夜雨聆风
夜雨聆风智能体元年:一篇讲清楚 Agent 到底是什么?上一篇我们用冯·诺依曼架构画了 Agent 的全景图,把 LLM、编排、记忆、MCP、Tool/Skills 的关系理清楚了。其中"记忆"被映射为存储器,短期是上下文窗口,长期是向量库。
那一小节写得很克制,因为 context 这个话题太大了。这篇就从一个日常的小场景开始。你跟 Agent 聊了一周的项目细节,某天它突然问你"你的项目是什么方向来着?"你愣住了,明明上周聊了两个小时,它怎么全忘了?这不是 bug,是 context 在作怪。context 管理决定了 Agent 每次和你对话时,脑子里装的是什么、装多少、装多久。长期记忆、遗忘机制这些更大的话题先不展开,这次只聚焦一个问题:每次对话开始前,Agent 怎么拼出自己的上下文?
从 Prompt Engineering 到 Context Engineering
2025 年,Context Engineering 的概念开始成形。Shopify CEO Tobi Lutke 发了一条推,把它定义为:
Context Engineering is the art of providing all the context for the task to be plausibly solvable by the LLM.
一周后 Karpathy 转发力挺,给了一个更精确的定义:
The delicate art and science of filling the context window with just the right information for the next step.
紧接着 Anthropic 在 2025 年 9 月发了一篇工程博客,正式把 Context Engineering 定义为:
The set of strategies for curating and maintaining the optimal set of tokens during LLM inference.
这三个定义说的是同一件事:你怎么组织 LLM 在每次推理时看到的那堆信息。
Prompt Engineering 和 Context Engineering 的关系很简单:
| 关注什么 | ||
| 范围 | ||
| 谁在做 | ||
| 生命周期 |
打个比方, Prompt Engineering 是写一封信,Context Engineering 是管理整个办公室的信息流。信怎么写当然重要,但如果办公室里堆满了废纸,或者关键文件锁在抽屉里找不到,你信写得再好也没用。
Context Engineering 是 Prompt Engineering 的升级和扩展。 Prompt Engineering 关注的是"怎么写指令",Context Engineering 关注的是"整个上下文窗口里该放什么、不该放什么"。在生产级 Agent 系统里,你精心写的那段 prompt 指令可能只占 context 的一小部分(在复杂场景下有时低至 5%),剩下的大部分是系统动态拼装进来的。
Context 到底包含什么?
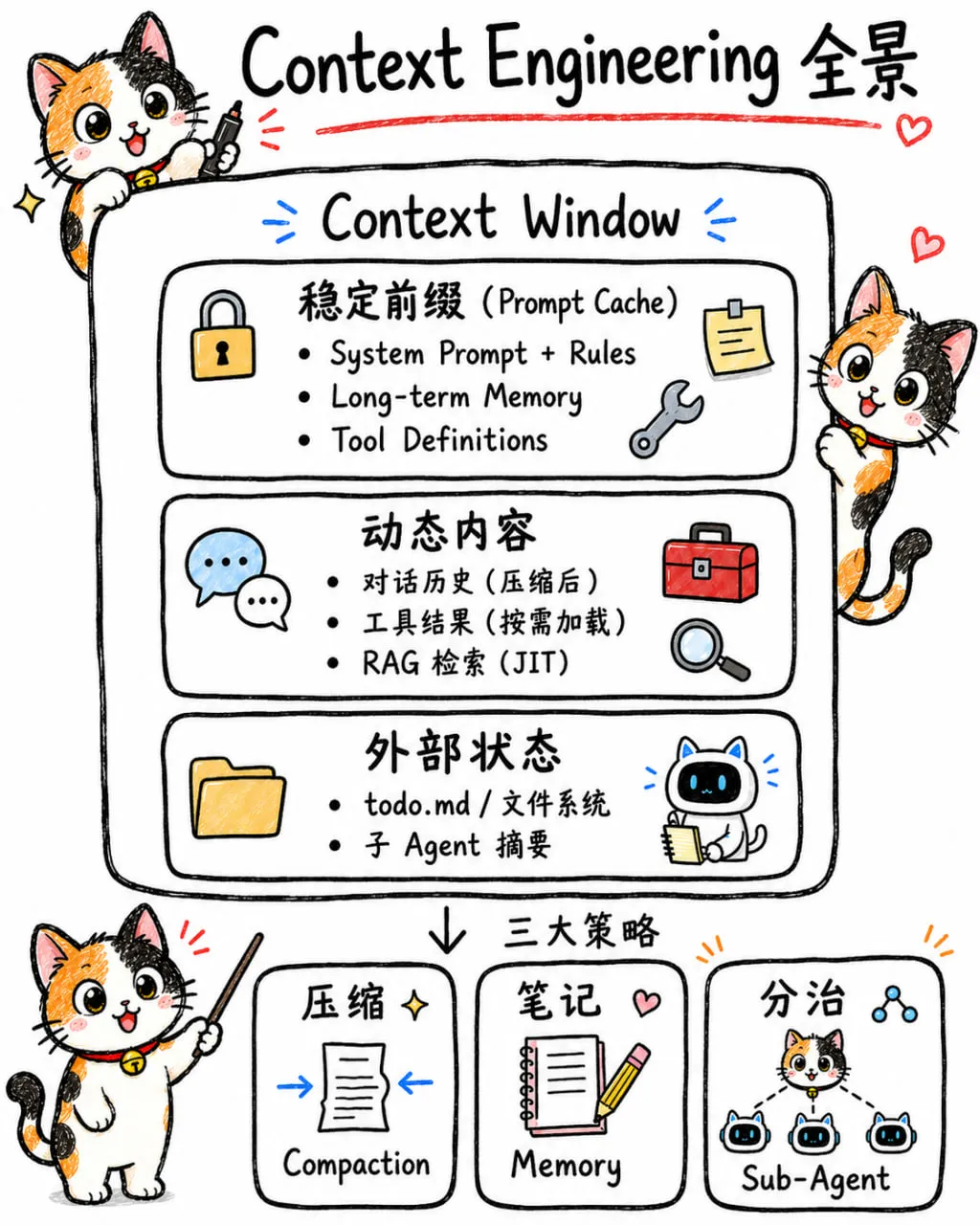
先搞清楚一个基本问题:Agent 每次调用 LLM 时,context window 里到底塞了哪些东西?
| System Prompt(人设 + 规则 + 工具说明) | ||
| Long-term Memory(跨会话记忆) | ||
| Skills / Tool Definitions | ||
| Conversation History | ||
| Tool Results | ||
| JIT Loaded Content |
这张表里的占比是动态的。一次简单问答,system prompt 可能占 80% 以上。但在长对话 Agent 里,对话历史和工具结果会吃掉大部分空间。Context Engineering 的核心就是管理这种动态性。
三大策略
| 压缩(Compaction) | |||
| 笔记(Memory) | |||
| 分治(Sub-Agent) |
这三个策略不是互斥的。实际系统里通常是三者组合使用。
代码实例:nanobot 的 ContextBuffer
我自己的项目 nanobot 里有一个 SimpleContextBuffer 类,它完整实现了"压缩"策略中的滑动窗口 + orphan 清理。这是 Context Engineering 在代码层面的最直接体现。
核心流程分三步走:
| 1. 滑动窗口 | ||
| 2. 对齐到 user | ||
| 3. 清除 orphan |
代码实现就几十行:
classSimpleContextBuffer:def__init__(self, max_messages:int=50): self.max_messages = max_messages self.messages:list[dict]=[]defadd(self, message:dict)->None: self.messages.append(message) self._trim()def_trim(self)->None:# 没超上限,不动iflen(self.messages)<= self.max_messages:return# Step 1: FIFO 滑动窗口,保留最近 N 条 retained =list(self.messages[-self.max_messages:])# Step 2: 对齐到第一条 user 消息 retained = self._anchor_to_user(retained)# Step 3: 清除 orphan tool result retained = self._strip_orphan_tool_results(retained) self.messages = retaineddef_anchor_to_user(self, messages:list[dict])->list[dict]:"""窗口从第一条 user 消息开始"""for i, m inenumerate(messages):if m.get("role")=="user":return messages[i:]return messagesdef_strip_orphan_tool_results(self, messages:list[dict])->list[dict]:"""清除悬空的 tool result(mark-and-sweep 风格)""" declared:set[str]=set() orphan_boundary =0for i, msg inenumerate(messages): role = msg.get("role")if role =="assistant":for tc in msg.get("tool_calls")or[]:ifisinstance(tc,dict)and tc.get("id"): declared.add(str(tc["id"]))elif role =="tool": tid = msg.get("tool_call_id")if tid andstr(tid)notin declared:# 找到 orphan,把之前的内容全丢掉 orphan_boundary = i +1 declared.clear()return messages[orphan_boundary:]orphan 是什么?为什么需要清理?
Agent 对话里有一条隐式的依赖链:

这里的 tool_call_id 就是外键,指向 assistant 消息里的 tool_calls[].id。
当滑动窗口淘汰了最旧的消息,可能出现这种情况:
# 窗口保留了最近 3 条[0] tool: 文件内容是 ... ← tool_call_id="call_old" 但 call_old 已被淘汰[1] assistant: 基于结果我推断 ← 它引用了 tool 的结果[2] user: 继续说第 0 条 tool 消息的父级 call_old 已经不在窗口里了,LLM 看到它时会困惑:这个结果是谁返回的?这就是 orphan(孤儿)。
_strip_orphan_tool_results 做的就是 mark-and-sweep:先扫描一遍,mark 所有 assistant 声明的 tool_call_id;再扫第二遍,sweep 掉那些没有对应声明的 tool 结果。
为什么这算 Context Engineering?
这段代码回答了三个问题:
| 给它看什么? | |
| 不给它看什么? | |
| 什么时候不给? |
这就是 Context Engineering 在代码层面的本质:不是什么高深的理论,就是用代码回答"放什么、不放什么、什么时候放"这三个问题。
三个级别、三种方案的完整对比继续往下看。
三个级别,三种方案
轻量级:滑动窗口 + 文件存储
适合个人助手、简单对话场景。

成本:零额外基础设施,纯文件系统。
工程级:异步摘要 + 动态 RAG
适合中型项目、团队内部工具。

成本:需要向量数据库 + embedding 模型。
工业级:Claude Code / Manus 方案
适合生产级 Agent 产品。

成本:需要完整的 Agent 基础设施。
总结
回到开篇的问题:Agent 的真正瓶颈是什么?
不是模型的智力。GPT-4、Claude、Gemini 各有所长,但它们的能力天花板已经足够解决大多数任务。瓶颈在 context。你决定给它看什么、不给它看什么、什么时候给它看,这些选择直接决定了 Agent 的表现上限。有一个实在的体感可以分享,AI coding 用久了之后,我越来越有种和代码隔离的感觉。代码在逐渐脱离我的掌控,而我越来越像一个"prompt 管理员"在优化指令、优化 skills,甚至这些优化本身也可以交给 AI 反复迭代。这件事说不上糟糕,但也不是理想状态。也许,我们需要换一种视角来重新理解 AI 开发这件事。而从开发到产品,又是另一段距离。
回到开头,下次和agent聊天的时候,可以思考思考,现在智能体的脑子里装的,是哪几层东西?甚至,还可以构建skills,让它像我们一样具备遗忘。也许这也是不错的方向。
下一篇聊编排层:ReAct 循环在工程实践中到底踩了哪些坑。
一张图总结