 夜雨聆风
夜雨聆风
这句话我已经听过不止一次了。研发的提测节奏在以肉眼可见的速度变快,而我观察了大半年——bug 的分布、出现的位置、踩坑的模式,确实和以前完全不一样了。问题是,团队里大多数测试用例的设计思路,还停留在过去那一套"人工编码"的应对方式上。
继续按老套路走,结果就是一个很尴尬的局面:你花了大力气测的地方根本不出问题,真正高发的雷区你却没怎么碰。
这篇就聊清楚一件事:人写代码和 AI 写代码,各自强在哪、弱在哪;测试策略到底该往哪儿挪。
先把账算清楚:人写 vs AI 写,强弱完全不同

测试资源永远是有限的,所以测试设计的本质是"赌概率"——把精力压在最可能出 bug 的地方。要赌得准,先得看清两种编码方式的底牌。
人写代码的特征:
主流程容易出现低级错误。变量名拼写偏差、条件判断遗漏、复制粘贴未同步修改、循环边界写反——这类基础性缺陷占了人为 bug 的很大一部分。所以传统测试里,我们要花大量时间反复验证主流程,确认"基本功能能不能用"。 但人有全局心智模型。一个做了几年的开发,脑子里装着整个项目的关联关系:改了 A 模块,他知道 B、C 也得跟着动,配置改了哪些地方会读到。 人写得慢,反而是优点。慢意味着在敲代码的过程中,他有时间顺手把空值、超时、前置条件不满足这些异常分支想一想、补一补。
AI 写代码的特征:
主流程几乎不会手抖。语法、命名、基础逻辑,AI 的稳定性远超人类,typo 这种事基本绝迹。主流程"能不能跑通"已经不再是高发问题。 但 AI 只有"局部视野"。受上下文窗口限制,它经常只看到你贴给它的那几个文件,改完就交差,关联的调用方、配置消费方、前端定位器——它根本不知道存在,自然不会改。 AI 倾向只实现 happy path。你让它实现功能,它会把主路径写得漂漂亮亮,但 else 分支、default 兜底、异常降级,往往草草了事甚至直接漏掉。 AI 对"代码之外的世界"基本无感。网络抖动、磁盘满、端口被占、依赖服务挂了、并发资源竞争这些和物理资源相关的场景,AI 几乎不会主动考虑。
把这两张底牌摊开放在一起,结论非常清楚:bug 的重心,从"主流程实现错误"整体迁移到了"边界、关联、异常和环境"上。
转变一:别再死磕主流程,省下来的时间投给异常场景
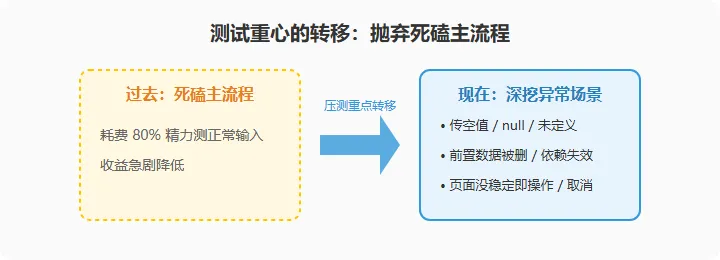
先说一个可能有点反直觉的判断:AI 写的主流程,测试投入可以适当往下压。
不是说不测,而是不要再像以前那样把一大半精力耗在反复验证"正常输入能不能得到正常输出"。AI 在主路径上的实现质量,已经稳定到不值得我们投入那么多冗余用例了。
省下来的时间去哪儿?投给异常场景。
这里有个特别隐蔽的陷阱:不是 AI 比人更不考虑异常,而是人和 AI 协作的"节奏"把异常考虑挤掉了。
以前开发写得慢,敲代码的过程中脑子有空转,顺手就把"如果这里传了空值怎么办""超时了怎么处理"想了。现在呢?开发在和 AI 高速多任务交流——这个窗口让 AI 写登录,那个窗口让它改告警,注意力被切成碎片,根本没有那个"慢下来顺手补异常"的过程了。需求里说"实现登录",AI 实现了登录,开发看一眼主流程能跑就合并了,谁还去抠"密码框传 null 会不会崩"?
所以异常引发的 bug 不是变少了,是变多了。测试用例的设计重心必须明确压过去:
输入空值 / null / 未定义时,系统是给明确提示还是直接崩? 前置数据被删掉后,依赖它的功能是合理报错还是白屏? 操作执行到一半取消、刷新、点浏览器后退,数据会不会留下脏状态? 弹框残留、页面没稳定就操作,这些 UI 异常态有没有被处理?
这部分内容,我们团队已经把它固化进了用例设计规则——AI 写的每个功能点,异常场景健壮性都是强制附加的测试维度,不允许只测 happy path 就放行。
转变二:回归测试从"可选项"升级成"必选项"
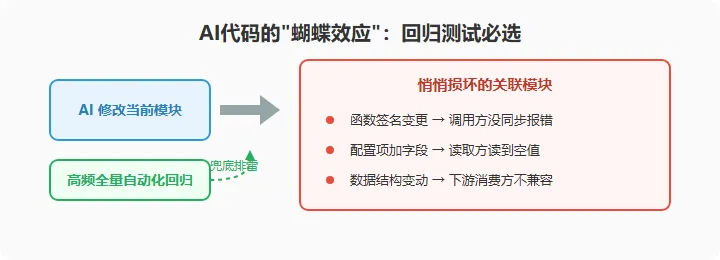
这是我认为变化最大、也最容易被低估的一点。
过去一个有经验的开发改功能,他清楚改动会波及哪些地方。改了订单模块的某个字段,他知道报表、对账、推送都会读这个字段,会主动去看、去测。所以"改 A 弄坏 B"这种跨模块连带 bug,在人工开发时代其实没那么频繁。
AI 把这个前提彻底打破了。它受上下文限制,很多时候只改了你让它改的那一部分,其他关联位置纹丝不动:
函数签名改了,调用方没同步,运行时直接报错; 配置项加了字段,读取方没适配,旧逻辑读到空值; 前端页面元素调整了,对应的自动化定位器没更新,脚本集体失败; 共享的数据结构变了,下游消费方没兼容,数据对不上。
这意味着一个残酷的现实:AI 改完代码后,历史功能被悄悄弄坏的概率,比人工时代显著上升。 而这些坏掉的地方,往往不在本次需求的范围内,开发自己测的时候压根不会去碰。
所以测试策略要做两个调整:
第一,回归测试的优先级要往上提。 以前回归可能是"有时间再跑一遍",现在它是 AI 改动后的标配动作,尤其是被改动实体的所有引用链路。
第二,用例设计要显式覆盖"跨文件 / 跨模块一致性"。 不能只验证当前页面、当前功能,必须往外扩一层:
新增 / 修改的功能,在关联页面是否正确联动? 编辑某实体后,引用它的其他功能是否还正常? 删除某实体后,依赖链上每个环节是否都给了合理处理? 配置变了之后,所有读这个配置的模块行为是否一致?
一句话:AI 时代,自动化回归套件的价值翻倍了。 因为 AI 高频改动 + 局部视野的组合,正好是回归测试最擅长兜底的场景。
转变三:把环境和资源类场景重新捡起来

还有一类被长期忽视、现在又重新变重要的场景——网络、硬件、资源。
AI 写代码时,几乎活在一个"理想世界"里:网络永远通,磁盘永远有空间,依赖服务永远在线,并发永远不冲突。它不会主动给你加超时重试,不会处理连接断开后的状态恢复,不会考虑资源耗尽时的降级。
人在这方面反而会凭经验补一些——"这个接口可能慢,加个超时""这里并发高,得加锁"。AI 没有这种来自踩坑的肌肉记忆。
所以这类场景,测试必须主动补上:
网络中途断开、请求超时,系统是卡死、报错还是优雅重试? 依赖的服务不可用时,有没有降级或明确的错误提示? 并发操作同一份数据时,会不会出现脏写、覆盖? 资源(连接数、内存、磁盘)逼近上限时,行为是否可控?
这部分以前可能靠开发自觉,现在开发把这层"自觉"外包给了不懂物理世界的 AI,那就只能靠测试这道关兜住。
收个尾:测试设计的重心,整体往"边界"挪
把上面四点收拢成一句能记住的话:
研发用 AI 写代码后,bug 不再集中在"功能实现得对不对",而是集中在"边界、关联、异常和环境扛不扛得住"。
对应到用例设计,就是三个"往下压"和三个"往上提":
这不是说 AI 写的代码质量差——恰恰相反,它在主流程上比人更靠谱。问题在于它的能力是"偏科"的:主路径满分,边界和全局视野不及格。测试的价值,本来就该补在被开发忽略的那一面。过去补的是"人会犯低级错误",现在补的是"AI 有盲区"。
还有一个不能回避的现实:测试的压力只会越来越大
聊完策略,再说点更扎心的。
研发用 AI 后,提测速度肉眼可见地往上飙,但代码质量并没有同步变好——主流程是稳了,可前面讲的那些边界、关联、异常、环境的雷区在成倍增加。这意味着如果测试这一侧还是纯人工那套打法,结果只有一个:越来越累,却越来越被动。
而每次出了线上问题,第一个被问的永远是同一句话——"为什么测试没有测出来?"
这不是测试不努力,是研发端的产能被 AI 放大了,测试端的产能还停在原地。一边是"一天三个功能"地提,一边是"一个用例一个用例"地手点,这账怎么算都算不平。继续硬扛只会陷入恶性循环:加班越多、漏测越多、背锅越多。
所以摆在面前的就两条路:要么继续被研发的提测节奏推着跑,要么主动重构测试这一侧的能力——用例设计要更聚焦雷区、回归要自动化、AI 也得反过来用到测试侧来。
工具变了,bug 的形状变了,测试用例的形状要变,测试人员自身的工作方式也得变。还抱着老套路死磕主流程的测试,迟早会被那句"你们测试跟得上吗"问住。
跟得上的前提,是先看清楚——这一轮,雷区已经换了地方,规则也已经换了。
后面我会用一线实战经验,一步一步带你破局:从用例设计重构、自动化回归提速,到把 AI 反向用进测试流程,让测试这一侧也能跟上 AI 时代的节奏。
欢迎关注「测试老Z」,咱们接着聊。
