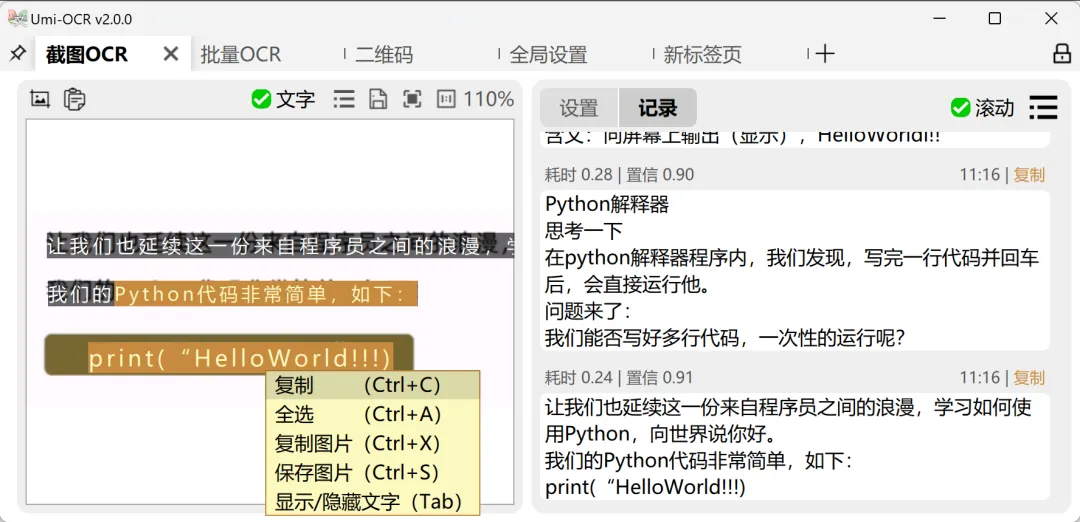
Umi-OCR 最常用的场景,就是截图识别。
看到屏幕上有一段不能复制的文字,可以直接用快捷键截图,然后识别。
识别出来的内容会出现在右侧记录里,可以复制,也可以继续编辑。
这个功能很适合处理临时资料。
比如网页里不能复制的文字。
图片通知里的内容。
聊天截图里的地址、电话、编号。
软件界面里的报错信息。
不用再对着图片一个字一个字敲,直接识别出来再整理,会省心很多。
一堆图片要处理,也不用一张张来
如果只是偶尔识别一张截图,很多软件都能做。
但真正麻烦的是批量处理。
比如一整个文件夹里都是扫描图。
几十张资料图片要转文字。
一批截图要整理成文档。
这时候一张张打开、一张张识别,就很费时间。
Umi-OCR 支持批量 OCR,可以一次导入多张图片进行识别。
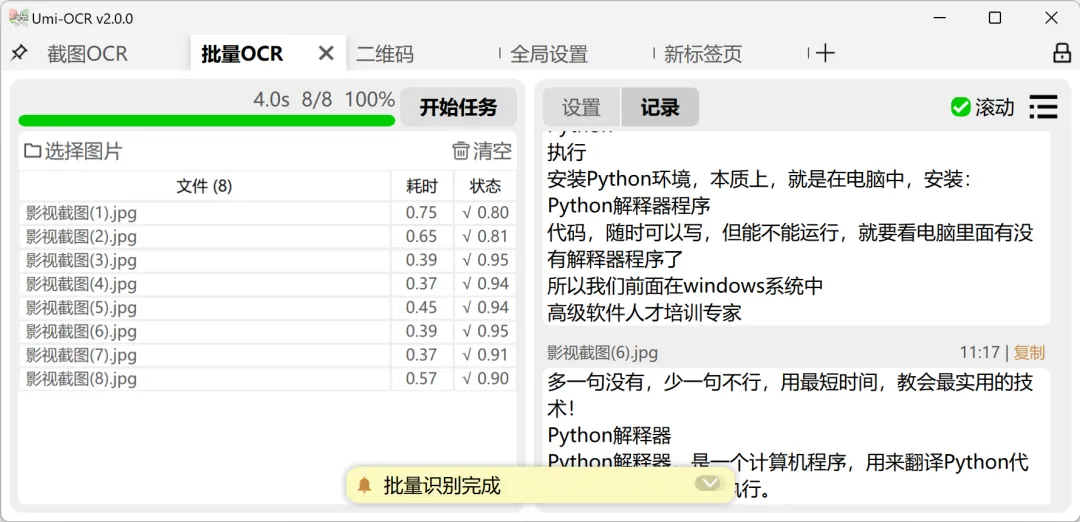
识别结果可以保存成 txt、md、csv 等格式。
如果是整理资料、汇总文本、处理扫描图片,这个功能会比单张识别舒服很多。
扫描版 PDF,也能提取文字
PDF 最烦的一种情况,就是看起来像文档,实际上不能复制。
很多扫描版 PDF 都是这样。
每一页都是图片,文字只是“看得见”,并不是真的文本。
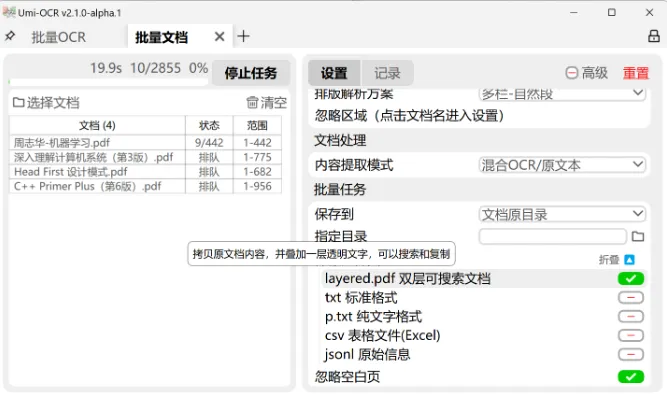
Umi-OCR 支持 PDF 识别,可以从扫描版 PDF 中提取文字。
也可以生成双层可搜索 PDF。
简单理解就是:原来的页面样子还保留着,但里面多了一层可以搜索、复制的文字。
这个场景很实用。
比如资料归档、合同查找、说明书整理、扫描件检索。
以前想找某个关键词,只能一页页翻。
处理成可搜索 PDF 之后,直接搜索会方便很多。
有水印、页眉页脚,也能避开干扰
很多图片和扫描件里,不只有正文。
可能还有水印、Logo、页眉、页脚、编号。
如果全部识别进去,结果反而会乱。
Umi-OCR 的批量识别里有一个“忽略区域”功能,可以把不想识别的区域框出来。
比如每张图片右下角都有水印。
或者每页 PDF 顶部都有重复页眉。
可以先把这些区域排除掉,再进行批量识别。
这样导出的文字会干净一些,后面整理也少很多麻烦。
不用联网,对办公资料更安心
现在很多在线 OCR 网站也能识别文字。
但问题是,你要把图片或 PDF 上传上去。
普通内容可能无所谓。
但如果是合同、票据、证件、单位资料、内部文件,就不一定适合传到网页里处理。
Umi-OCR 的一个重要卖点,是完全离线。
官网写得很明确:所有处理都在本地电脑完成,数据不会上传。
对经常处理资料的人来说,这点很重要。
不是所有文件都适合交给在线工具。
能在自己电脑上完成识别,安全感会更强。
中文界面,上手门槛低很多
Umi-OCR 本身就是中文项目,中文界面和中文说明都比较完整。
这点对国内用户很友好。
很多国外工具功能不差,但界面全英文,下载也绕,普通用户很容易在第一步就放弃。
Umi-OCR 的使用方式就直接很多。
下载发布版,解压后打开 Umi-OCR.exe 就能用。
不需要注册账号,也不需要订阅。
官方还提供了蓝奏云、GitHub、SourceForge 等下载方式。
其中蓝奏云对国内用户更方便一些。
这几种场景会经常用到
别人发来截图,想复制里面的文字。
扫描版 PDF 不能搜索,也不能复制。
图片通知、资料照片,需要整理成文字。
一批扫描图片要批量识别。
合同、票据、说明书里想快速找关键词。
二维码或条形码需要从图片里读出来。
这些需求都不复杂,但很高频。
尤其是处理办公资料时,OCR 不是炫技功能,而是实实在在减少重复劳动。
有一点要提前说清楚
OCR 识别不是百分百准确。
图片越清晰,识别效果越好。
如果图片太糊、字体太小、光线太暗,或者排版特别复杂,识别结果就需要人工检查。
另外,Umi-OCR 目前主要支持 Windows 和 Linux。
官网说明支持 Windows 7 及以上版本,Linux 支持 x64 Debian 方向。
如果你用的是 macOS,就不一定适合。
普通用户建议优先下载官方发布版,不要随便从不明网站下载改包。
项目地址 / 官网地址
官网地址:
https://umi-ocr.com/zh-CN
项目地址:
https://github.com/hiroi-sora/Umi-OCR
国内推荐下载:
https://hiroi-sora.lanzoul.com/s/umi-ocr
最后说两句
Umi-OCR 最实用的地方,不是功能看起来多复杂。
而是它解决了一个特别常见的小麻烦:
图片、截图、扫描件里的文字,终于可以拿出来用了。
能复制,就能整理。
能搜索,就能归档。
能批量识别,就不用一张张手动敲。
如果你平时经常处理截图、PDF、扫描件、资料图片,可以把它收藏起来。
觉得这类实用软件推荐有用的话,顺手点个赞和在看。
免责声明
本号推荐的软件与资源均来源于网络公开项目,仅供学习交流和效率提升参考。使用前请自行判断软件安全性、适用性和相关合规要求。如涉及侵权或不当内容,请联系删除。
