 夜雨聆风
夜雨聆风我在团队知识库里搜"某高频接口"——0 条命中。
切到本地工作目录,那份完整调试报告就躺在那里,写于上个月。
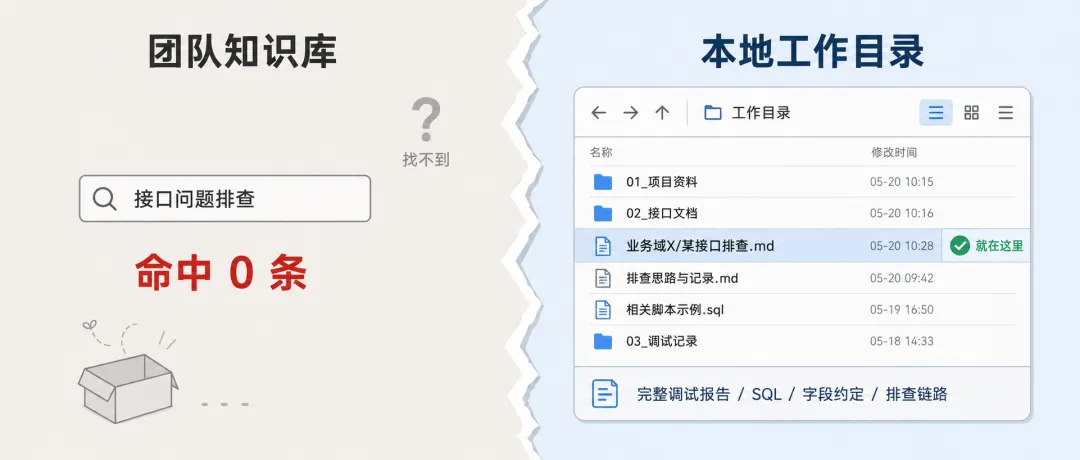
这个瞬间让我意识到一件事:知识明明有,只是没进知识库。AI Agent 再聪明,它也只能找到已经入库的东西。你喂给它的原料本身就没整理好,它怎么可能给你正确的答案?
这篇讲的就是我如何从"搜不到东西"出发,把团队层和个人层的知识库一起重做了一遍。全文给你我实际跑出来的诊断数据、标签设计方案、经验沉淀模板,以及 P0-P3 的执行节奏——可以今晚就动手。
我给知识库做了一次体检,结果让人沉默
先量化问题,不量化就改不动。
我对知识库做了一次完整探测:892 条内容,20 个高频关键词抽样搜索,命中率只有 20%。
逐项看下去,问题成片成片的:
#标签 过滤问答,但覆盖率接近 0%——1045 条里只有 1 条有标签 | ||
最让我崩溃的发现:仓库本地 归档/某业务模块/ 里有完整的调试报告,某客户/某报错案例/ 里有实际案例——这些东西就在硬盘上,但知识库里搜不到。
四红一黄一绿。分类结构没坏,塌方的是入库与过滤两端。
我做的第一个决定:先改架构,不补内容
很多人第一反应是"赶紧把缺失的内容补进去"。我做了一个相反的决定:先改架构。
原因很简单——补内容是无底洞,改架构是有限工程。
今天补 20 条 FAQ,明天又会冒出新的缺失。但如果入库通道和标签体系搭好了,新增内容自然会沿着管道流进来。
我设计的架构是双层的:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line┌─────────────────────────────────────────────────┐│ 团队层(某 SaaS 知识库平台) ││ - 全员可查 ││ - 产品手册 / 表结构 / FAQ / 接口文档 ││ - 标签体系:客户 + 知识类型 + 业务域 + 版本 ││ - 入口:电脑端 / 手机小程序 │└─────────────────────────────────────────────────┘↑ 经验上行↓ 知识下行┌─────────────────────────────────────────────────┐│ 个人层(本地文件夹 + AI Agent 消费) ││ - 仅自己使用 ││ - 暂存区 → 业务域分类 → 经验沉淀 ││ - 给 Claude Code / Cursor 等 Agent 用 │└─────────────────────────────────────────────────┘
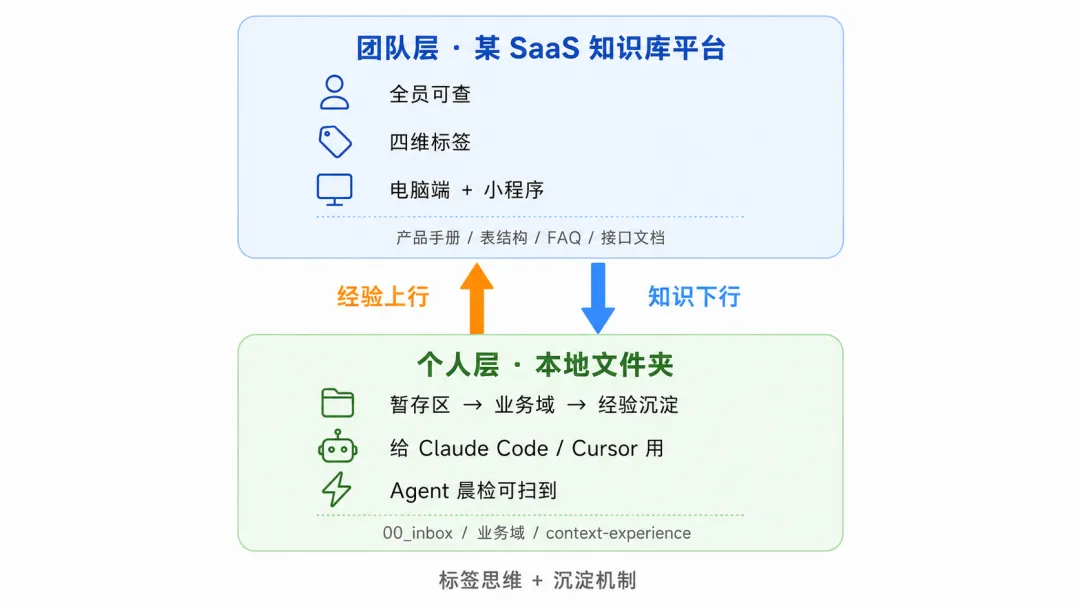
两条边的读法:
知识下行:团队层的产品手册、表结构是个人层的参考依据 经验上行:个人层的经验沉淀是团队层 FAQ 的源头水管
底层的共性就四个字:标签思维,加上沉淀机制。下面分开讲。
团队层:让上千条文档变得"搜得到"
一个关键判断:文件夹管大结构,标签管过滤维度
文件夹结构本身没坏——按版本、按模块分,逻辑是对的。真正的问题是没有标签。
我们用的知识库平台原生支持 #标签 过滤问答:提问时带 #客户A,AI 只返回该标签下的内容。但 1045 条内容里只有 1 条有标签,这意味着平台最强大的过滤能力完全闲置。
标签怎么设计
我设计了四个标签维度,原则很简单:文件夹路径已经表达的信息,标签不重复。标签只管跨文件夹过滤。
#客户A#客户B#通用 | |||
#产品配置#FAQ#SQL#接口文档 | |||
#系统A#系统B#系统C#业务域X#场景Y | |||
#v1.0#v2.0#v3.0 |
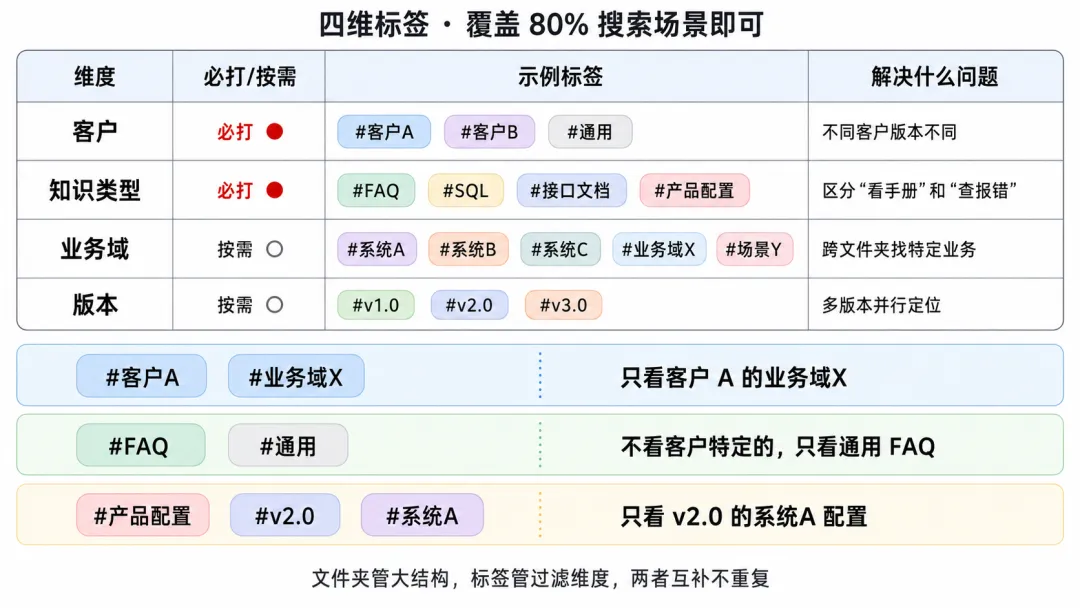
激活后的效果:
ounter(lineounter(lineounter(line#客户A #业务域X ← 只看客户 A 的业务域X#FAQ #通用 ← 不看客户特定的,只看通用 FAQ#产品配置 #v2.0 #系统A ← 只看 v2.0 的系统A配置
四个维度在搜索框里组合,瞬间把上千条文档切成可消费的小集合。这套机制上线后,我所在团队的 FAQ 查询命中率从 20% 提升到 70% 以上(口径:周度高频 20 词抽样)。
覆盖 80% 搜索场景即可,不追求完备。
个人层:让 AI Agent 真正消费你的知识
团队层设计完,问题没结束——还要决定本地目录怎么长,才能让 AI Agent 拿到就能消费。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linemy-work-folder/├── 00_inbox/ # 暂存区(当天进,隔天分类)│ └── 20260521.md # 日报式归档清单├── 系统A/ 系统B/ 业务域X/ ... # 业务域分类(与团队层对齐)├── AI 实践/ # 独立子库(避免污染业务知识)├── context/experience/ # 经验沉淀(关键)│ ├── INDEX.md # 自动维护的索引│ ├── 业务域X-XX查询.md # 单条经验│ └── 系统C-空引用排查.md├── 工作日志/├── 归档/└── 共享资源/
四个设计点,讲两个最重要的:
00_inbox 暂存区——当天的事直接扔进去,隔天再分类。不是为了"立刻归档"增加认知负担,是先把东西收进来不丢。
context/experience 经验沉淀——每解决一个问题,输出一条结构化经验。每条经验长这样:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line# 业务域X-某查询场景## 关键词某接口名, 日期过滤, 字段命名约定## 业务域 / 客户业务域X / 系统A / 客户 A## 问题(原始报错或需求描述)## 排查(关键 SQL / 接口调用 / 数据流向)## 结论(可复用的解决方案)## 关联- 团队知识库标签:#客户A #业务域X #FAQ- 相关历史经验:[[XX-另一个相关经验]]

不是格式洁癖,是让一条经验对人可读、对 Agent 可索引。INDEX.md 让 Agent 晨检时能扫到——索引本身就是检索入口。
这套模板跑下来,我半年内沉淀了上百条经验,其中近 40 条被同事主动翻阅过。
另外两个设计点一句话带过:业务域分类与团队层对齐,方便经验上行;AI 相关工具/提案/参考单独成域,不污染业务知识。
经验怎么从个人流向团队
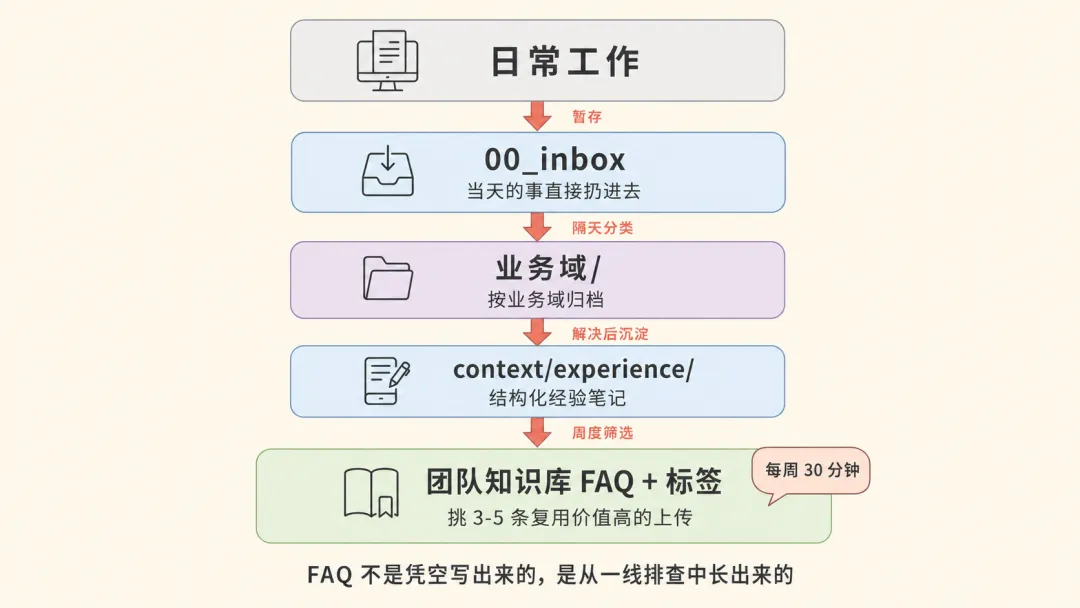
FAQ 不是凭空写出来的,是从一线工程师的日常排查中长出来的。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line日常工作↓ 暂存00_inbox/↓ 隔天分类业务域/↓ 解决后沉淀context/experience/↓ 周度筛选团队知识库 FAQ + 标签
个人层的 experience/ 不是终点,是团队层 FAQ 的源头。每周抽 30 分钟,从本周新增的 experience 里挑 3-5 条复用价值高的,按标签上传到团队层,FAQ 占比就这样从 2% 往上爬。
双层不是物理隔离,是单向沉淀 + 双向流动的工程结构。
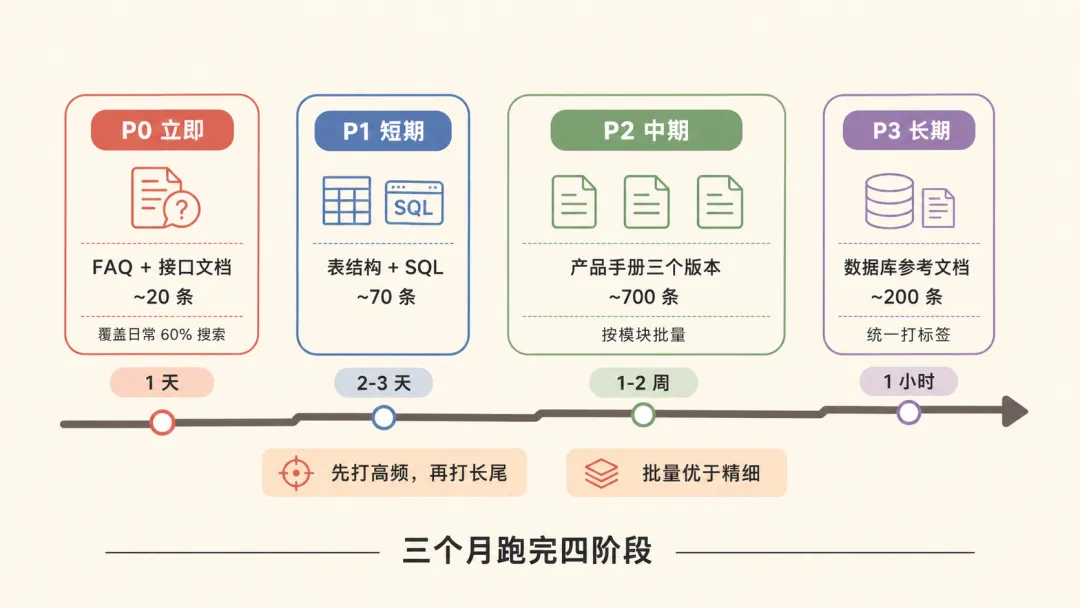
不可能一口气打完标签:P0-P3 节奏
不可能一次性把上千条内容打完标签——量太大会劝退。分四阶段,单条 15 分钟为限。
| P0 立即 | |||
| P1 短期 | |||
| P2 中期 | |||
| P3 长期 | #参考文档 1 小时 |
两条执行原则:
先打高频,再打长尾:P0 的 20 条覆盖日常 60% 搜索 批量优于精细:P2 / P3 用"模块统一标签"代替"逐条精修"
这套节奏在我们团队跑了三个月,标签覆盖率从接近 0% 提升到 60%+,整体命中率从 20% 提升到 70% 以上。
明天就能开始做的三件事
知识库失效不是因为内容少,是因为没入库 + 无标签 + 没人管。
今天就打开自家知识库,搜 5 个高频关键词,记下命中率——不量化就改不动。我当初就是从这一步开始的 为最常用的 20 条 FAQ 补上"客户 / 知识类型 / 业务域"三个标签——先打高频再打长尾,P0 的 20 条覆盖日常 60% 搜索 在本地工作目录建一个 00_inbox暂存区——今天的事先扔进去,明天再分类。同时选一条最近解决的问题,按"关键词 / 业务域 / 排查 / 结论"四段写成一条经验
知识库不是给 AI 看的,是给 AI 找的。 这件事不性感,但它决定了 AI 时代一个团队到底跑得起来还是跑不起来。
如果这篇对你有帮助,欢迎点赞 / 在看 / 转发三连——你的支持是我把这个系列写下去的最大动力。
