 夜雨聆风
夜雨聆风PDF解析 · RAG · 开源免费
OpenDataLoader PDF
拿下全球PDF解析Benchmark综合第一
24K星标 · 本地CPU免费运行
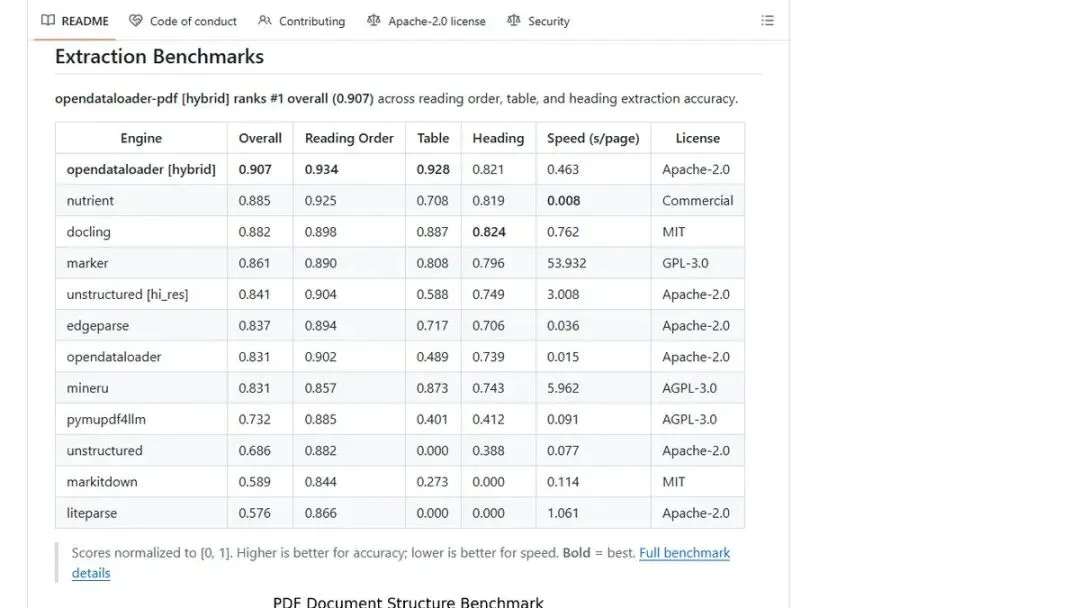
⚠️ 先说结论:做RAG的人,PDF解析是命门。OpenDataLoader拿下全球综合准确率第一(0.907),表格提取0.928,100页PDF只需15秒,还能标出原文坐标让AI回答可溯源——而且本地CPU就能跑,开源免费。
0.907
综合准确率 · 全球Benchmark第一
最近在做RAG项目的朋友,大概都踩过同一个坑——PDF解析。
你可能也经历过:扔进去一份财报,出来的结构全是乱的,表格变文本,图片里的文字直接失踪,段落顺序颠倒。更要命的是,当AI回答你"根据第3页第2段"的时候,你根本没法验证这句话到底从哪来的。
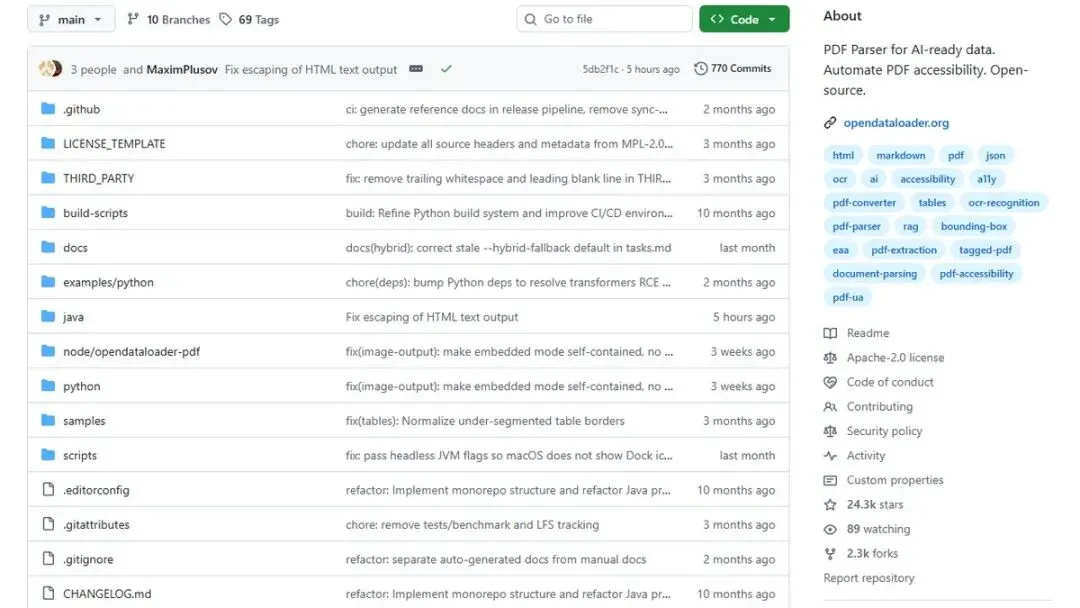
这事儿困扰了RAG开发者很久,直到我看到OpenDataLoader PDF这个项目——24K星,GitHub趋势榜常客,拿下了全球PDF解析Benchmark综合第一。它的核心数据是这样的:
0.907 综合准确率 | 0.928 表格提取准确率 | 0.015秒 每页(本地模式)
输出:Markdown · JSON · HTML · Tagged PDF · PDF/UA
我仔细研究了它的README,发现这个项目解决的不只是一个技术问题,而是整个RAG工作流里最薄弱的那一环。今天把这东西掰开揉碎给你看,顺便聊聊5个真实可落地的变现思路。
先说说痛点:你现在的PDF解析有多离谱?
做知识库的朋友,对这个场景应该不陌生——
一份100页的PDF学术论文,丢进解析工具,表格直接变成一串无意义的符号,段落顺序混乱,标题识别全靠猜,图片里的文字直接忽略。RAG跑出来的向量数据库看着挺像那么回事,但一问三不知,AI开始胡说八道。
问题出在哪?传统的PDF解析工具,本质上是在"猜"文档结构。它们靠规则(正则表达式、启发式算法)去识别标题、段落、表格,但PDF这东西根本没有标准结构——每家软件生成的PDF排版方式都不一样,你让机器怎么猜?
AI说"根据第5页的内容",但你根本不知道第5页的哪些字符生成了这个答案。想核实?做不到。
OpenDataLoader PDF就是在解决这个问题。它不是靠规则猜,而是靠XY-Cut++算法(一种基于视觉布局分析的阅读顺序识别)+AI混合模式,让PDF解析第一次有了"确定性输出"——同一个PDF,解析100次,结果一模一样。
它到底能做什么?先回答三问
🔧 怎么用?
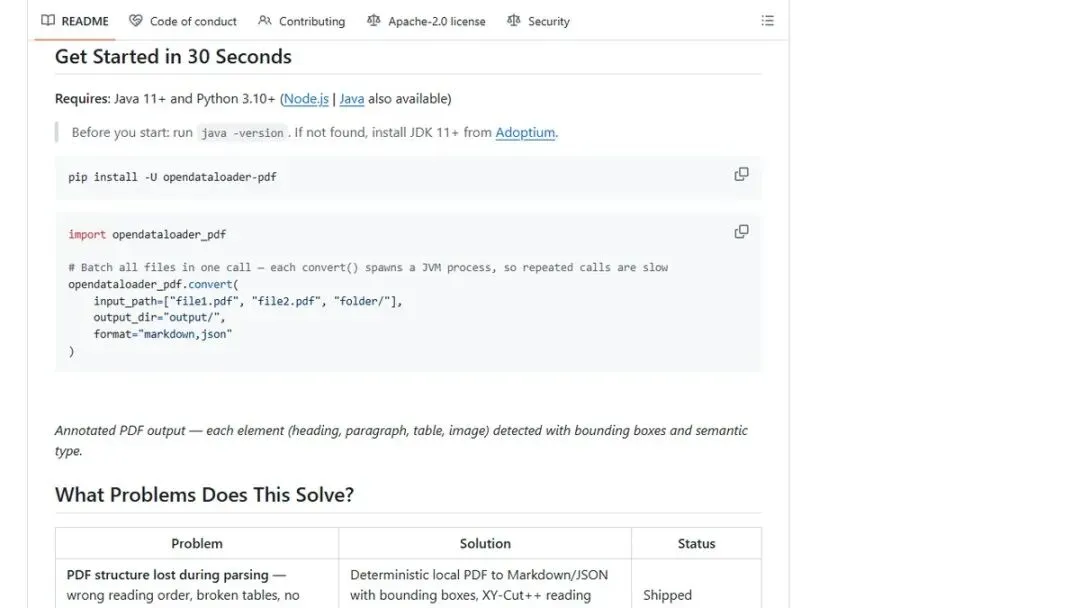
pip install opendataloader-pdf
3行代码完成PDF转Markdown/JSON/HTML:
from opendataloader import PDFParser parser = PDFParser() result = parser.parse("your-document.pdf") result.to_markdown("output.md") result.to_json("output.json", with_bounding_boxes=True)
支持Python、Node.js、Java三种SDK。LangChain也有现成集成,直接from langchain.document_loaders import OpenDataLoaderPDFLoader就能用。
本地CPU就能跑,不需要GPU。速度:本地模式0.015秒/页,AI混合模式(复杂页面自动调用)约0.5秒/页。100页PDF,15秒解析完。
✨ 有什么用?
它解决的问题非常明确——把非结构化的PDF,变成AI-ready的结构化数据,同时保留原文坐标。
输出格式有四种:
- Markdown — 适合直接chunking做RAG
- JSON — 带bounding box坐标,每个文字块在PDF里的位置都有记录
- HTML — 保留排版信息
- Tagged PDF — 自动无障碍标注,符合PDF/UA标准
🎯 能做什么?
具体场景太多了:
RAG知识库搭建:直接输出带坐标的JSON,AI回答时能精确定位到"第几页第几行",你可以做答案溯源。
表格密集型文档处理:财报、科研论文、政府报告——这些文档里表格一堆,传统的规则解析几乎全挂。表格提取准确率0.928,borderless表格也能识别。
扫描件/低质量PDF:混合模式内置OCR,支持80+语言,300 DPI以上的扫描件能自动识别文字。
LaTeX公式和图表描述:复杂论文里的数学公式,混合模式能生成LaTeX代码;图表能生成AI描述文字,这些内容直接进知识库,RAG效果完全不一样。
PDF无障碍合规:很多政府文件和商业报告需要PDF/UA(无障碍标准),这个工具能自动把未标记的PDF转成Tagged PDF,是第一个开源端到端方案。
技术到底强在哪?
它的Benchmark数据不是自己吹的,是在200份真实PDF(含多栏排版、科研论文、财务报告)上跑出来的,综合准确率0.907,排名第一。
几个关键技术点:
XY-Cut++阅读顺序识别:传统工具靠文本特征猜段落顺序,OpenDataLoader靠视觉布局分析——先把PDF按视觉切分成块(类似人眼看文档的方式),再按阅读顺序排列。这个方法对多栏排版特别有效,左到右、上到下,不会乱。
Bouding Box坐标体系:每个解析出来的文本块,都有精确的坐标记录(x, y, width, height),JSON输出里直接带。AI回答时能说"第3页第4行到第5行",你能验证。
Hybrid AI模式:简单页面用本地算法(快、免费),复杂页面(表格跨页、公式密集、扫描模糊)自动切换AI增强模式,准确率更高。
PDF无障碍自动化:跟PDF Association合作,输出符合Well-Tagged PDF规范,通过veraPDF自动化验证。这块是开源方案里独一份的。
变现SOP:5个真实可落地的方向
这个工具本身是开源的,但你用它能干的事情,是可以收费的。给你5个方向:
SOP 1:企业知识库私有化部署服务
痛点:很多企业有大量历史PDF文档(合同、财报、手册、研究报告),想做内部知识库,但市面上的方案要么贵(按页收费)、要么解析质量差。
玩法:提供OpenDataLoader私有化部署服务,部署在客户本地服务器,帮他把历史PDF全部结构化,配上向量数据库(Milvus/Chroma),做成内部RAG系统。按文档量收费,500页以下2万,500-5000页5万,5000页以上10万起。
收费:一次性部署费 + 每年维护费(维保费通常是部署费的15-20%)。投入:需要懂Linux、懂Docker、能跑Python脚本。上手成本大概一周。
SOP 2:PDF文档解析API服务
痛点:市面上的文档解析API(如Azure Document Intelligence、Google Document AI)价格不低,而且不支持本地部署,数据安全敏感的企业不敢用。
玩法:用OpenDataLoader搭一个解析API服务,部署在云服务器上(阿里云/腾讯云),对外提供PDF转Markdown/JSON的API,按调用次数收费。0.01元/页,1000页起售。可以针对特定行业(法律、医疗、金融)做垂直定制。
收费:月订阅制,基础版99元/月(1000页),专业版299元/月(5000页),企业版定制。投入:一台2核4G的云服务器年成本约1500元,带宽成本很低。技术门槛不高,Python写API用FastAPI,一周能上线。
SOP 3:学术论文结构化加工服务
痛点:研究生写文献综述,需要把大量论文的表格、公式、参考文献提取出来做分析;科研机构需要把历史论文数字化建库。手动整理效率极低。
玩法:提供学术论文结构化加工服务——学生或科研人员把PDF丢过来,你用OpenDataLoader解析,输出结构化的Markdown(含表格、公式、图表描述),并整理出文献目录和摘要。按篇收费,基础版50元/篇(纯解析),进阶版150元/篇(含人工校验+格式整理)。
收费:50-150元/篇,看复杂度。投入:几乎零成本,有电脑就能做。主要靠时间换钱,适合作为副业起步方向。
SOP 4:PDF无障碍合规改造服务
痛点:各国政府都在推PDF无障碍合规(欧盟EAA、美国Section 508、中国相关法规),大量政府网站和企业内部文件需要满足PDF/UA标准。传统方案是人工逐页标注,收费50-200美元/页,成本极高。
玩法:用OpenDataLoader做批量自动Tagged PDF转换,配合人工抽检,提供合规改造服务。按页收费,5元/页(自动转换)+ 1元/页(人工抽检)= 6元/页。比传统方案便宜90%,而且能规模化。
收费:6元/页,100页起接。投入:需要了解PDF/UA标准,但工具本身已经帮你做了最难的部分。上手成本低,适合服务政府机构和企业采购部门。
SOP 5:垂直行业PDF知识库产品
痛点:法律、医疗、金融等行业有大量标准化文档(合同、病历、研究报告),通用RAG方案效果差,需要垂直优化的解析方案。
玩法:选一个垂直方向(比如法律行业的判决书解析),用OpenDataLoader做定制化解析流程,加上行业专属的分类标签和索引逻辑,做成SaaS产品。面向律所、医疗机构、金融机构,按账号收费,199元/月/人。
收费:199元/月/人,团队版599元/月。投入:需要深入理解一个行业的文档结构和业务需求,门槛高但护城河也高。一旦跑通,续费率会很高。
这背后说的是什么?
PDF解析这件事,看起来是个技术问题,但你往深了想,它折射的是一个更大的趋势——
AI落地到真实业务场景,最难的不是模型本身,而是数据质量。
这两年大家都在聊RAG,但真正把RAG做好的团队,核心竞争力不在于选哪个模型,而在于数据怎么治理、文档怎么清洗、解析怎么保证质量。模型是通用的,数据才是壁垒。
OpenDataLoader解决的,就是RAG数据准备阶段最脏最累的活。它让PDF从"不可信的原始材料"变成"结构化的AI-ready数据",而且能溯源。
这个方向,2024年才刚开始。PDF解析这个赛道,还没有绝对霸主,机会还很多。
「模型是通用的,数据才是壁垒。」
—— 这句话,在2025年的AI应用战场上,比任何模型参数都值钱。
如果觉得有收获
👍 👎 ➡️ 三连支持一下
作者 | 创艺记 · 原创不易 · 欢迎转发
