 夜雨聆风
夜雨聆风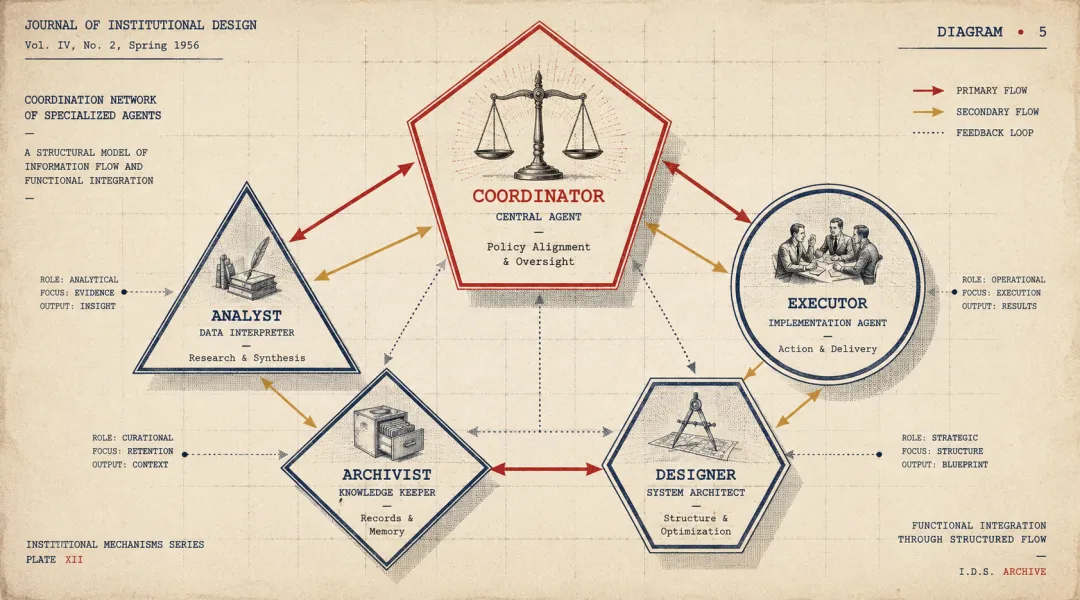
你做了一件看起来很合理的事。
给合同审查任务配了两个 Agent:一个负责找风险条款,一个负责汇总最终报告。分工合理,你觉得效率应该翻倍。
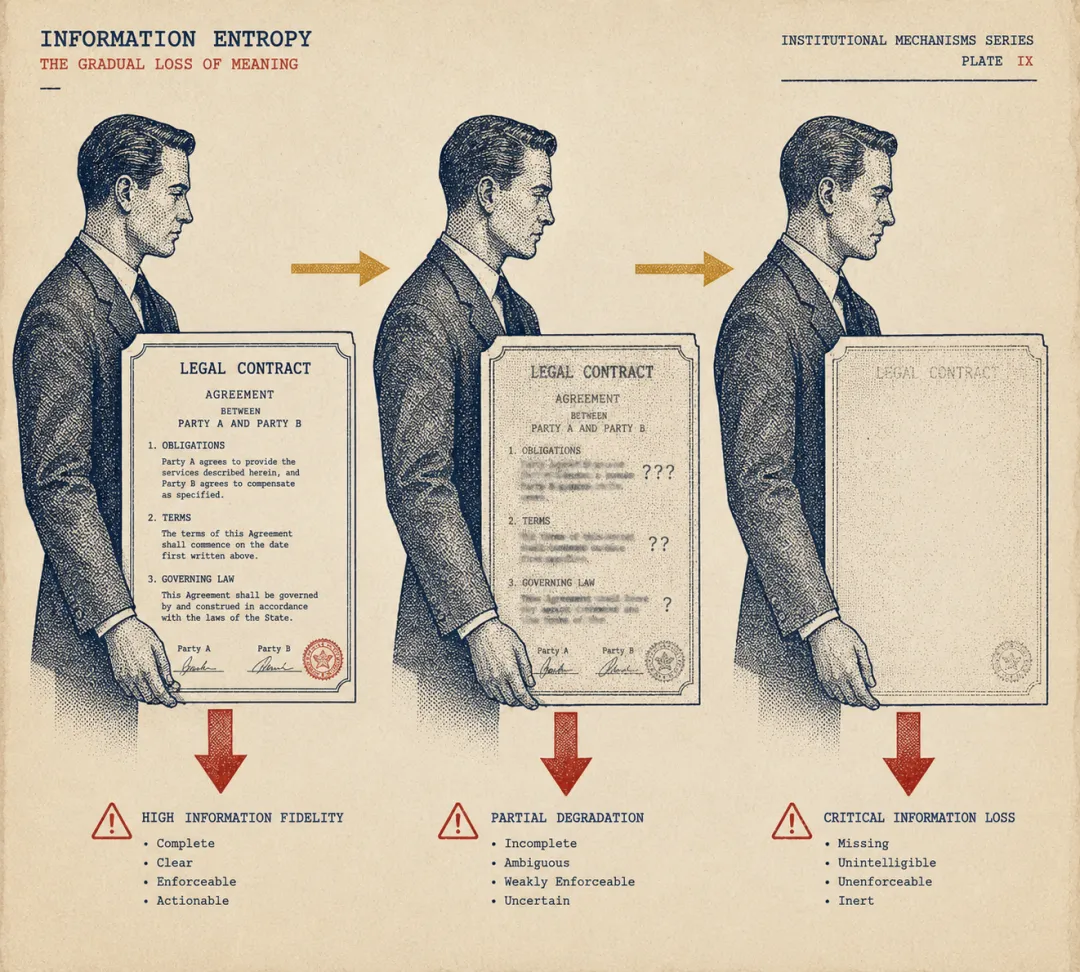
结果那个汇总 Agent 拿到了风险条款清单,在没有对照原合同的情况下,把清单"总结"了一遍,产出了一份措辞更流畅、但判断更模糊的报告。
你配了两个 Agent,得到了一份比单 Agent 更差的输出。
多 Agent 失败,原因通常不是模型不够好,而是结构选错了。
你真的需要多 Agent 吗?
这个问题不是废话,是真的要先想清楚。
多 Agent 不是默认高级形态。专业分工的同时,协调成本也来了:更多 Token、更多延迟、更多容易出错的传话节点。单 Agent 能搞定的事,加 Agent 只会加噪声。
触发多 Agent 的,通常是四种真实约束:
上下文污染:任务中途产生大量中间材料,会干扰后续判断。比如并行检索了十几份文件,如果全堆给一个 Agent,它容易在噪声里迷路。子 Agent 处理完再回传摘要,主线就干净了。
需要并行:多个子任务互不依赖,串行跑太慢。尽调里财务、法律、商务三条线,没有理由排队等。
需要专业化:某个环节需要完全不同的工具集或判断框架,塞给一个 Agent 会让它在"我该用哪个"上反复纠结。
需要独立验证:同一个 Agent 又生成又审查,容易自证正确。独立的审查 Agent 用不同上下文看同一份输出,可靠性更高。
没有真实约束,就不要升级到多 Agent。
五种结构,分别解决什么问题
不同约束,对应不同结构。下面每种模式,我会说清楚它是什么、法律场景里对应什么情况、以及什么时候用它。
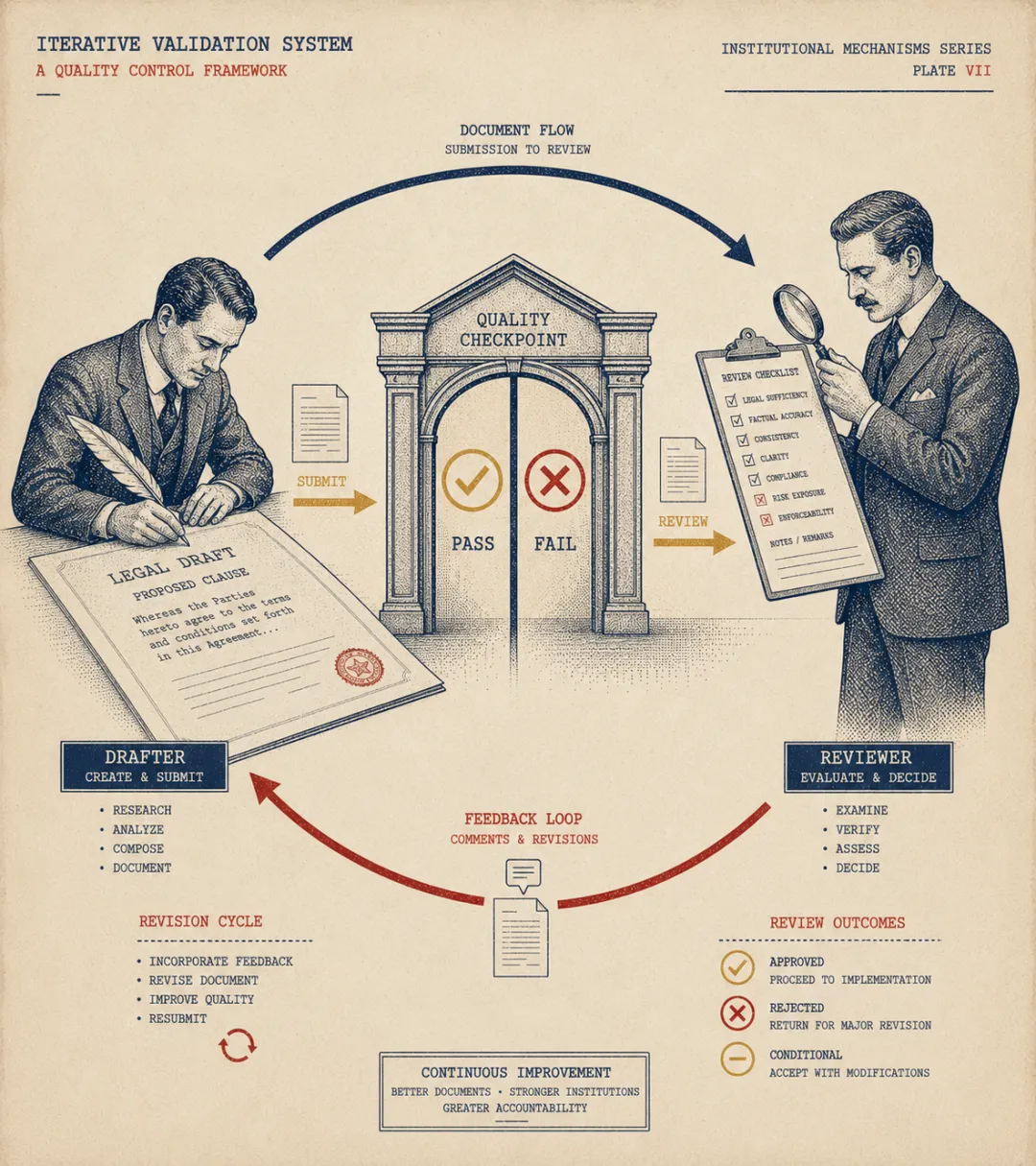
输出质量不稳定,就上 Generator-Verifier
这是最容易被低估的结构,也是最值得优先试的。
直接解释就是:一个 Agent 负责生成,另一个 Agent 负责验证,不达标就打回重来,循环直到通过。
起草 Agent ↓ 输出初稿验证 Agent ↓┌── [通过] ──→ 交付│└── [不通过] ──→ 反馈原因 ↓ 起草 Agent 修正 ↓ 再次验证(最多 N 轮)法律场景里,合同审查最对口。你让 Agent 起草审查意见,但你知道它容易漏掉特定风险点,比如争议解决条款里的仲裁地、保密条款的例外情形、交割先决条件的触发机制。
单独配一个验证 Agent,给它一份核查清单:这些点必须覆盖,格式必须满足,有没有前后矛盾。起草 Agent 每次输出都要过这道门禁,不过不放行。
关键不在于"有两个 Agent",在于验证标准是不是真的明确。如果你给验证 Agent 的指令是"帮我检查有没有问题",它就会走过场。验证条件越具体,这个结构越有用。
质量问题是结构问题,不是模型问题,Generator-Verifier 是最直接的结构解法。
任务需要拆分执行,就用 Orchestrator-Subagent
目前最常见的多 Agent 形态,也是《律师不开飞书》系列和《法律人的 Claude Code 教程》里反复跑过的。
直接解释就是:主 Agent 理解并拆分任务,子 Agent 各自执行其中一块,完成后回传结果。
主 Agent(理解任务,拆分执行) ├── 子 Agent1(查企业工商信息) ├── 子 Agent2(跑合同检索) └── 子 Agent3(生成摘要报告)触发条件是:任务明确可拆,子任务之间有依赖顺序,主 Agent 只需要拿结果就够了。
这个结构的细节在《律师不开飞书 02》里有完整示范,这里不重复。只补一个边界:子任务边界越模糊,主 Agent 就越容易变成传话员,而不是协调者。
如果你说不清楚子任务做到什么算完成,这个结构会失控。
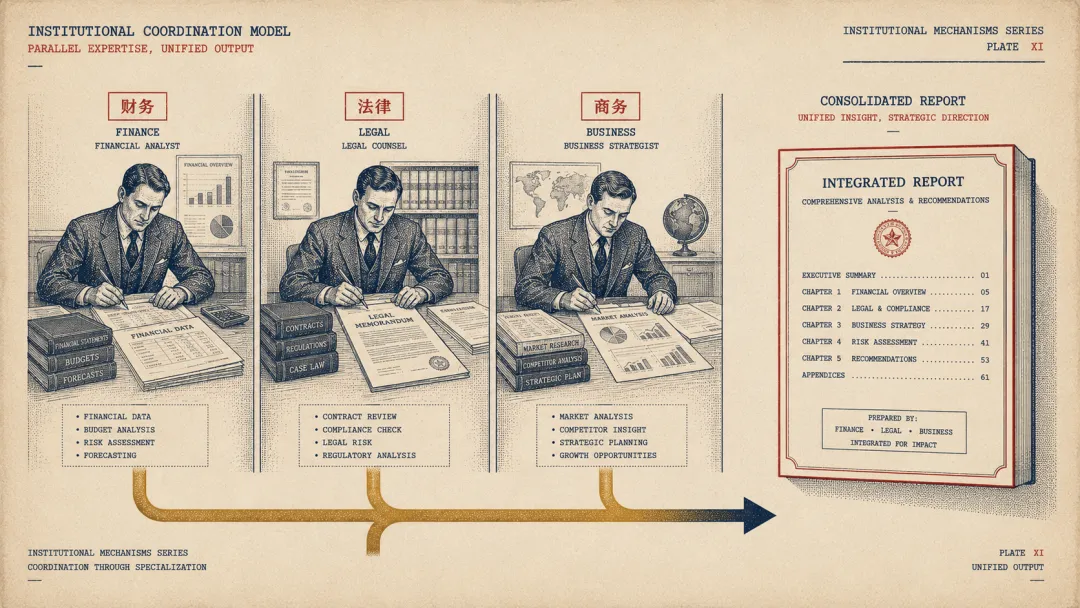
多个方向需要同时跑,就用 Agent Teams
和 Orchestrator-Subagent 的差别是:这里的 Worker Agent 是长期存在、持续工作的,不是主 Agent 临时召唤的一次性子 Agent。
直接解释就是:有一个协调者,多个 Worker Agent 各认领一个领域,长期并行工作,最后汇总。
协调者 Agent ├── 财务尽调 Agent(持续读财务文件) ├── 法律尽调 Agent(持续读合同与证照) └── 商务尽调 Agent(持续读业务材料) ↓ 协调者整合,出报告并购尽调是这个结构最对口的场景。财务、法律、商务三条线互不依赖,让三条线同时跑,不用等任何一条完成才启动下一条。
和 Orchestrator-Subagent 的核心差异是运行方式:Worker Agent 专注于某个分区、持续工作,边界稳定后协调者不需要频繁介入,只在最终汇总时出现。
并行不只是效率问题,也是视角隔离问题,让三条线各自独立看材料,比一个 Agent 顺序看三遍更可靠。
流程固定且会扩展,就考虑 Message Bus
这个结构偏工程化,不是最常见的法律 AI 起手式,但一旦流程固定下来,扩展性最好。
直接解释就是:系统里发生的每件事都是一个"事件",不同的 Agent 订阅自己关心的事件,事件触发后自动执行。
事件:客户提交材料 ↓消息路由 ├── 审查 Agent 订阅"新材料" ──→ 自动触发合同审查 ├── 催办 Agent 订阅"审查完成" ──→ 自动提醒律师处理 └── 归档 Agent 订阅"任务关闭" ──→ 自动整理存档这个结构适合事务所级别的工作流自动化。客户提交材料这个事件一发生,后面的审查、催办、归档都自动流转,不需要人工逐步触发。以后想加一个"自动生成费用确认单"的步骤,只需要多订阅一个事件,不用动原来的结构。
触发条件是:流程已经稳定,而且预期还会加新步骤。如果流程本身还在变,不要上这个。
Message Bus 不适合探索,适合把已经想清楚的流程跑稳、跑顺、跑久。
早期探索需要多个视角碰撞,就用 Shared State
五种里最自由,也最难控制。
直接解释就是:多个 Agent 读写同一份共享材料库,谁有新发现就写进去,其他 Agent 看到后可以继续推进,也可以修正。
共享案件材料库 ↑↓ ↑↓ ↑↓Agent A Agent B Agent C(法律路径) (事实还原) (时间线梳理)这个结构适合案件早期分析阶段。你有一堆材料,不知道从哪条线切入。让三个 Agent 分别从法律依据、事实还原、时间线三个角度各自探索,谁发现关键线索就写进共享库,其他 Agent 看到后可以据此调整方向。
风险是:容易没完没了,也容易几个 Agent 绕着同一个结论打转。用这个结构一定要设好终止条件,比如轮数上限,或者明确的"任务完成"判断标准。
Shared State 是创意碰撞的工具,不是生产线,用它探索,用其他结构交付。
选哪个,对照这张表
从"我有几个 AI 助理"到"我的 AI 团队选了什么结构",这一步比任何模型升级都重要。配多少个 Agent 不是问题,有没有想清楚它们之间信息怎么流、质量怎么控、边界在哪里,才是问题。
结构决定质量,数量不决定质量。


