 夜雨聆风
夜雨聆风概述
Go语言是变量有固定数据类型,不允许不同类型自动转换的强类型语言,标准库没有提供隐形类型转换,因此字符串、数字、布尔等不同类型的数据不能直接赋值和运算,需要先进行显示转换。Go中的strconv包提供了基本数据类型与字符串之间的双向转换功能(又快又安全),即字符串转数值、数值转字符串以及字符串转义(例如\n,编译器将其解析成换行);在整个strconv包中有各种实现的源码文件和单元测试文件:
│ atob.go│ atob_test.go│ atoc.go│ atoc_test.go│ atof.go│ atof_test.go│ atoi.go│ atoi_test.go│ bytealg.go│ bytealg_bootstrap.go│ ctoa.go│ ctoa_test.go│ decimal.go│ decimal_test.go│ doc.go│ eisel_lemire.go│ example_test.go│ export_test.go│ fp_test.go│ ftoa.go│ ftoaryu.go│ ftoaryu_test.go│ ftoa_test.go│ internal_test.go│ isprint.go│ itoa.go│ itoa_test.go│ makeisprint.go│ quote.go│ quote_test.go│ strconv_test.go│ └─testdata testfp.txt看着文件很多啊实际上一点也不少,但我们可以依照上述功能类型进行分类:
• 字符串转不同类型,ato的意思就是ASCII to的意思;类型有字符串转布尔,转整形,转浮点型,转字符(rune)。 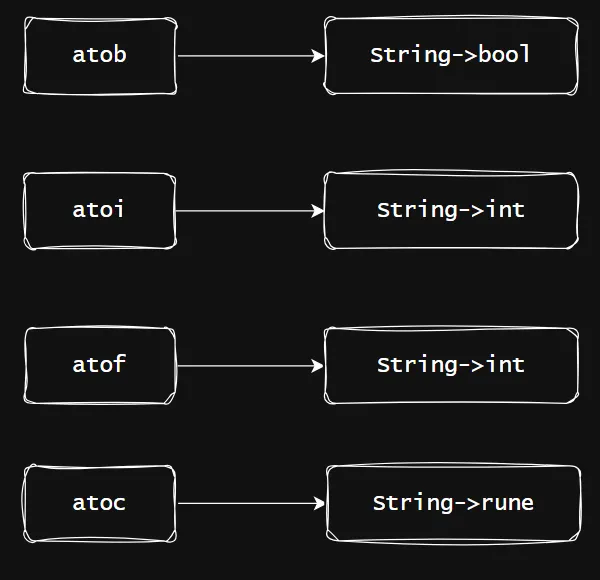
• 不同类型转字符串,因此这里toa的意思就是to ASCII;因此反过来就有整形、浮点型(Ryu算法实现)、字符转字符串; 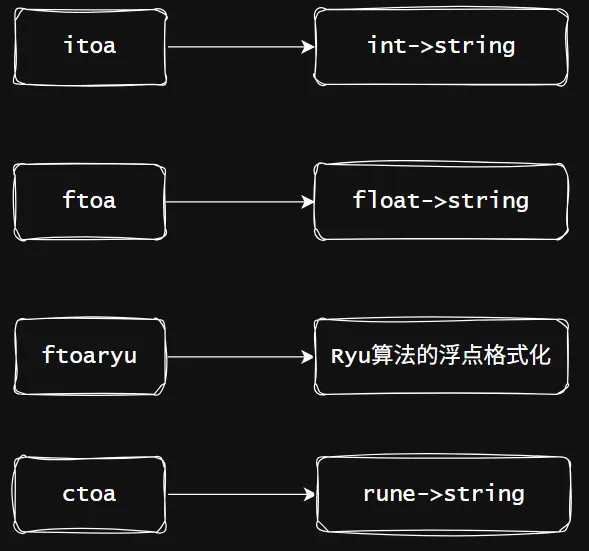
• 字符串转义、引号处理。 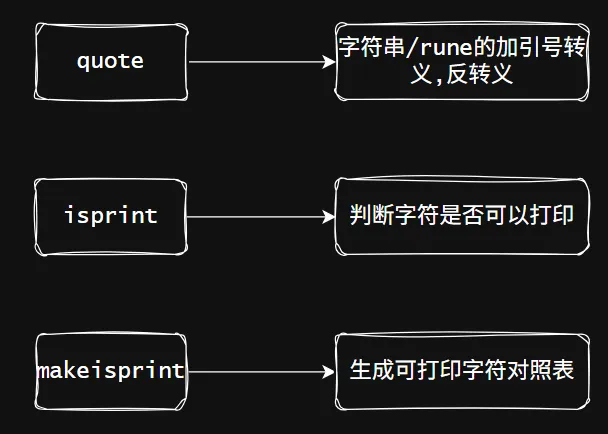
剩下没有提到的就是工具文件、文档和测试文件了,其中testdata/testfp.txt是浮点型转换的测试数据。下面将从这三个功能分类对strconv包功能和源码浅析。
字符串转不同类型
字符串转布尔类型
ParseBool方法,将字符串解析为布尔值,下面写的两个字符串会被转换成布尔类型的true/false,其实1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False这些都能转(源码中函数都定义好了)。
b1, _ := strconv.ParseBool("true")b2, _ := strconv.ParseBool("false")log.Println(b1, b2, reflect.TypeOf(b1), reflect.TypeOf(b2))// true false bool bool// ParseBool returns the boolean value represented by the string.// It accepts 1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False.// Any other value returns an error.func ParseBool(str string) (bool, error) { switch str { case "1", "t", "T", "true", "TRUE", "True": return true, nil case "0", "f", "F", "false", "FALSE", "False": return false, nil } return false, syntaxError("ParseBool", str)}字符串转整数类型
Strconv中对外暴露了ParseInt、ParseUint和Atoi这三个方法,功能都是将字符串转换为整数。Atoi用于快速转换十进制字符串,源码注释 Atoi is equivalent to ParseInt(s, 10, 0), converted to type int.,意思是该方法跟ParseInt(s, 10, 0)用法相同,下面来看看Atoi方法是怎么快速将字符串转十进制的:
1. 条件判断:intSize是编译器确定的常量,代表当前平台int类型的位数是32位或64位;对于32位int,sLen长度少于10位,转换后不会溢出int32;对于64位int,sLen长度少于19位不会溢出int64;在这种情况下(大部分就是这种场景,哪有那么大的数字整天转来转去的)走的是快速路径; 2. 快速路径:首先是符号处理,去掉-或+符号,并判断去掉符号后长度不能小于1;然后进入转换循环,遍历字符串中每个字节,从前到后累加构建整数(n = n*10 + int(ch)),就是88 = 8x10+8x1的意思;最后接上原字符串s[0]的正负号,还原数字正负。 3. 慢速路径:调用ParseInt(s, 10, 0)运行。
// Atoi is equivalent to ParseInt(s, 10, 0), converted to type int.func Atoi(s string) (int, error) { const fnAtoi = "Atoi" sLen := len(s) if intSize == 32 && (0 < sLen && sLen < 10) || intSize == 64 && (0 < sLen && sLen < 19) { // Fast path for small integers that fit int type. s0 := s if s[0] == '-' || s[0] == '+' { s = s[1:] if len(s) < 1 { return 0, syntaxError(fnAtoi, s0) } } n := 0 for _, ch := range []byte(s) { ch -= '0' if ch > 9 { return 0, syntaxError(fnAtoi, s0) } n = n*10 + int(ch) } if s0[0] == '-' { n = -n } return n, nil } // Slow path for invalid, big, or underscored integers. i64, err := ParseInt(s, 10, 0) if nerr, ok := err.(*NumError); ok { nerr.Func = fnAtoi } return int(i64), err}在Atoi的慢路径最后调用的是ParseInt方法,那这个方法到底怎么实现的呢,下面来看看~
ParseInt提供了进制和位宽选项,根据文档所述ParseInt可以按给定的进制(0,2-36)和位宽(0-64)解析字符串s;这时候就有彦祖要问了,进制能理解,但位宽是什么?位宽决定了允许的数值范围,例如int8的取值范围是:-128~127,int16的取值范围是:-32768~32767,位宽越大,范围越大,越不容易溢出;下面来看看函数是怎么做的:
1. 条件判断:空字符串、去掉正负号后为空字符串,直接返回报错。 2. 交给ParseUint,函数根据参数base进制将s转换为无符号整数um,并根据bitSize检查没有溢出; 3. 正负数边界的处理:若bitSize为0,将其设置为IntSize(确定的值,32/64);那么此时计算出来的cutoff就是有符号整数绝对值的临界值,正数最大值为cutoff-1,负数为-cutoff。再根据neg的值(false为非负数),这里有几种情况: 1. 为非负数时,且um>=cutoff时,此时已溢出了,返回最大值 cutoff-1再报个错;2. 为负数时,且um>=cutoff时,此时也溢出了,返回最大值 -cutoff再报个错;3. 为负数时,um<=cutoff,此时范围正确;为非负数时,且um<=cutoff-1,此时范围正确,都将un转为int64后返回;
func ParseInt(s string, base int, bitSize int) (i int64, err error) { const fnParseInt = "ParseInt" if s == "" { return 0, syntaxError(fnParseInt, s) } // Pick off leading sign. s0 := s neg := false if s[0] == '+' { s = s[1:] } else if s[0] == '-' { neg = true s = s[1:] } // Convert unsigned and check range. var un uint64 un, err = ParseUint(s, base, bitSize) if err != nil && err.(*NumError).Err != ErrRange { err.(*NumError).Func = fnParseInt err.(*NumError).Num = stringslite.Clone(s0) return 0, err } if bitSize == 0 { bitSize = IntSize } cutoff := uint64(1 << uint(bitSize-1)) if !neg && un >= cutoff { return int64(cutoff - 1), rangeError(fnParseInt, s0) } if neg && un > cutoff { return -int64(cutoff), rangeError(fnParseInt, s0) } n := int64(un) if neg { n = -n } return n, nil}我们看到两个函数层层转包,最后大部分活都是ParseUint干的,继续来了解这个幕后方法吧~
在ParseInt函数中,把正负号去掉后就调用ParseUint函数处理了,因此看ParseUint注释就有一句A sign prefix is not permitted.,不允许使用符号前缀,即不能以+/-符号开头。下面来看看方法是怎么转换的:
1. 条件判断:空字符串直接返回报错; 2. 根据前缀判断进制:若base不符合2-36这个区间,就啥也不干;如果base为0,先假设是10;然后是识别前缀,b是二进制,o是八进制,x是十六进制,其他情况当成八进制。 3. 临界值计算:cutoff是满足cutoff * base > maxUint64的最小整数,计算位宽允许的最大值maxVal。 4. 遍历字符串解析数字,如下划线处理、数字处理。最后得到n返回结果。
// ParseUint is like [ParseInt] but for unsigned numbers.//// A sign prefix is not permitted.func ParseUint(s string, base int, bitSize int) (uint64, error) { const fnParseUint = "ParseUint" if s == "" { return 0, syntaxError(fnParseUint, s) } base0 := base == 0 s0 := s switch { case 2 <= base && base <= 36: // valid base; nothing to do case base == 0: // Look for octal, hex prefix. base = 10 if s[0] == '0' { switch { case len(s) >= 3 && lower(s[1]) == 'b': base = 2 s = s[2:] case len(s) >= 3 && lower(s[1]) == 'o': base = 8 s = s[2:] case len(s) >= 3 && lower(s[1]) == 'x': base = 16 s = s[2:] default: base = 8 s = s[1:] } } default: return 0, baseError(fnParseUint, s0, base) }写在最后
Aoti是用来快捷处理十进制字符串转整数的方法,短字符串走快路径转换以提升性能,在慢路径下调用ParseInt函数处理;ParseInt是有符号的转换函数,可以通过进制和位宽限制实现转换,但其最后还是调用ParseUint实现;ParseUint是无符号的转换函数,通过前缀识别进制、遍历字符串解析得到数字。从Aoti到ParseInt,最后到ParseUint,这种代码复用避免了重复代码,也根据场景兼顾了性能,牛的bro。受限于篇幅,剩下的内容咱们下篇继续~
