 夜雨聆风
夜雨聆风
AI 短视频已经让人见怪不怪,但只要你试图把时长拉到分钟级:角色变脸、音色漂移、等到天荒地老、改一句台词整条重跑,这些痛点始终让 AI 长视频停留在"玩"的阶段。
近日,京东Joy Future Academy 正式开源长音视频生成框架 JoyAI-Echo,直击上述三大行业顽疾,首次实现最长5分钟高一致性、可对话编辑、高清输出的多镜头故事生成,让 AI 长视频真正走向生产可用。

JoyAI-Echo 是京东推出的开源长音视频生成框架,专为分钟级多镜头叙事内容设计,在GitHub已斩获1.3Kstar。
功能特点
分钟级多镜头故事生成
支持从单个提示词 JSON 生成连贯的多镜头长视频序列,最长可达5分钟。
跨模态音视频联合生成
单一管道同步输出视频与音频,确保音画同步。
配对跨模态记忆库
在多镜头生成中持续保存并调用角色外观特征与说话人音色,保持故事级一致性。
DMD 蒸馏少步推理
通过分布匹配蒸馏技术,实现约 7.5 倍的生成速度提升。
Director Agent 对话式编辑
用户可用自然语言与导演助理交互,自动拆分剧本、角色、场景和镜头,支持局部修订,无需重跑整条视频。
轻量化实时超分
支持从 736×1280 单步超分至 1152×1920 或 1472×2560,在流式延迟约束下保持高清输出。
核心创新
跨模态音视频记忆库
内置 Slot-Paired 机制,视觉记忆与音频记忆绑定存储。生成新镜头时,模型调取历史角色外观+音色作为条件,辅以"远锚近联"策略(保留前 3 镜作为身份锚点 + 近 4 镜上下文),确保 5 分钟内角色身份、形象、声音高度一致,彻底解决长视频"失忆变脸"问题。

记忆驱动后训练 + DMD 蒸馏(≈7.5× 加速)
三阶段后训练流程:记忆感知 SFT → 跨模态 RLHF(OmniNFT)→ 记忆感知 DMD 蒸馏。将多步扩散压缩为少步推理(约 8 步),在保持质量前提下实现约 7.5 倍推理加速,让分钟级视频从"等半小时"变为可用时效。
Director Agent(对话式导演助理)
引入智能 Agent 将模糊意图自动拆解为剧本→角色卡→场景→镜头计划。支持规划→生成→评审→局部修订闭环工作流,用户用日常语言提修改意见,Agent 判定影响范围仅重生成相关片段。
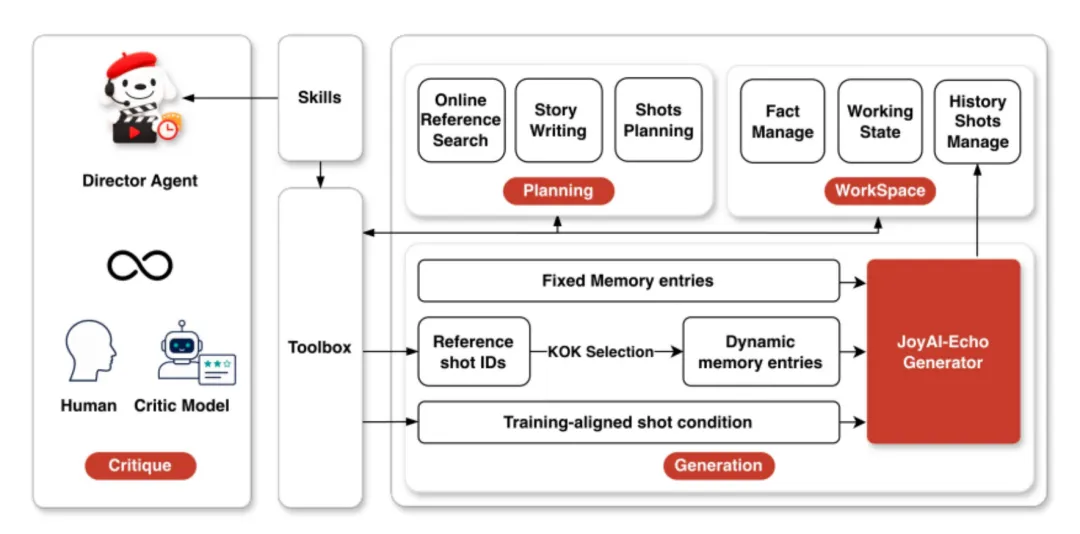
轻量化实时音视频超分
配套单步超分模块,在流式延迟约束下将基础分辨率锐化至 1080p/2K 级别,同时精细化音频输出,直接满足商用内容交付标准。
应用场景
虚拟动漫 / 漫剧量产:生成数分钟连贯动画故事,角色形象与配音全程锁定,大幅降低传统逐帧/逐镜修正成本
数字人内容 & 虚拟主播:为数字人客服、虚拟 IP 生成长时段讲解视频,面容与音色不漂移,提升真实感
品牌营销视频快速迭代:借助对话式编辑快速调整脚本/镜头,多版本 A/B 测试周期从周级压缩至天级
影视前期预演 & 分镜:用自然语言生成多镜头预演,验证镜头语言与走位,降低实拍试错成本
互动教育课件:按知识点生成长段讲解视频,支持针对某一片段快速修订
Github :https://github.com/jd-opensource/JoyAI-Echo欢迎扫码加入社群
一起交流AI前沿技术!

小编免费共享AI开源项目知识库,
实现大家的AI资讯自由!
直接扫码或点击链接即可查看!
AI开源项目知识库:https://qyxznlkmwx.feishu.cn/wiki/BwWIwsCOuiMWGmkUzNHcKLvPnPh
