 夜雨聆风
夜雨聆风
这个县城少年没拿金牌,却让全世界的数据科学家都在用他的代码。

如果现在打开Kaggle(全球最大数据科学竞赛平台),
你会发现一个有趣的现象:
大多数冠军方案,都离不开同一个工具——XGBoost。
如果你问做AI芯片的工程师,什么技术最难绕开?
答案很可能是:Apache TVM。
2023年,AI圈有一个刷屏的项目叫MLC LLM——
它让大模型能在iPhone上离线运行,无需联网,无需云端。
这三件影响全球AI格局的大事,背后站着同一个人。
他叫陈天奇。
更让人意外的是,这位站在AI金字塔尖的科学家,
高中信息学竞赛只拿到了浙江省一等奖——
不是金牌,不是保送,只是一个“省一”。
今天,我们就来讲讲他的故事。
01
从信奥省一到上海交大ACM班
1
一个县城少年的“非典型”竞赛路
2005年11月,浙江省松阳县。一个县城中学的男孩参加了NOIP(全国青少年信息学奥林匹克联赛)。
他自学编程的起点,是一本老师送的C语言入门书。没有竞赛教练,没有集训队,只有一台电脑和一颗好奇心。
结果出来:浙江省一等奖。
放在今天,这个成绩足以让很多家长兴奋,但说实话——在信息学竞赛的金字塔里,“省一”算不上最顶尖。同期的金牌得主们大多被保送进清华姚班、MIT,而陈天奇,走了另一条路。
2
从高考到ACM班:一份“最用心”的申请材料
2006年夏天,他通过普通高考,考进了上海交通大学电子信息与电气工程学院。
命运的转折发生在一个偶然的瞬间。填志愿前后,他无意中看到一篇报道,介绍交大的ACM班。
这个班是俞勇老师创办的本科特班,每年只从全校挑30人左右。目标只有一个:培养科学家。
从这个班走出过谁?戴文渊(ACM世界冠军、第四范式创始人)、李沐(CMU博士、《动手学深度学习》作者、亚马逊首席科学家)……
陈天奇看完所有能查到的资料,心里只有一个念头:我想去。
开学后,他认真准备了一份申请材料,递交给俞勇老师。后来俞老师回忆说,那一届所有学生的申请材料里,陈天奇那份是用心程度最高的。
他被录取了,成为ACM班2006级的一员。
3
“从零开始”的硬核训练
在ACM班,他经历了真正“硬核”的训练。有一门大作业:从零开始搭建一个编译器。
当时他们连编译原理课都还没上过,完全从零摸索。学长们手把手指导,这种“传帮带”的传统,让他后来念念不忘。
“ACM班教会我的是:只要有正确的方法论,就没有解决不了的难题。”他说。
本科高年级,他跟着学长戴文渊开始接触机器学习。那是2009年,离ChatGPT还有十多年,“深度学习”这个词在国内学术圈还没几个人挂在嘴边。
但种子已经埋下。
02
AI圈里的三件大事:XGBoost、
Apache TVM和MLC LLM
01
第一件:XGBoost—让数据科学竞赛“没它不行”
2013年,陈天奇远赴美国,进入华盛顿大学攻读博士学位,师从机器学习领域顶级教授Carlos Guestrin。
读博第二、第三年,他遇到了一个问题。
当时工业界处理数据问题,最常用的模型叫梯度提升树(GBDT)。这个模型效果好,但跑得慢,尤其在数据量大的时候,效率让人抓狂。
别人的做法是:等工具优化,或者忍一忍。
陈天奇的做法是:嫌慢?自己写一个。
于是,他花了大量时间,从头实现了一个全新的梯度提升树工具。他把算法底层重写,做了缓存感知优化、正则化改进,甚至内置了缺失值处理——用户拿来直接用,不用预处理数据。
这个工具,他给它起名叫 XGBoost。
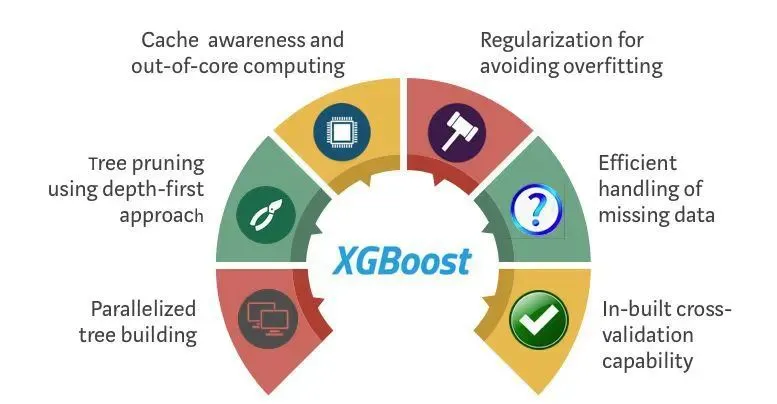
后来的故事,很多人都知道了。
XGBoost跑得比现有工具快得多,也稳定得多。它迅速在全球数据科学竞赛平台Kaggle上蔓延开来。结构化数据竞赛的金牌方案里,绝大多数都用到了XGBoost。
它不再只是一个工具,而成了行业基础设施。
2016年,陈天奇和导师把XGBoost写成论文,发表在数据挖掘领域顶会KDD上。到今天,这篇论文的引用次数已经超过3万次。
这是什么概念?在计算机领域,引用过万就是“里程碑级”的工作。
一个中国县城走出来的年轻人,凭一己之力,改写了全球数据科学家的工具链。
XGBoost是陈天奇的第一个重磅作品,但远不是最后一个。
02
第二件:Apache TVM—让AI模型适配任何硬件
读博后期,陈天奇又发现了一个痛点。
深度学习的框架越来越多——TensorFlow、PyTorch、MXNet……你训练好一个模型,想把它部署到不同硬件上跑,简直是一场噩梦:英伟达GPU要一套配置,苹果M系列芯片要另一套,华为昇腾又要改代码。
陈天奇的解决方案是:写一个编译器,自动搞定适配。
这就是TVM(深度学习编译器)。你训练好模型,TVM帮你自动翻译、优化、生成,它能在任何硬件上高效运行。
后来TVM进入Apache基金会孵化,成为Apache TVM。
今天硅谷一大半AI芯片创业公司,都在TVM的代码基础上做开发。
2019年博士毕业后,陈天奇和实验室同事将TVM商业化,创办了OctoML(后改名OctoAI),他出任CTO。2020年,他加入卡耐基梅隆大学(CMU),任机器学习系和计算机科学系助理教授。
2024年9月,OctoAI被英伟达收购。这是后话。
03
第三件:MLC LLM—让大模型在iPhone上离线跑
到CMU之后,陈天奇做了个“出圈”的项目——MLC LLM。
2023年大模型热潮席卷全球,但几乎所有大模型都要联网。
陈天奇想:能不能让大模型离线跑在手机、笔记本上?
他带着团队做到了。
MLC LLM发布后,开发者可以在自己的iPhone上离线跟一个70亿参数的大模型对话。不需要联网,不需要云端,隐私安全,速度飞快。
这件事在AI圈引起巨大反响。有人评论:“他让大模型从云端落到了每个人的口袋里。”
XGBoost改变了数据科学,TVM改变了AI芯片生态,MLC LLM改变了大模型的部署方式。
三件大事,贯穿十几年,背后是同一个人的名字。
03
一路生花的信奥底色
1
竞赛给他的,不是金牌,而是一种“底层能力”
回顾陈天奇的成长轨迹,你会发现一个有趣的规律:
他做的每一件大事,都不是“跟风”,而是“解决真问题”。
这种能力的源头,可以追溯到他的信奥经历。
信息学竞赛训练的是什么?不是背语法,不是刷套路,而是问题拆解能力、算法思维、工程实现能力。
陈天奇高中时就敢手写编译器(把Pascal转成C),虽然过程痛苦,但这让他早早明白:
计算机世界里没有魔法,一切都可以从头搭建。
2
失败也是底色的一部分
很多人不知道,陈天奇本科做科研时,曾经两年半没有突破。他同时纠结问题的重要性和方法的创新性,结果卡住了很久。
但他后来总结:
“那些‘浪费’的时间,都是必要的积累。科研的本质就是在未知领域探索,失败是必然的。”
他还说过一句话,特别适合送给正在学编程的孩子:
“做平庸问题和重要问题花的时间几乎一样,所以一定要挑正确的问题。”
3
在CMU,他延续了ACM班的教学理念
如今在CMU教书,他开的课叫“深度学习系统”——让学生从零搭建一个完整的深度学习库。
这和当年ACM班的大作业如出一辙。
这就是信奥底色
“不是因为学了编程所以厉害,而是因为编程教会了他们怎么思考、怎么坚持、怎么在不确定中找到出路。”

陈天奇的故事告诉我们一个朴素的道理:
孩子的未来,不取决于一张证书是金牌还是银牌,而取决于他有没有解决问题的能力。
信奥省一,不是终点,只是一个起点。
如果你家孩子正在学编程,正为了某场比赛焦头烂额,不妨想想陈天奇——那个县城少年,没有金牌,没有保送,却用一行行代码,改变了全球AI的格局。
真正决定一个人能走多远的,从来不是起跑线,而是他心里的那条终点线。
高途编程成长中心
干货分享、竞赛规划
编程学习资料、赛事指南
欢迎扫码关注编程君




