 夜雨聆风
夜雨聆风📅 2026-06-13
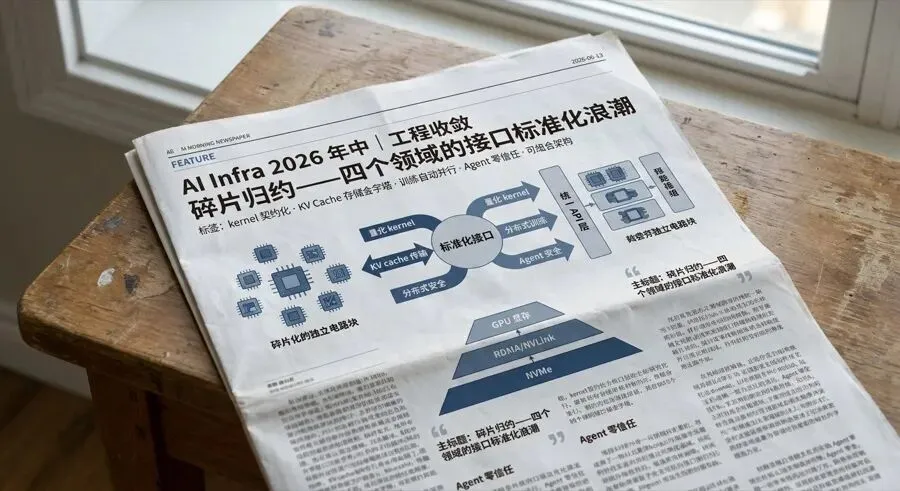
DeepSeek-V4 的部署需求正在推动各家推理框架加速梳理底层接口,vLLM、SGLang、TRT-LLM 本周同时在量化 kernel 和 KV cache 传输层做结构性收敛。四个独立领域不约而同在做同一件事——这个信号比任何单点性能突破都更值得关注。
量化内核侧|从各自实现到契约化接口
vLLM 本周引入了 QuantizedActivation 线性层契约 [1],不再把激活量化和线性计算耦合进同一个 kernel,而是在两者之间定义明确的接口边界。TokenSpeed 在 MoE 层面做了类似设计:统一 moe_apply API [2],上层调用不再需要知道底层跑的是 Gluon、TRTLLM 还是 Triton。量化推理的竞争力主线已经从"谁的 kernel 更快"转移到了"谁的 kernel 组合更灵活"。 标准化接口层是 quant fusion、自动 kernel 选择、异构混合部署的前提——没有它,每个新 kernel 都只能跟固定的上下游绑死。
两条可靠性修复进一步印证:NVFP4 在 DP attention 下空输入 crash,Gluon MoE GEMM 在长序列下数值错误——共同特征是单路径测试覆盖没问题,多并行策略组合时才暴露。如果统一 MoE API 在架构层面提供统一 guards,这类 bug 会从"各 backend 各自修"升级为"一层抽象统一防御"。属于 [持续更新]。
KV Cache 侧|统一 Device IR 正在闭合传输协议栈
Mooncake 本周做了传输架构上最重要的变更:将 EP 的 P2P 和 RDMA 路径从手工构造迁移到统一的 Device API [5]。上层调度逻辑不再需要区分"现在走的是 NVLink 还是 RDMA",只需调用统一的传输原语。 LMCache 把 KV cache 存储金字塔向下延伸了一层,引入 GDS(GPU Direct Storage)L1 slab-file tier,通过 cuFile DMA 直写本地 NVMe [6]——代价是增加了 NVIDIA GPU + NVMe 的硬件绑定。TRT-LLM 首次在 AutoDeploy 中支持 P/D 分离 [7],标志着 disaggregation 从社区框架正式进入 NVIDIA 官方产品线。
三件事拼在一起:Mooncake 向上建统一的传输接口,LMCache 向下延伸到本地 NVMe tier,TRT-LLM 补上 P/D 分离的官方支持——一个从 device IR 到存储分层的完整协议栈正在闭合。
训练与 Agent 侧|从手工配置到自动组合
TRL v1.6.0 将 AsyncGRPO 的 rollout 从线程升级为独立进程 [10]——之前 Python 函数与 PyTorch autograd 竞争 GIL,高并发场景下造成周期性停顿。这是一个典型的"用架构复杂度换确定性"的取舍,也是训练栈走向系统工程的标志。 DeepSpeed 的 AutoEP 自动检测 MoE block 结构并配置 expert parallelism [12]——训练框架正在从"用户手工配置"走向"自动检测 + 自动组合",与 2024-2025 年推理框架的系统化路径几乎完全同步。
Agent 基础设施本周也在经历类似的成熟期信号。OpenClaw v2026.6.6 收紧 sandbox、限制 MCP stdio 权限 [14],Agent 安全正从"信任 agent 不会做坏事"转向零信任/最小权限,评估体系从"跑一遍看截图"走向有 rubric 的工程化流程。
一句话结论:2026 年中,AI Infra 的关键词从"性能突破"换成了"接口标准化 + 自动组合"——四个独立领域同时在把碎片化底层实现收敛为可组合标准接口,这是整个生态的成熟度跃迁。
更多完整证据和技术细节,请点击文末“阅读原文”。
参考
[1] vllm#44260 QuantizedActivation linear-kernel contract:https://github.com/vllm-project/vllm/pull/44260
[2] tokenspeed#374 unified MoE kernel API:https://github.com/lightseekorg/tokenspeed/pull/374
[5] Mooncake#2382 EP integrate Device API (P2P/RDMA):https://github.com/kvcache-ai/Mooncake/pull/2382
[6] LMCache#3589 GDS L1 slab-file tier (cuFile DMA) for MP mode:https://github.com/LMCache/LMCache/pull/3589
[7] TRT-LLM#14057 AutoDeploy Basic Disagg Support:https://github.com/NVIDIA/TensorRT-LLM/pull/14057
[10] TRL v1.6.0 release notes:https://github.com/huggingface/trl/releases/tag/v1.6.0
[12] DeepSpeed#7938 AutoEP:https://github.com/deepspeedai/DeepSpeed/pull/7938
[14] OpenClaw v2026.6.6 release notes:https://github.com/openclaw/openclaw/releases/tag/v2026.6.6
Less hype · more systems.
MiracleFarms · BRIEF · DAILY
