 夜雨聆风
夜雨聆风📄 MarkItDown:万能文档转 Markdown 完全指南

微软 AutoGen 团队出品 · MIT 协议可商用 · 134K+ GitHub Stars
项目地址:[1]https://github.com/microsoft/markitdown[2]
🎯 一句话介绍
MarkItDown 是一款轻量级 Python 文档处理工具,能够将 PDF、Word、PPT、Excel、图片、音视频、网页等 20+ 种格式批量转换为结构化 Markdown 文本,自带 OCR 识图和音频转写能力。
✨ 核心亮点
🔄 20+ 格式支持:PDF / DOCX / PPTX / XLSX / CSV / 图片 / 音视频 / 网页 / EPUB / 压缩包等 🧠 智能 OCR:自动识别图片中的文字(支持中文) 🎙️ 音频转写:将语音内容转为文本 📊 保留结构:精准留存原文标题层级、表格、链接与排版 🤖 LLM 友好:专为 AI 大模型输入优化,是 RAG 知识库构建的首选工具 🔌 多种调用方式:CLI 命令行 / Python API / MCP 插件 / Docker 部署
🏗️ 系统架构概览
MarkItDown 采用分层架构设计:
📥 输入层(支持 20+ 格式)
办公文档:PDF、Word (DOCX)、PowerPoint (PPTX)、Excel (XLSX)、CSV 多媒体:图片(PNG/JPG/GIF)、音频(MP3/WAV)、视频(MP4/AVI) 网络资源:网页 URL、HTML 文件、EPUB 电子书 其他:压缩包(ZIP/TAR)、纯文本、代码文件
⚙️ 核心处理引擎
格式检测器:自动识别文件类型 文档解析器:提取文本结构和元数据 OCR 引擎:图片文字识别(支持中文) 音频转写器:语音转文字(基于 Whisper 模型) 结构提取器:保留标题层级、表格、列表等格式
📤 输出层
标准 Markdown 文本 结构化元数据 JSON
🔌 扩展接口
CLI 命令行工具 Python API(可集成到任何项目) MCP 插件(支持 Claude Code、Cursor 等 AI 工具) Docker 容器部署
🔄 转换工作流程
文档转换的完整流程如下:
1️⃣ 输入文件路径或 URL
2️⃣ 自动格式检测 → 根据文件扩展名和内容特征判断类型
3️⃣ 分路处理:
📄 文档类(PDF/Word/PPT/Excel)→ 文档解析器提取结构信息 🖼️ 图片类 → OCR 引擎识别文字内容 🎵 音频类 → Whisper 模型语音转文字 🎬 视频类 → 先提取音频轨道,再进行语音转写 🌐 网页类 → 抓取 HTML 并转换为 Markdown 📦 压缩包 → 解压后批量递归处理
4️⃣ 结构提取与格式化 → 统一生成标准 Markdown
5️⃣ 多方式输出:
打印到终端(CLI 模式) 返回 Result 对象(API 模式) 保存为 .md 文件
📋 支持的文件格式一览
📄 办公文档类
.pdf | ||
| Word | .docx | |
| PowerPoint | .pptx | |
| Excel | .xlsx | |
| CSV | .csv |
🖼️ 多媒体类
| 图片 | .png/.jpg/.jpeg/.gif/.bmp/.tiff | |
| 音频 | .mp3/.wav/.m4a/.flac | |
| 视频 | .mp4/.avi/.mkv/.mov |
🌐 网络资源类
| 网页 URL | https://example.com/article | |
| HTML 文件 | .html/.htm | |
| EPUB 电子书 | .epub |
🚀 快速上手
方式一:命令行使用(最简单)
# 安装pip install markitdown# 基础用法 - 转换单个文件markitdown document.pdf# 转换并保存到指定文件markitdown document.pdf -o output.md# 启用 OCR(处理扫描版 PDF 或图片)markitdown scanned.pdf --use-ocr# 使用自定义 OCR 端点(如 Azure CV / OpenAI)markitdown image.png --use-ocr --ocr-endpoint "your-endpoint"# 批量转换整个文件夹markitdown ./documents/ --output-dir ./converted/# 从 URL 转换网页markitdown https://example.com/article.html方式二:Python API 调用(推荐)
from markitdown import MarkItDown# 初始化(零配置,自动选择解析器)md = MarkItDown()# 转换 PDFresult = md.convert("report.pdf")print(result.text_content) # Markdown 文本print(result.metadata) # 元数据(页数、作者等)# 转换 Word 文档result = md.convert("proposal.docx")# 转换 Excel(表格自动转为 Markdown 表格)result = md.convert("data.xlsx")# 转换图片(OCR 识别)result = md.convert("screenshot.png")print(result.text_content) # 图片中的文字# 转换音频(语音转文字)result = md.convert("meeting.mp3")print(result.text_content) # 会议记录文本# 转换视频(先提取音频再转写)result = md.convert("lecture.mp4")print(result.text_content) # 讲座字幕# 转换网页result = md.convert("https://blog.example.com/post")# 高级配置:启用 OCR + 自定义端点md_with_ocr = MarkItDown( use_ocr=True, ocr_endpoint="https://your-cv-api.cognitiveservices.azure.com/", ocr_key="your-api-key")result = md_with_ocr.convert("handwritten_notes.jpg")方式三:Docker 部署(生产环境)
# 拉取镜像docker pull mcr.microsoft.com/markitdown:latest# 运行容器(挂载本地目录)docker run -v $(pwd)/input:/input \ -v $(pwd)/output:/output \ mcr.microsoft.com/markitdown:latest \ markitdown /input/document.pdf -o /output/result.md# 带 OCR 的完整版(包含 Whisper 模型)docker run -v $(pwd)/input:/input \ --gpus all \ # GPU 加速语音转写 mcr.microsoft.com/markitdown:full \ markitdown /input/meeting.mp4 -o /output/transcript.md💡 典型应用场景
场景 1:构建 RAG 知识库
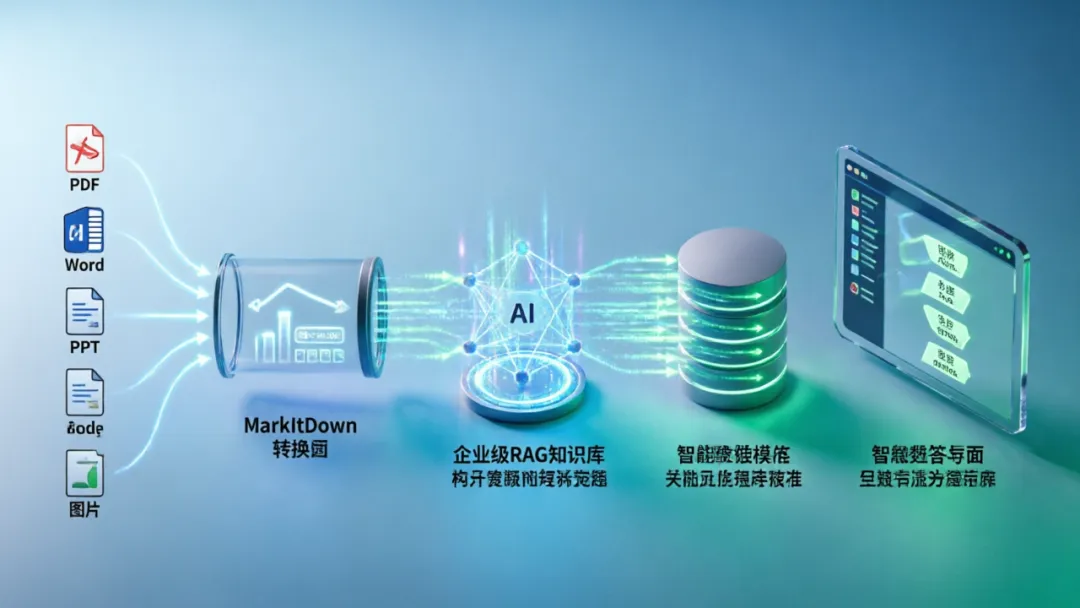
为什么选 MarkItDown?
✅ 保留原文档的标题层级和表格结构,提升检索精度✅ 输出的 Markdown 可被 LLM 直接理解,无需额外清洗✅ 支持 OCR + 音频转写,非文本资料也能入库✅ 批量处理能力强,适合企业级知识库建设
典型工作流:
用户上传企业文档(PDF/Word/PPT) MarkItDown 批量转换为标准 Markdown 文本分块 → Embedding → 存入向量数据库 用户提问时,系统语义检索相关片段 将检索到的上下文发送给大语言模型 LLM 生成准确回答并引用来源
场景 2:AI 数据集预处理
典型流水线:
多源原始数据(学术论文 PDF、技术博客 HTML、会议录音 MP3、产品手册 DOCX、截图 PNG)→ MarkItDown 统一处理(格式归一化、质量过滤、元数据提取)→ 高质量训练集(纯文本语料、结构化指令数据、多模态配对数据)
实战代码示例:
import osfrom markitdown import MarkItDownmd = MarkItDown(use_ocr=True)input_dir = "./raw_data/"output_dir = "./training_corpus/"for filename in os.listdir(input_dir): filepath = os.path.join(input_dir, filename)try: result = md.convert(filepath)# 保存为训练数据withopen(f"{output_dir}/{filename}.md", "w") as f: f.write(f"# Source: {filename}\n\n") f.write(result.text_content)print(f"✅ {filename} -> {len(result.text_content)} chars")except Exception as e:print(f"❌ {filename}: {str(e)}")场景 3:个人知识管理

输入源多样化:
📚 书籍笔记(Kindle 导出、EPUB 电子书) 🎤 会议记录(录音转文字、PPT 要点提取) 🌐 网页收藏(文章存档、论文全文) 📂 工作文档(报告 PDF、合同 Word)
核心能力:
全部格式统一转为 Markdown 保留层级结构,OCR 手写笔记 语音转文字,元数据自动提取
输出应用:
同步到 Obsidian / Notion / Logseq 作为 ChatGPT / Claude 的上下文输入 构建个人全文检索和语义搜索系统
自动化示例:每日信息汇总
from markitdown import MarkItDownfrom datetime import datetimemd = MarkItDown()defdaily_digest():"""将多来源信息汇总成一份 Markdown 日记""" content = [] content.append(f"# 📅 {datetime.now().strftime('%Y-%m-%d')} 知识日报\n")# 1. 转换今天保存的 PDF 文章 pdf_files = ["./inbox/paper1.pdf", "./inbox/report.pdf"]for pdf in pdf_files: result = md.convert(pdf) content.append(f"\n## 📄 来自: {pdf}\n") content.append(result.text_content[:2000]) # 截取前 2000 字符# 2. 转换会议录音 meeting_audio = "./meetings/team_standup.mp3" result = md.convert(meeting_audio) content.append("\n## 🎙️ 会议纪要\n") content.append(result.text_content)# 3. 收藏的网页文章 urls = ["https://blog.example.com/ai-trends-2026","https://docs.example.com/new-feature" ]for url in urls: result = md.convert(url) content.append(f"\n## 🔗 网页: {url}\n") content.append(result.text_content[:1500])# 4. 保存汇总withopen(f"./daily/{datetime.now().strftime('%Y%m%d')}.md", "w") as f: f.write("\n".join(content))returnf"./daily/{datetime.now().strftime('%Y%m%d')}.md"output_file = daily_digest()print(f"✅ 日报已生成: {output_file}")🔧 高级配置与技巧
自定义解析器链
from markitdown import MarkItDownfrom markitdown.docx import DocxConverterfrom markitdown.pdf import PdfConverter# 只启用特定格式的解析器md = MarkItDown( converters=[ DocxConverter(), # 仅支持 Word PdfConverter() # 和 PDF ])# 或者禁用某些功能md_no_ocr = MarkItDown( use_ocr=False# 禁用 OCR 以加快速度)与 AI Agent 集成(MCP 协议)
MarkItDown 支持 Model Context Protocol (MCP),可直接接入 Claude Code、Cursor、OpenCode 等 AI 编程助手:
集成效果:
在 Cursor 中直接右键文件 → "Send to MarkItDown" → 获得 Markdown 版本 在 Claude Code 中输入 /markitdown report.pdf→ 自动转换为上下文在 OpenCode 中粘贴文件路径 → 即时获得结构化文本
📊 性能对比
与其他工具对比
| 格式数量 | ||||
| OCR 支持 | ||||
| 音频转写 | ||||
| 表格保留 | ||||
| 代码高亮 | ||||
| 易用性 | ||||
| 维护状态 | ||||
| MIT 协议 |
处理速度参考(测试环境:M2 MacBook Pro)
*注:音频转写速度取决于是否使用 GPU 加速
🎯 最佳实践建议
💡 何时选择 MarkItDown?
✅ 需要 快速原型验证 时(零配置开箱即用) ✅ 构建 RAG 知识库 时(输出质量高) ✅ 处理 混合格式 文档时(一套工具搞定所有) ✅ 需要 OCR + 音频转写 一体化方案时
⚠️ 性能优化建议
批量处理时:使用 --output-dir参数避免重复初始化大文件处理:考虑分块或使用流式 API 生产环境:推荐 Docker 部署 + GPU(如需音频转写) 隐私敏感:使用本地部署版本,不上传云端
✅ 成功案例参考
某科技公司:用 MarkItDown 将 10 万份内部文档转为向量库,构建企业 Copilot 某高校实验室:批量处理 5000+ 篇论文 PDF,构建领域专用训练数据集 自媒体团队:自动将播客录音转文字,再用 GPT 生成公众号文章
🔗 相关资源
GitHub 仓库:[3]https://github.com/microsoft/markitdown[4] PyPI 包: pip install markitdown官方文档:包含完整的 API 参考、配置选项和故障排查指南 Discord 社区:微软 AutoGen 团队运营,响应迅速 示例项目:仓库内含 examples/目录,覆盖常见使用场景
📝 总结
MarkItDown 是当前 最实用的文档转换工具之一,特别适合:
AI 应用开发者:作为 RAG 管线的数据预处理层 数据工程师:快速清洗和标准化多源异构数据 研究人员:高效从论文、书籍、视频中提取知识 个人用户:构建本地化的个人知识管理系统
核心优势:零配置、高质量输出、格式全覆盖、微软背书。
一句话评价:如果你需要把任何东西变成 Markdown,先用 MarkItDown 试一试——它大概率能解决你的问题。
📌 本文档生成时间:2026 年 6 月 8 日🔄 数据来源:GitHub Trending、官方 README、社区实践🛠️ 工具版本:MarkItDown v0.1.x(基于 2026 年 6 月最新版)
引用链接
[1]undefined: https://github.com/microsoft/markitdown
[2]https://github.com/microsoft/markitdown
[3]undefined: https://github.com/microsoft/markitdown
[4]https://github.com/microsoft/markitdown
