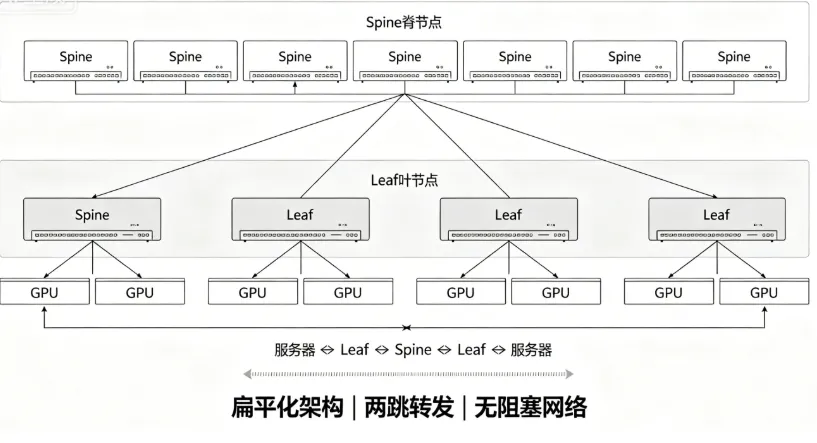
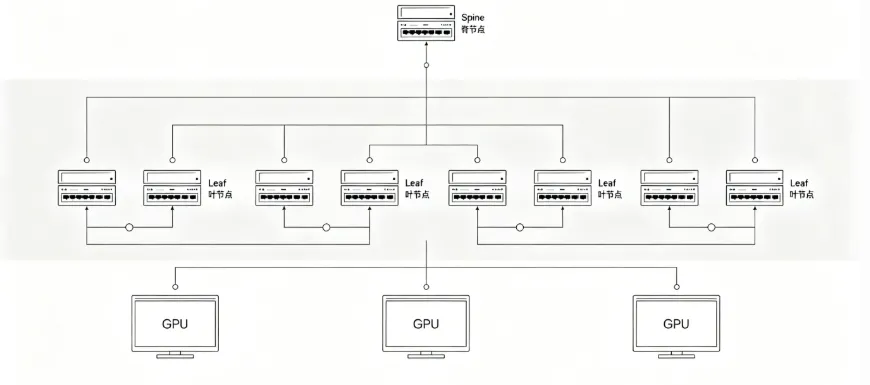
关键词:#数据中心网络#SpineLeaf#AI算力组网随着 AI 大模型、高性能计算、超算集群进入规模化落地阶段,算力需求迎来爆发式增长。不少运维和技术从业者发现,过去沿用多年的普通机房网络架构,在面对海量算力调度、高密度数据交互时频频 “掉链子”:网络延迟居高不下、数据传输拥堵、集群扩展困难,根本无法承载大模型训练、并行计算这类高负载业务。在此背景下,Spine-Leaf(叶脊)网络架构凭借扁平化拓扑、超低时延、弹性横向扩展等核心特性,彻底改写了 AI 数据中心的组网规则,如今已成为智算中心、超算集群的标准组网方案。本文用通俗的语言,拆解叶脊架构的底层原理、核心优势,结合实际场景分析其落地价值,带你读懂 AI 时代数据中心网络的核心壁垒。
很多人认为,AI 智算中心的核心竞争力只是 GPU、CPU 等算力硬件,实则不然。高端算力芯片只是 “发动机”,而 Spine-Leaf 网络架构就是 “传动系统”,没有优质的网络支撑,再顶尖的硬件也无法形成合力,这也是 AI 数据中心区别于普通机房的核心壁垒。从业务落地层面来看,叶脊架构的价值贯穿建设、运营、成本全流程。对于算力服务商而言,标准化的 Spine-Leaf 组网方案实现了模块化部署,大幅缩短智算中心的建设周期。统一的扁平化架构降低了网络运维复杂度,标准化设备和拓扑也便于后期迭代升级,长期运营成本更可控。同时,稳定、低时延的网络环境,能够支撑大模型训练、AI 推理、科学计算、仿真模拟等多元化算力业务,提升机房的业务承载能力和市场竞争力。对于 AI 企业、科研机构、超算用户来说,接入基于叶脊架构的智算集群,意味着获得更高的算力效率、更稳定的运行环境。训练大模型时,网络卡顿、任务中断的概率大幅降低,训练周期有效缩短,间接降低了研发和算力使用成本。无论是企业自研行业大模型,还是高校、科研院所开展超算科研项目,可靠的网络都是保障项目推进的基础。从行业发展角度,随着大模型参数规模越来越大、算力集群节点数量持续增多,网络架构的重要性还会持续提升。传统三层架构彻底退出高端算力场景已是必然,Spine-Leaf 叶脊架构不仅是当下的最优解,也是未来数年智算中心组网的主流方向。当然也要客观看待,叶脊架构的硬件投入、设计门槛高于传统三层网络,交换机数量、光模块用量更多,初期建设成本更高,这也是小型机房不会盲目升级的原因。但在 AI 算力这个赛道,网络不再是附属配套,而是和算力、存储并列的三大核心支柱,前期的网络投入,最终都会转化为算力效率和业务价值。
五、总结
普通机房的三层树形网络,是为传统互联网业务设计,天生无法适配 AI 大模型、超算集群高密度、低时延、大流量的组网需求。而 Spine-Leaf 叶脊架构依靠扁平化拓扑、两跳转发、全互联网状结构,解决了传统网络时延高、瓶颈多、扩展难的核心痛点,成为 AI 智算中心的标准组网方案。在 AI 算力竞争日趋激烈的今天,算力硬件决定了集群的 “上限”,而网络架构决定了硬件能否达到这个上限。读懂 Spine-Leaf 架构,也就读懂了 AI 数据中心最关键的技术壁垒之一。未来随着算力规模持续扩张、高速网络技术不断迭代,叶脊架构还会持续优化演进,持续为 AI 产业的发展筑牢网络根基。一文吃透传统IDC与AIDC智算中心的核心区别,别再混淆了风冷已到极限?深度解析液冷三大技术路线的适用场景与取舍。申明:部分图文内容借助AI生成。
基本文件流程错误SQL调试
请求信息 : 2026-06-09 09:54:19 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/728269.html
 夜雨聆风
夜雨聆风