 夜雨聆风
夜雨聆风
导读
本文基于团队工程实践与独立思考,沿量化能力 → 性能增强 → 生态增强 → 海量场景 → 基座能力五条主线,系统拆解阿里云瑶池旗下的云原生数据库 PolarDB PostgreSQL 版(以下简称 PolarDB-PG)如何将 pgvector 从开源插件升级为支撑亿级向量、毫秒响应的一体化向量数据库引擎。
1

背景:向量数据库面临的三重权衡
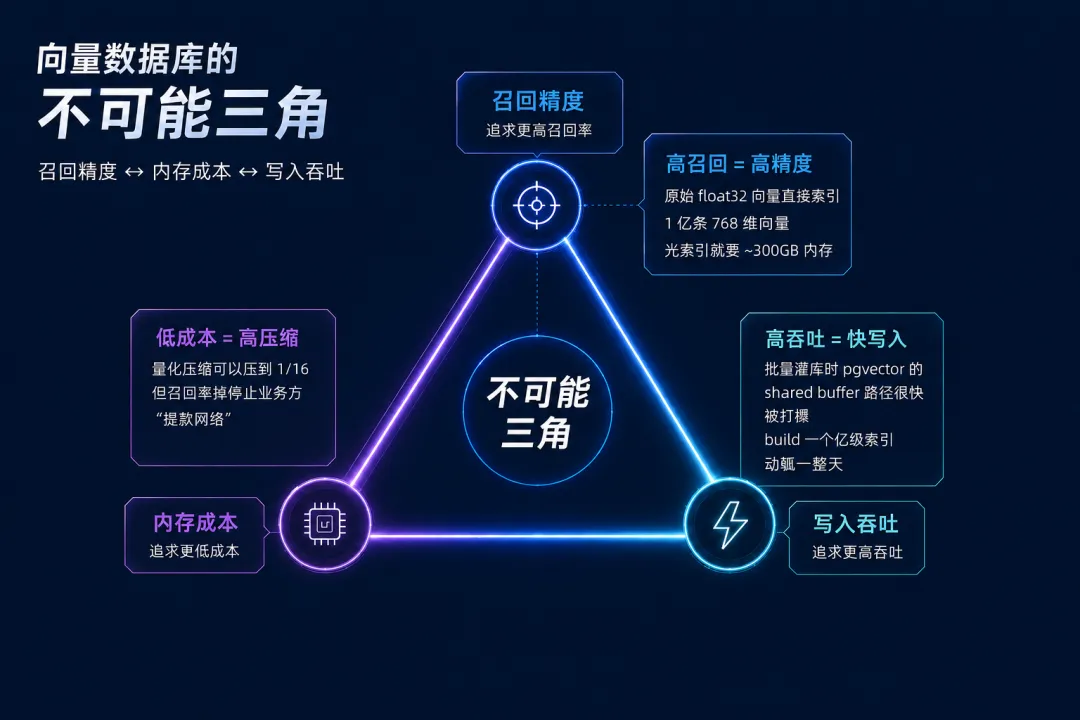

2

量化能力:单机承载亿级向量的关键能力
概括
能力建设
PQ(Product Quantization · 乘积量化): 将高维向量切分为 M 个子段,每段独立训练码本。压缩比高,召回精度依赖码本训练质量。 SQ(Scalar Quantization · 标量量化): 对每一维独立做线性量化(float32 → int8/int4)。实现简单、训练成本低,性价比最优。 RaBitQ(Random Bit Quantization · 随机位量化): 基于随机正交变换 + 1-bit 量化,理论上具有可证明的精度下界。
选型建议
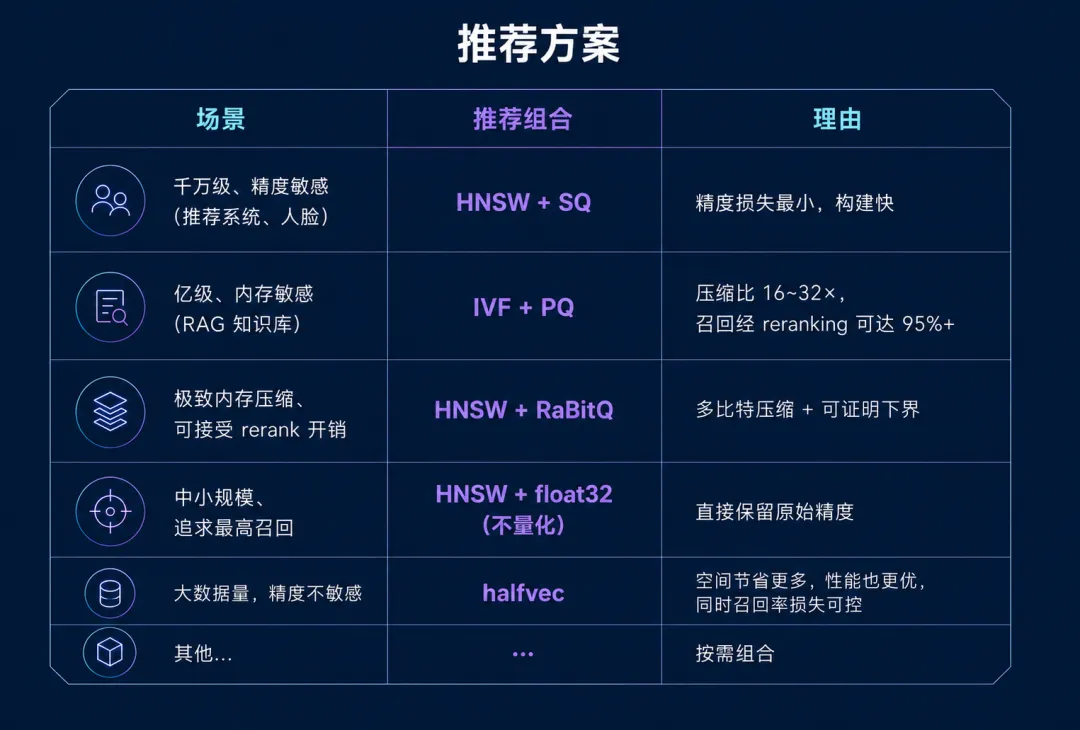
3

性能增强:pgvector 的工程能力完善
🔬 原始痛点:不少向量引擎没有独立的 FSM(Free Space Map)管理能力。当索引中出现空闲页时,新 INSERT 仅能顺序遍历数据页定位可用空间,IO 冲突随数据规模显著上升。
我们正在适配更加通用的向量数据清理逻辑——通过index_bulk_delete/index_vacuum_cleanup框架,与上一节的 FSM 改造形成闭环,使长期高写入/高删除场景下,索引膨胀率从“线性增长”变成“稳态可控”。
4

生态增强:自研 polar_vectorboost,打通向量检索工程链路
解决方案
自研的向量生态增强插件polar_vectorboost,把“高频 SQL”压缩成一次函数调用。基本能力分三个方面介绍:
-- 一条 SQL 完成:补 embedding 列 + 自动分词 + 回填数据 + 推荐索引 + 注册元信息SELECT step, statusFROM polar_vectorboost.bootstrap('faq', 'content', index_name => 'faq_idx', id_column => 'id');bootstrap:打通 polar_ai,自动给文本表补
embedding vector(N)+v tsvector两列;register_index / list_indexes / drop_index:元信息注册表,简化使用流程; recommend_vector_index:根据数据量 / 维度自动给出索引选型建议。
SELECT * FROM polar_vectorboost.hybrid_search('faq_idx', -- 注册表里的 index_name query_text => '云原生数据库', top_k => 10, fusion => 'weighted', vector_weight => 0.7); -- 偏向量支持 RRF(Reciprocal Rank Fusion,量纲不敏感的工业标准)与 Weighted(min-max 归一化后加权)两种融合算法,并自动以 OR 方式拼接 tsquery,规避plainto_tsquery默认 AND 拼接导致的召回坍缩。

💡 核心理念:polar_vectorboost 致力于将 RAG 系统中的通用工程能力标准化:从索引构建、混合召回到性能诊断,尽可能减少业务侧重复造轮子,让开发者将精力聚焦于数据与应用本身。
5

海量场景:pgvector 适配分布式

数据按 Hash / Range 切分到多个计算节点,每个节点本地维护自己分片的 HNSW / IVF 索引; 查询走 scatter-gather 模式:协调节点把 query 向量广播到所有分片,分片本地做 top-k 召回,协调节点做全局归并; 写入与数据运维完全分布式化,不再受限于单机的 CPU / 内存 / IO。
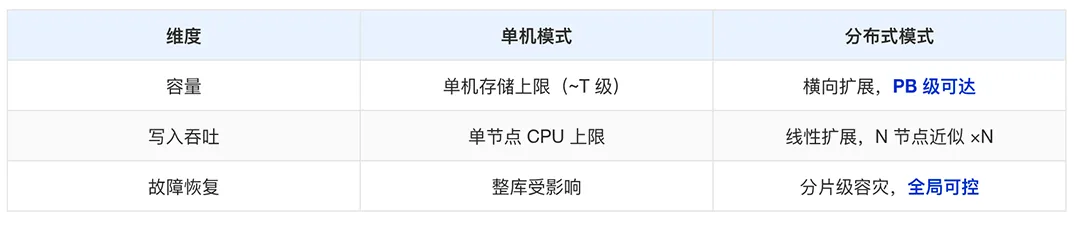
🎯关键判断:在向量场景中,分布式能力并不只是容量扩展问题,更决定了系统在长期增长下的可持续性。
6

基座能力:基于 PolarDB-PG 的工程支撑
高性能架构:内核深度优化,结合物理复制、RDMA 高速网络与分布式共享存储。 快速弹性:支持秒级弹性升降配(一写多读架构,最大容量 TB 级),可横向扩展至多个计算节点。 混合负载:跨机并行查询引擎,多节点协同执行 SQL,加速分析型查询。 冷热存储分层:亿级向量库下,热分片驻留高速层、冷分片下沉对象存储,兼顾成本与性能。 生态无缝对接
🔑 关键判断:向量能力主要聚焦于检索层,而生产环境下的整体可用性,则在很大程度上依赖底层数据库基座的支撑。
7

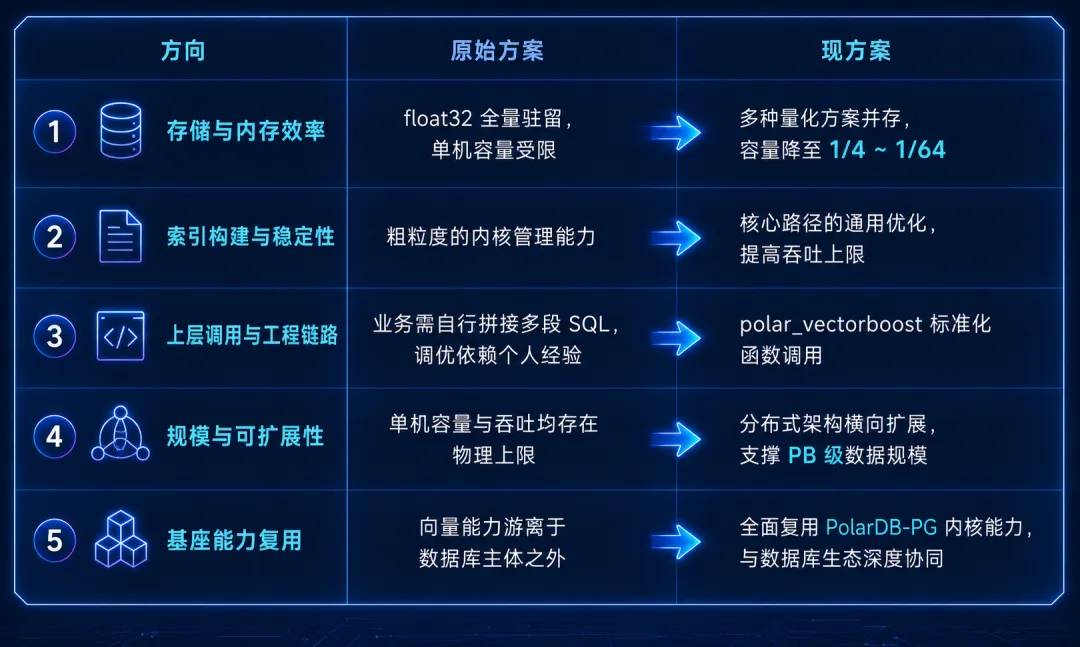
总结


点击 阅读原文查看官方文档



