 夜雨聆风
夜雨聆风AI Case 9 · SQL数据库智能查询助手
本期核心:让AI把自然语言翻译成SQL,让不懂数据库的人也能轻松查数据。
写在前面
做数据分析的朋友都知道,最头疼的不是写代码,而是"我想查个数据,但我不会SQL"。
产品经理要看转化率,运营要看留存率,财务要看营收明细——每个需求都要找研发排期,一来一回半天没了。
SQL智能查询助手就是来解决这个问题的:用自然语言提问,AI自动生成并执行SQL,秒级给出答案。
一、解决什么问题
| 场景 | 传统方式 | AI助手方式 |
|---|---|---|
| 销售总监查本月Top10客户 | 提需求→研发排期→等两天 | 直接问"本月销售额最高的10个客户是谁",秒出结果 |
| 运营看渠道转化漏斗 | 自己学SQL/导出Excel手动算 | 自然语言描述,自动出漏斗图 |
| 管理层开周会 | 提前一天让BI出报表 | 当场语音提问,AI即时回答 |
| 新人快速了解业务 | 找人问表结构、背字段名 | 直接问,AI帮你找到正确的表和字段 |
核心价值:降低数据查询门槛,让业务人员自助获取洞察。
二、系统架构
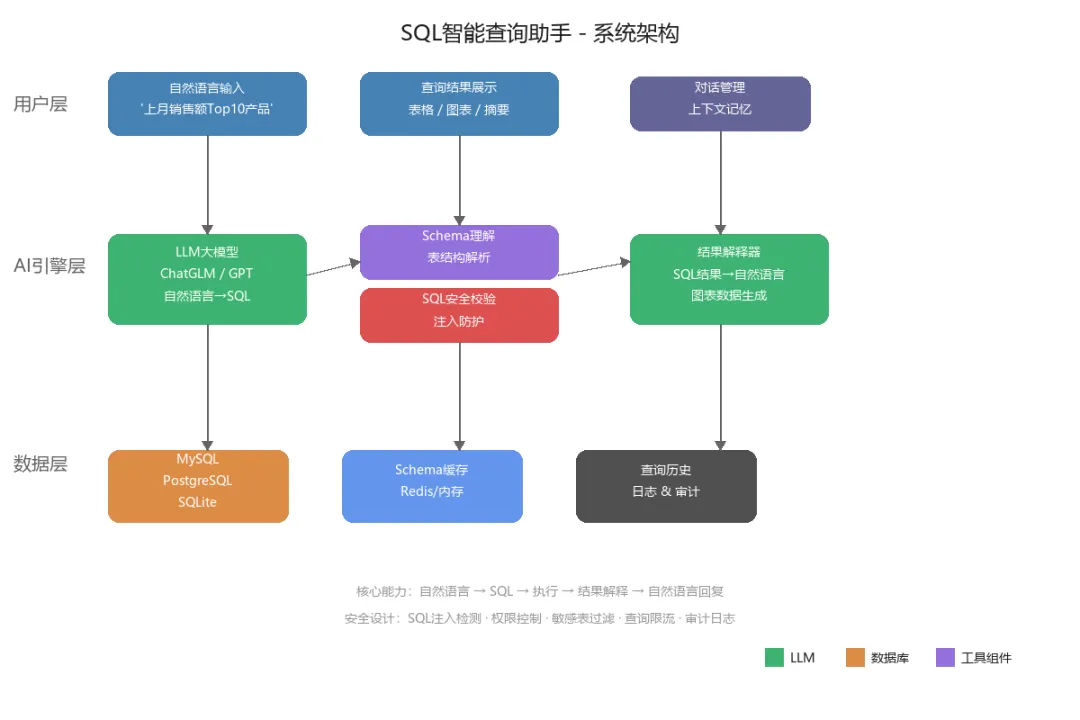
架构分层说明:
1. 用户层
自然语言输入:用户用日常语言提问,如"上个月各渠道的注册用户数" 查询结果展示:支持表格、图表、文字摘要等多种形式 对话管理:支持多轮对话,记住上下文
2. AI引擎层
LLM大模型:核心翻译官,负责自然语言→SQL的转换 Schema理解:解析数据库表结构,告诉AI有哪些表、什么字段 SQL安全校验:防止SQL注入,拦截危险操作(DROP/DELETE等) 结果解释器:把SQL结果翻译回自然语言,生成图表数据
3. 数据层
多数据库支持:MySQL、PostgreSQL、SQLite等 Schema缓存:用Redis缓存表结构,减少数据库压力 查询历史:记录所有查询,支持审计和性能分析
三、Text-to-SQL处理流程
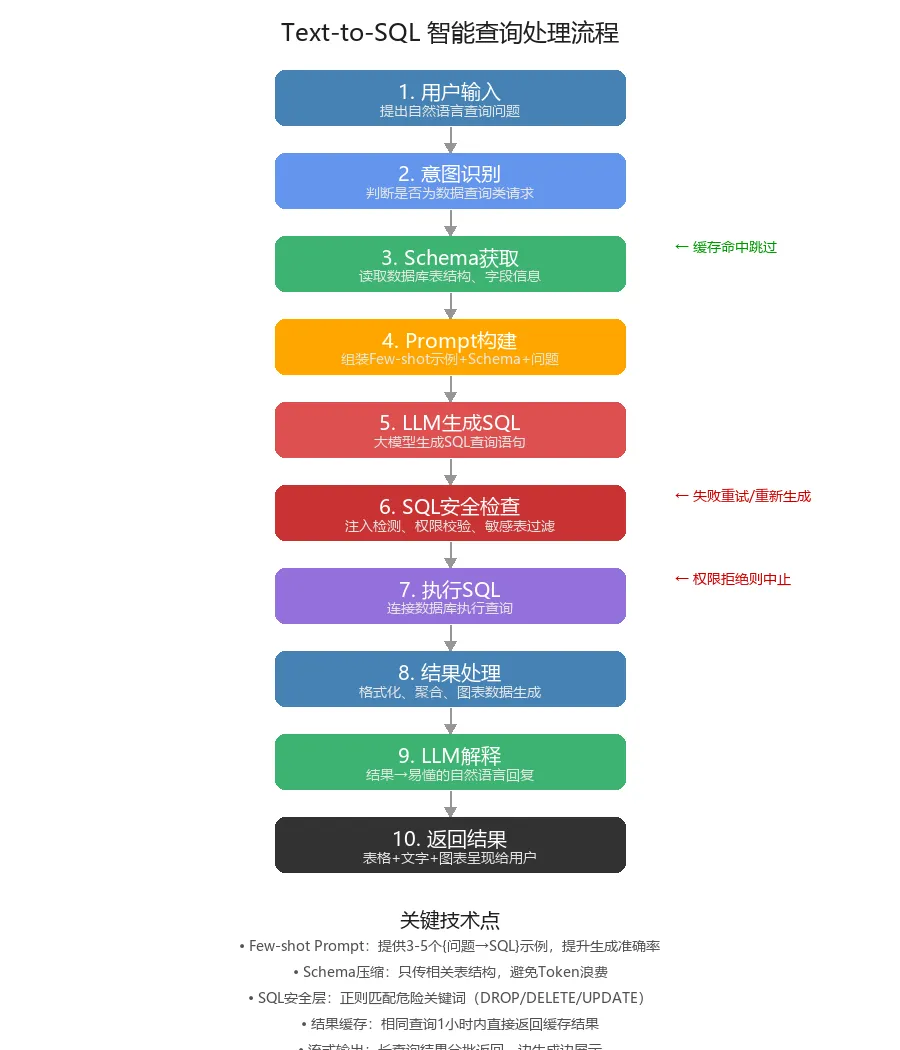
完整流程分解:
用户输入:提出自然语言查询 意图识别:判断是否为数据查询请求 Schema获取:读取数据库表结构(有缓存直接读缓存) Prompt构建:组装Few-shot示例+Schema+用户问题 LLM生成SQL:大模型输出SQL语句 SQL安全检查:注入检测、权限校验、敏感表过滤 执行SQL:连接真实数据库执行查询 结果处理:格式化、聚合、生成图表数据 LLM解释:把结果翻译成易懂的自然语言 返回结果:表格+文字+图表呈现
四、关键技术点
4.1 Few-shot Prompt 设计
给AI几个示例,让它"照猫画虎":
你是一个SQL专家。请根据以下表结构,将用户问题转换为SQL查询。
【表结构】
Table: orders
- id (INT, 主键)
- user_id (INT, 用户ID)
- amount (DECIMAL, 订单金额)
- created_at (DATETIME, 创建时间)
- status (VARCHAR, 状态: paid/unpaid/refunded)
【示例】
Q: 上个月的订单总金额是多少?
A: SELECT SUM(amount) FROM orders WHERE status='paid' AND created_at >= DATE_SUB(NOW(), INTERVAL 1 MONTH);
Q: 有多少用户下过单?
A: SELECT COUNT(DISTINCT user_id) FROM orders;
【用户问题】
Q: 今年每月的销售额是多少?
4.2 SQL安全校验
# 危险关键词黑名单
DANGEROUS_KEYWORDS = [
'drop', 'delete', 'truncate', 'update', 'insert',
'alter', 'grant', 'revoke', 'exec', 'system'
]
def is_safe_sql(sql: str) -> bool:
"""检查SQL是否安全"""
sql_lower = sql.lower()
# 必须是SELECT语句
if not sql_lower.strip().startswith('select'):
return False
# 检查危险关键词
for kw in DANGEROUS_KEYWORDS:
if kw in sql_lower:
return False
return True
4.3 Schema压缩
大表结构可能占用大量Token,需要智能筛选:
def compress_schema(table_name: str, question: str) -> str:
"""根据问题压缩Schema,只传相关字段"""
full_schema = get_full_schema(table_name)
# 用LLM判断哪些字段和问题相关
prompt = f"""
表 {table_name} 有以下字段:{full_schema}
用户问题:{question}
请列出回答该问题需要用到的字段名(逗号分隔):
"""
relevant_fields = llm.predict(prompt)
# 只返回相关字段的Schema
return filter_schema(full_schema, relevant_fields)
五、完整可运行代码
"""
SQL智能查询助手 - 完整实现
依赖:pip install langchain sqlalchemy pymysql python-dotenv
"""
import os
import re
import json
from typing import Dict, Any, List
from sqlalchemy import create_engine, text
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
class SQLQueryAssistant:
"""SQL智能查询助手"""
# 危险SQL关键词
DANGEROUS_KEYWORDS = [
'drop', 'delete', 'truncate', 'alter', 'grant',
'revoke', 'exec', 'system', ';--', 'xp_'
]
def __init__(self, db_uri: str, llm_api_key: str):
"""
初始化助手
Args:
db_uri: 数据库连接串,如 mysql+pymysql://user:pass@localhost/dbname
llm_api_key: 大模型API密钥
"""
self.engine = create_engine(db_uri)
self.llm = ChatOpenAI(
model="gpt-4o-mini",
api_key=llm_api_key,
temperature=0
)
self.schema_cache = {}
def get_table_schema(self, table_name: str) -> Dict:
"""获取表结构"""
if table_name in self.schema_cache:
return self.schema_cache[table_name]
with self.engine.connect() as conn:
# 获取列信息
columns = conn.execute(text(f"""
SELECT COLUMN_NAME, DATA_TYPE, COLUMN_COMMENT
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = '{table_name}'
""")).fetchall()
schema = {
'table': table_name,
'columns': [
{'name': c[0], 'type': c[1], 'comment': c[2]}
for c in columns
]
}
self.schema_cache[table_name] = schema
return schema
def format_schema_for_prompt(self, schema: Dict) -> str:
"""将Schema格式化为Prompt文本"""
lines = [f"Table: {schema['table']}"]
for col in schema['columns']:
comment = f" ({col['comment']})" if col['comment'] else ""
lines.append(f"- {col['name']} ({col['type']}){comment}")
return "\n".join(lines)
def is_safe_sql(self, sql: str) -> bool:
"""SQL安全检查"""
sql_lower = sql.lower().strip()
# 必须是SELECT开头
if not sql_lower.startswith('select'):
return False
# 检查危险关键词
for kw in self.DANGEROUS_KEYWORDS:
if kw in sql_lower:
return False
# 禁止多条语句
if sql.count(';') > 1:
return False
return True
def generate_sql(self, question: str, table_names: List[str]) -> str:
"""生成SQL查询"""
# 获取Schema
schemas = [self.format_schema_for_prompt(self.get_table_schema(t))
for t in table_names]
schema_text = "\n\n".join(schemas)
# Few-shot Prompt模板
prompt_template = PromptTemplate.from_template("""
你是一个专业的SQL数据分析师。请根据提供的表结构,将用户问题转换为标准SQL查询。
{schema}
【示例1】
问题:上个月销售额最高的10个产品是什么?
SQL:SELECT product_name, SUM(amount) as total_sales
FROM orders o
JOIN products p ON o.product_id = p.id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 1 MONTH)
GROUP BY product_name
ORDER BY total_sales DESC
LIMIT 10;
【示例2】
问题:有多少用户注册超过半年但没下过单?
SQL:SELECT COUNT(*) FROM users u
LEFT JOIN orders o ON u.id = o.user_id
WHERE u.created_at <= DATE_SUB(NOW(), INTERVAL 6 MONTH)
AND o.id IS NULL;
【用户问题】
问题:{question}
请只输出SQL语句,不要任何解释:
SQL:""")
chain = prompt_template | self.llm
result = chain.invoke({
'schema': schema_text,
'question': question
})
sql = result.content.strip()
# 提取SQL(去除可能的markdown代码块)
sql = re.sub(r'```sql\s*|```', '', sql).strip()
return sql
def execute_query(self, sql: str) -> Dict[str, Any]:
"""执行SQL查询"""
try:
with self.engine.connect() as conn:
result = conn.execute(text(sql))
columns = list(result.keys())
rows = [dict(zip(columns, row)) for row in result.fetchall()]
return {
'success': True,
'columns': columns,
'rows': rows,
'row_count': len(rows)
}
except Exception as e:
return {
'success': False,
'error': str(e)
}
def explain_result(self, question: str, result: Dict) -> str:
"""用自然语言解释查询结果"""
if not result['success']:
return f"查询失败:{result['error']}"
data_preview = json.dumps(result['rows'][:5], ensure_ascii=False, indent=2)
prompt = f"""
用户问题:{question}
查询返回了 {result['row_count']} 条数据:
{data_preview}
请用通俗易懂的语言总结这个结果,1-2句话:
"""
response = self.llm.predict(prompt)
return response
def query(self, question: str, table_names: List[str]) -> Dict[str, Any]:
"""
完整查询流程
Returns:
包含question, sql, result, explanation的字典
"""
# Step 1: 生成SQL
sql = self.generate_sql(question, table_names)
# Step 2: 安全检查
if not self.is_safe_sql(sql):
return {
'question': question,
'sql': sql,
'success': False,
'error': '生成的SQL未通过安全检查,可能包含危险操作'
}
# Step 3: 执行查询
result = self.execute_query(sql)
# Step 4: 解释结果
explanation = self.explain_result(question, result)
return {
'question': question,
'sql': sql,
'result': result,
'explanation': explanation,
'success': result['success']
}
# ============ 使用示例 ============
if __name__ == "__main__":
# 初始化助手(请替换为真实配置)
assistant = SQLQueryAssistant(
db_uri="mysql+pymysql://user:password@localhost/mydb",
llm_api_key="sk-your-api-key"
)
# 执行查询
response = assistant.query(
question="最近30天每天的订单量是多少?",
table_names=["orders"]
)
print("=" * 50)
print(f"问题:{response['question']}")
print(f"生成的SQL:{response['sql']}")
print("=" * 50)
if response['success']:
print(f"查询结果:{response['result']['row_count']} 条数据")
print(f"数据预览:")
for row in response['result']['rows'][:3]:
print(f" {row}")
print(f"\n解释:{response['explanation']}")
else:
print(f"查询失败:{response.get('error', '未知错误')}")
六、进阶优化方向
多表关联自动识别
通过Schema中的外键关系,自动决定JOIN哪些表查询意图分类
先用小模型分类(聚合查询/明细查询/趋势分析),再生成对应Prompt结果可视化
根据数据类型自动推荐图表:时间序列→折线图,分类对比→柱状图,占比→饼图对话上下文
支持多轮追问:"上个月销售额多少?" → "那上上个月呢?"查询改写
用户问"卖得最好的产品",AI能识别出等价于"按销量排序的Top产品"
七、安全与合规
| 风险 | 防护措施 |
|---|---|
| SQL注入 | 白名单验证(仅允许SELECT)、参数化查询 |
| 数据泄露 | 敏感表黑名单、字段脱敏、权限分级 |
| 性能风险 | 查询超时限制、慢查询告警、结果集大小限制 |
| 审计需求 | 全量日志记录、查询人/时间/内容追溯 |
写在最后
SQL智能查询助手不是要让所有人学会SQL,而是让不懂技术的人也能轻松从数据中获取洞察。
对于研发团队来说,它能大幅减少"提数需求"的占用;对于业务团队来说,它能实现真正的数据自助。
当然,生产环境落地还需要考虑更多:权限控制、审计日志、错误处理、性能优化……但核心思路是一致的:让LLM成为连接人类语言和机器语言的翻译官。
系列回顾:
第8期:让AI调用搜索引擎[1] 第7期:个人知识库搭建[2] 第6期:网页内容抓取与总结[3]
下期预告: 第10期《API编排:多服务串联》,教你如何用AI把多个API串起来,实现复杂业务自动化。
本文作者:悟空 · 2026年6月
引用链接
[1]第8期:让AI调用搜索引擎: ../p/xxx
[2]第7期:个人知识库搭建: ../p/xxx
[3]第6期:网页内容抓取与总结: ../p/xxx
