 夜雨聆风
夜雨聆风继续看【文档智能】解析,继《多模态文档智能解析开源进展:针对形变文档优化的PaddleOCR-VL-1.5架构改进点》开源后,优图又开源一个多模态文档解析模型-Youtu-Parsing-2.5B,这是一个以多模态视觉语言模型为基础的pipeline结构(即:vlm既做layout版式分析又做ocr Format识别),并使用高并行性解码策略解决传统文档解析中 “自回归解码速度慢、多区域处理冗余” 两大痛点,其目标是在不损失识别精度的前提下,通过 “token级并行 + 区域级并行” 的协同,提升文档解析的吞吐量。
功能上,相较于以往的模型,增加了几个小功能,如下:

另外,还增加了文档层次结构分析的功能,明确元素间的逻辑关联-子父、分组、内容延续,修复物理布局导致的语义断裂(如“跨列的连续文本”)。

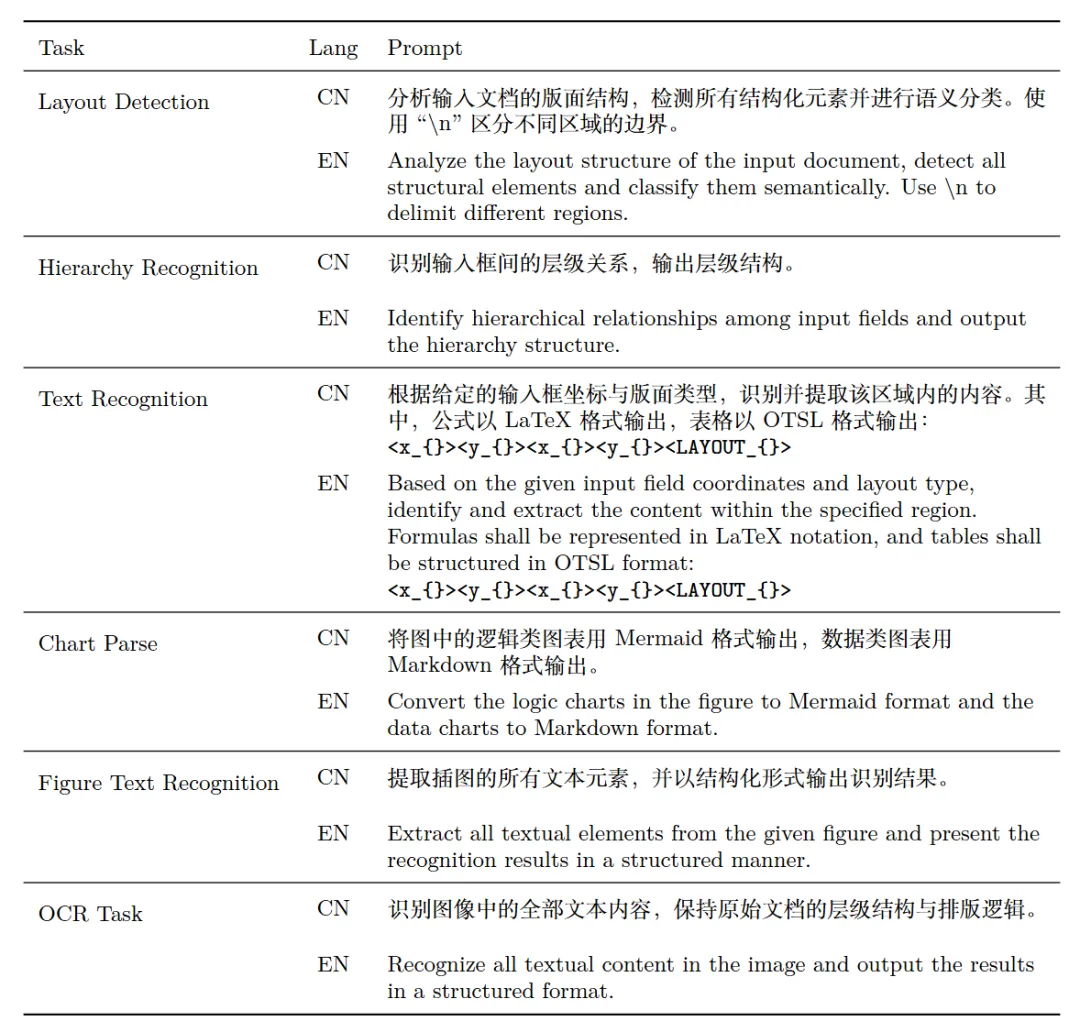
用于各个子任务的提示词如下 :
高并行性解码策略概述
传统文档解析(如OCR、表格/公式识别)依赖自回归解码,其核心问题是:
序列生成效率低:Token,如字符、符号需逐一生成,每步仅能生成1个token,面对长文本(如表格、多列文档)时 latency 极高; 多区域处理冗余:传统VLMs需按顺序处理文档中的多个元素(如文本块、表格、公式的边界框),重复调用模型导致计算冗余。(ps:这点可能是为了写论文需要,其实可以在工程侧进行优化,比如借助VLLM框架进行batch推理提升吞吐量)。
解决方式分token并行和Query并行:
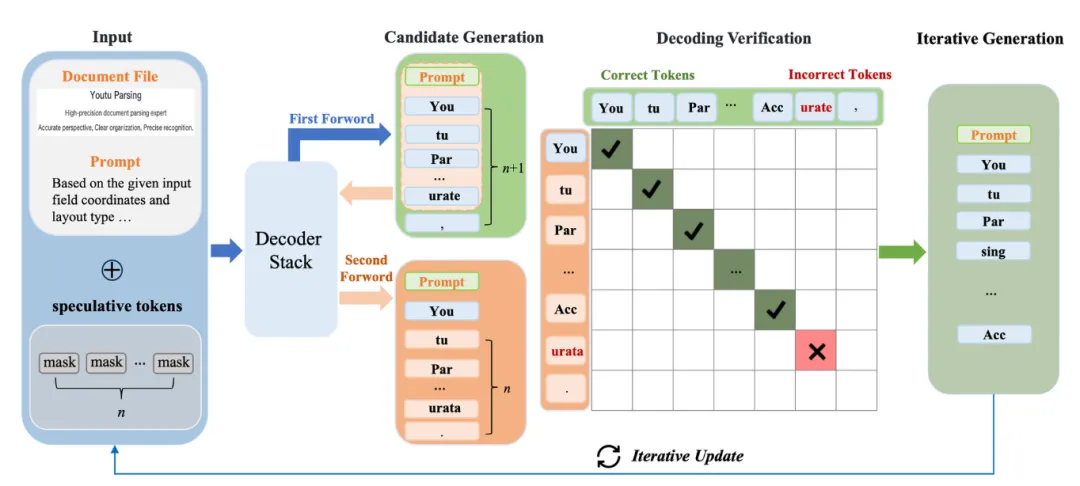
Token Parallelism:不逐一生成文档里的字符/符号,一次批量生成多个候选(最多64个),再验证哪些和逐一生成的结果一致,只保留正确的,既加快单个内容块(比如表格、一段文本)的解析速度,又不丢精度。输入构造:在当前上下文序列(含视觉嵌入、系统指令、已生成token)后,追加 n 个特殊的 < mask > token(默认 n=64),形成增强输入:
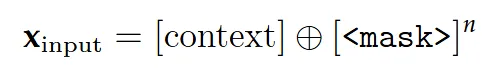
Query Parallelism:不逐个处理文档里的多个独立元素(比如多个文本块、公式、表格),一次打包处理多个(最多5个),减少重复调用模型的冗余,在Token Parallelism的基础上进一步提速。Query Parallelism 在 “短文本密集型文档”(如幻灯片、表单、结构化报告)中效果显著。
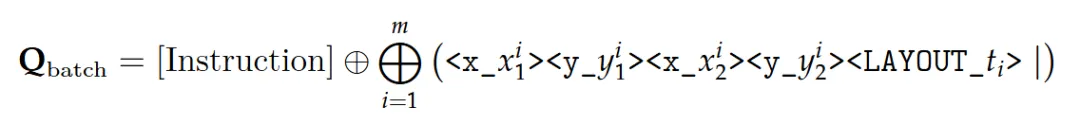
模型架构
模型架构与youtu-vl类似,经典的vlm结构:
vit(采用NaViT风格的ViT,参数规模为0.4B;集成动态分辨率预处理模块,可适应不同尺寸的文档图像(如扫描件、多列论文、幻灯片),输出多尺度、高保真的视觉特征图,且特征图为后续所有任务共享,避免重复计算)+两层MLP+LLM(Youtu-LLM-2B)
共分三个阶段处理:
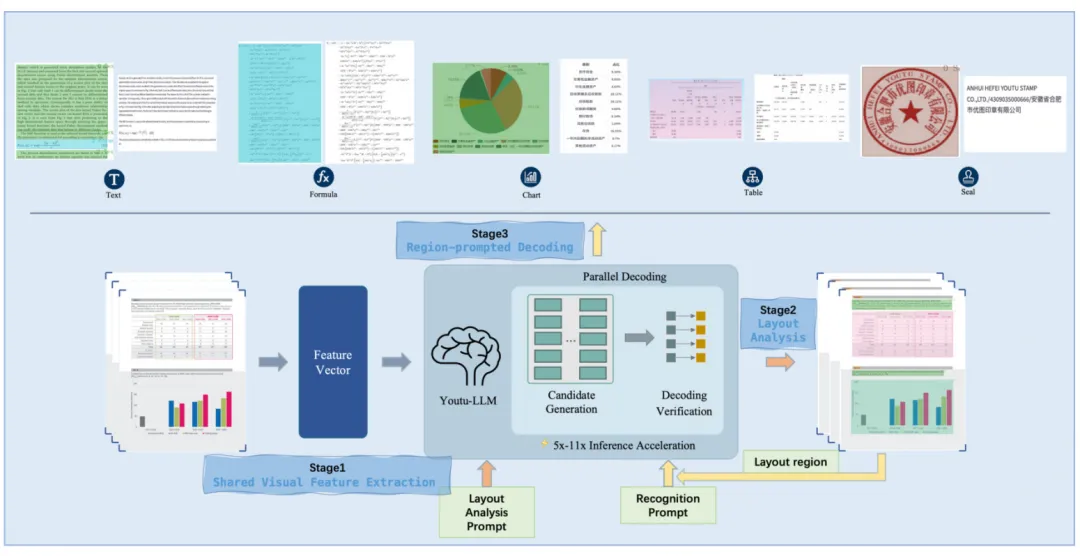
阶段1:共享视觉特征提取
输入原始文档图像(如PDF页、扫描件),NaViT编码器对图像进行全局扫描,生成统一的共享特征图,为后续“布局分析”和“区域解码”复用,无需重复编码;输出多尺度、高分辨率的视觉特征图(为全流程提供基础特征支撑)。
阶段2:版式分析
输入共享视觉特征图 + 任务指令提示(如“识别文档中的表格、公式、文本块”);处理逻辑:Youtu-LLM-2B结合视觉特征进行跨模态空间推理,完成两项核心任务:
语义分类:判断文档元素的类别(如文本块、表格、公式、图表、印章、层级结构); 定位:预测每个元素的边界框坐标(x₁,y₁,x₂,y₂),确保元素位置精准;
输出:包含“边界框坐标+语义类别”的文档元素列表(如「(x₁,y₁,x₂,y₂), TABLE」「(x₃,y₃,x₄,y₄), FORMULA」)。
阶段3:区域提示解码
输入上一步结果,有三点处理逻辑:
特征检索:根据区域提示的坐标,从共享特征图中提取该元素的目标视觉特征; 类别适配:针对不同元素类型(如公式→LaTeX格式、表格→OTSL格式、文本→纯文本),注入类别特定提示,避免不同元素的格式干扰; 细粒度识别:Youtu-LLM-2B基于目标特征与类别提示,生成结构化结果(如LaTeX公式代码、OTSL表格结构、纯文本内容);
输出:每个文档元素的结构化解析结果。
训练方法
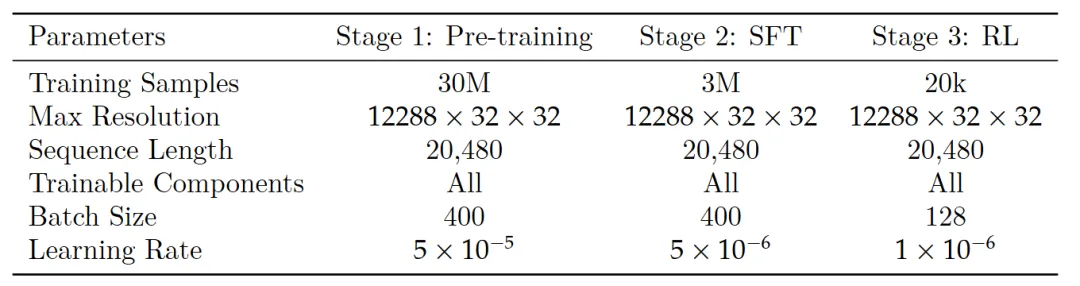 如上表,训练分三个阶段:预训练(Stage 1)- 监督微调(Stage 2)- 强化学习(Stage 3):
如上表,训练分三个阶段:预训练(Stage 1)- 监督微调(Stage 2)- 强化学习(Stage 3):
阶段1:预训练
通过大规模数据训练,让模型掌握文档的基础视觉特征与通用语言规律,使用30M OCR-centric样本,覆盖多种文档类型(如学术论文、表单、扫描件),确保数据多样性。引入几何变换(如旋转、裁剪)、噪声注入(如模糊、光斑)等操作,提升模型对低质量、变形文档的鲁棒性。
阶段2:监督微调(SFT)—— 适配文档解析任务
基于预训练模型,通过专家标注数据微调,适配“布局检测、文本识别、公式/表格/图表解析”等场景需求。使用3M标注数据,标注信息包括“元素边界框、语义类别(文本/公式/表格等)、结构化输出格式(如LaTeX公式、OTSL表格)”。
布局检测:预测文档元素的空间坐标,支持阅读顺序重建; 文本识别:适配多字体、复杂背景下的文字提取; 公式识别:将数学表达式映射为标准LaTeX格式; 表格识别:采用优化表格结构语言(OTSL)解析表格拓扑与内容; 图表识别:将条形图、折线图等转化为结构化表格或Mermaid语法。
阶段3:强化学习
通过GRPO强化学习进一步优化模型输出,减少“幻觉(生成错误内容)”,确保输出符合人类对文档结构、语义完整性的预期。使用20K高复杂度文档样本(如嵌套表格、多列公式、手写批注文档),聚焦模型易出错的场景。
针对不同解析任务设计差异化奖励,确保模型在各维度均达标:
布局分析:基于“预测与真实边界框的最优二分匹配IoU”评分,奖励几何精度; 表格识别:结合“归一化编辑距离(文本准确性)”与“树编辑距离相似度(TEDS,结构完整性)”,惩罚内容错误与结构幻觉; 公式识别:从“字符编辑距离、结构骨架相似度、符号Jaccard重叠、分隔符一致性”4个维度评分,确保公式语法与语义正确。
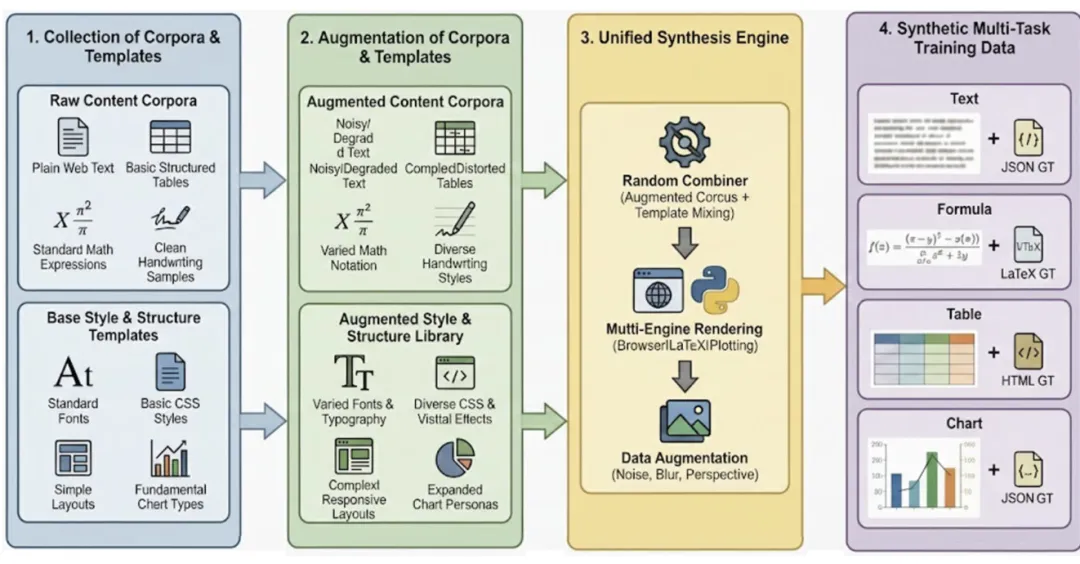
数据引擎
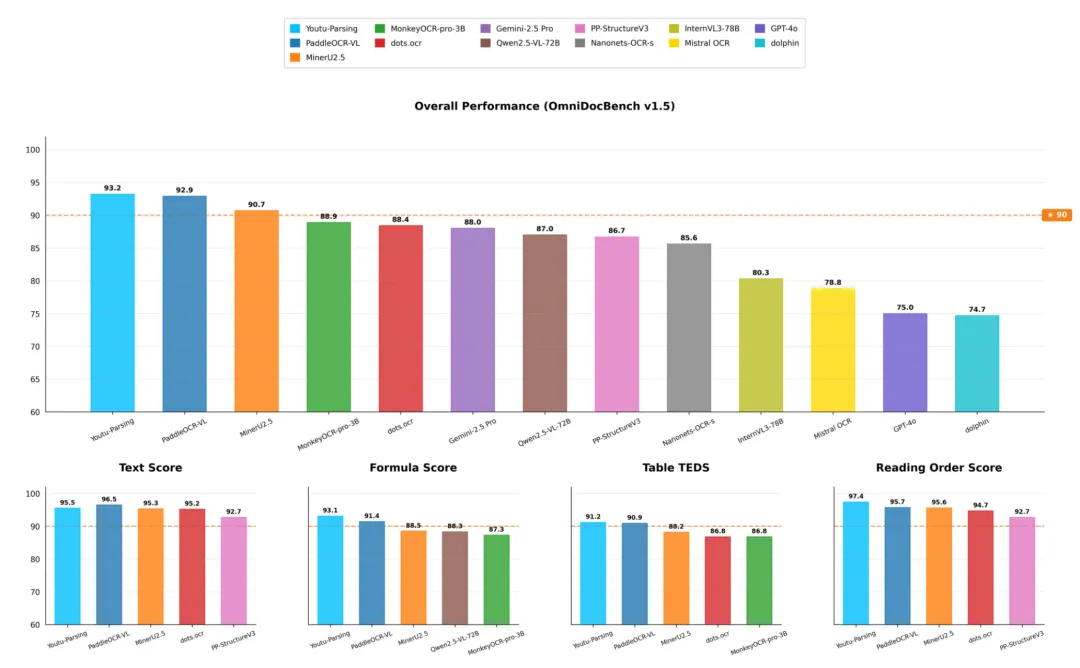
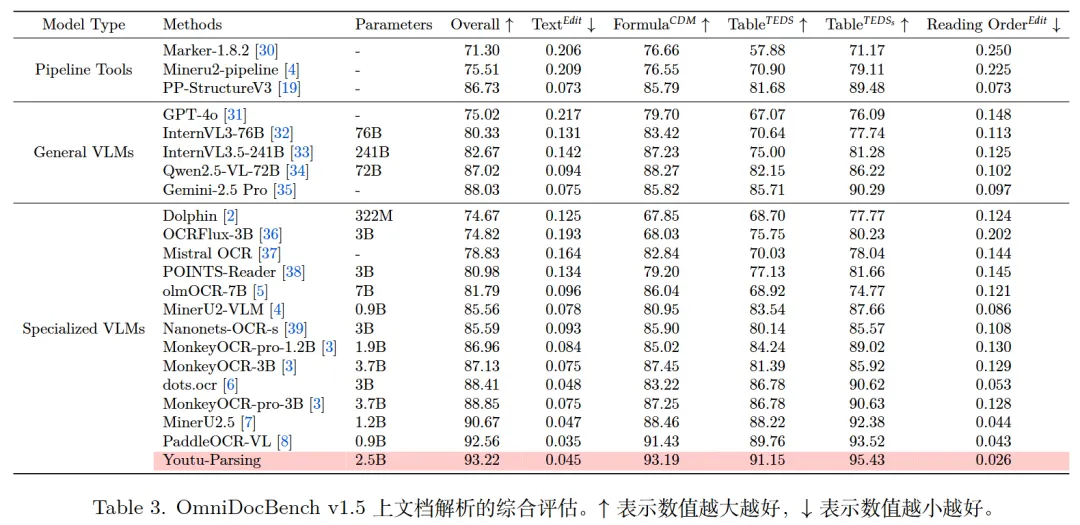
实验性能
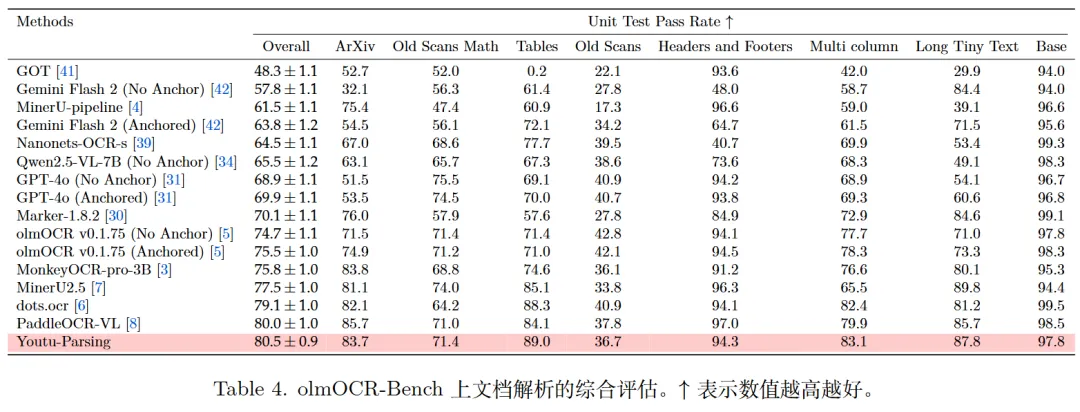
参考文献
Youtu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding,https://arxiv.org/pdf/2601.20430
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
再看两阶段多模态文档解析大模型-PaddleOCR-VL架构、数据、训练方法 多模态文档智能解析开源进展:针对形变文档优化的PaddleOCR-VL-1.5架构改进点 如何打造一个文档解析的多模态大模型?MinerU2.5架构、数据、训练方法 端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法 多模态文档解析模型新进展:腾讯开源HunyuanOCR-1B模型架构、训练配方 强化学习GRPO(格式奖励)在多模态文档解析中的运用方法 多模态文档解析开源新进展-DeepSeek-OCR2.0架构、数据、训练方法
...
