 夜雨聆风
夜雨聆风
以前我在 GitHub 上找软件,经常遇到一种"差一点"的遗憾。
项目很棒,但功能太多,部署起来卡得像幻灯片,我想要的只是其中一小块。或者功能刚好,但它只有命令行界面,每次用都要对着黑框敲命令。再或者,项目只有 Mac 版、Linux 版,而我用的是 Windows。
这些问题我忍了好几年。直到最近,AI 编程工具成熟到一定程度,我突然发现——这些遗憾不再是遗憾了。

从下载者到改编者:
事情的变化发生在我开始认真用 AI 编程工具之后。从 OpenCode 到 Claude Code 再到 CODEX,这些工具让我可以跟代码"对话"了。我看不懂的代码逻辑,AI 能解释给我听。我不知道从哪里下手改,AI 能告诉我"这个功能在哪个文件里"。
最关键的是——我不需要自己会写代码,只要我能说清楚我想要什么。
这彻底改变了我跟开源软件的关系。以前我只是个下载者,看到喜欢的项目就 clone 下来,跑一跑,跑不通就放弃。现在我成了改编者——我把别人的代码变成我的代码,把"别人的软件"变成"满足我需求的软件"。
我改编了两个项目,感受完全不同
案例一:股票池量化工具,减肥并移植到移动端
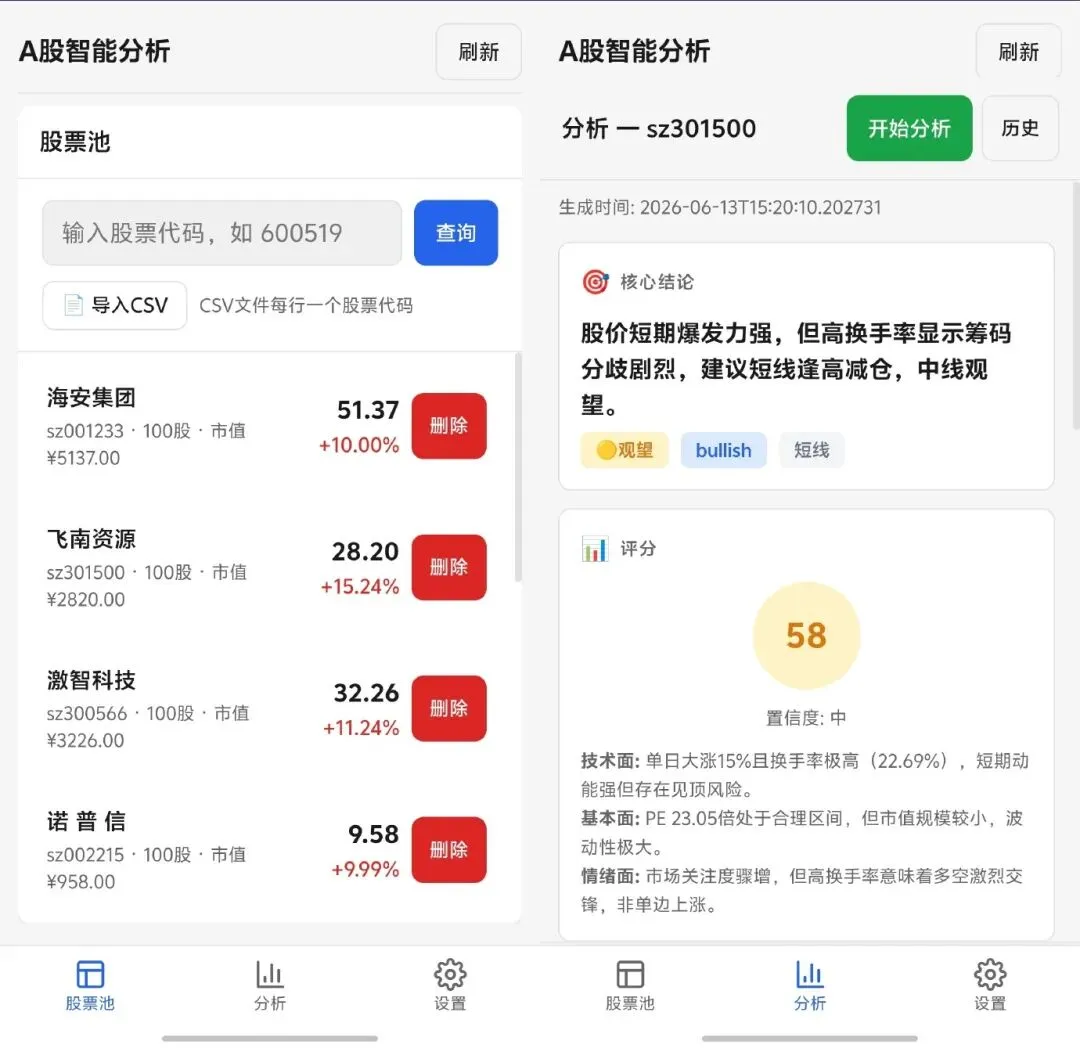
我最近在折腾股票量化,发现了一个 GitHub 项目,功能非常全:股票池管理、AI 分析、技术指标、回测系统……应有尽有。但等我部署上去,页面加载慢得让人崩溃。
仔细一想,我真正需要的其实就两个功能:一是股票池,二是 AI 评分和分析。其他全是噪音。
于是我打开 OpenCode,直接让它读这个项目的源代码,理解架构之后,重新建一个只包含这两个功能的网站。原型参考原项目的逻辑,但界面重新设计——我要做成移动端 APP 的风格,这样在手机上刷自选股才顺手。
不到十分钟,一个全新的、轻量级的股票分析页面就出来了。我把它推到 GitHub,再用 Hermes 部署到一个主机上,速度飞起。原项目加载要五六秒的页面,现在秒开。
案例二:纯 Python 量化选股库,给它加了个脸
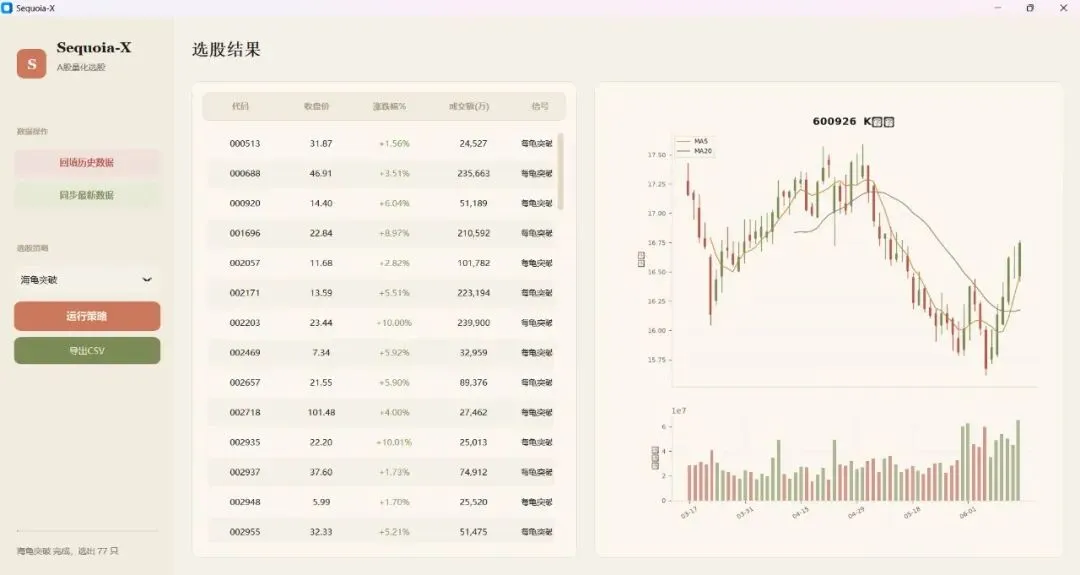
另一个项目是关于量化选股的,里面实现了海龟突破等各种经典策略的选股逻辑。代码写得扎实,100% Python,但——没有界面,纯脚本,跑完看命令行输出。
我做的事情说起来很简单:给它套一个 UI 界面。让它像真正的软件一样可以点、可以选参数、可以看结果图表。
这个过程比我想象中折腾。光给 baostock 回填数据加多线程就修了好几个 bug(建议想跟着做的人,碰到这种需要调试的场景,尽量用编程能力强的模型,GLM 和 KIMI 这些国内模型性价比不错)。
但最终做出来那一刻,成就感是实实在在的——一个原本只有黑框的命令行脚本,变成了一个可以拿给朋友看的桌面工具。
这两个案例的共性?都不复杂,技术含量不高,但它们精准地解决了我自己的痛点。 改编开源软件的价值就在这里——你不是在跟别人竞争功能多,你是在给自己造合脚的鞋。
AI 到底帮我做了什么?
如果细拆一下 AI 在"改编"这件事里扮演的角色,大概是这几步:
理解代码。 拿到一个陌生的开源项目,第一件事不是动手改,而是先搞清楚它的结构。我把整个项目丢给 AI,让它给我画个逻辑图:入口在哪、核心模块是什么、数据怎么流动的。这本来需要几个小时读代码,现在几分钟。
定位修改点。 搞清楚结构之后,我问 AI:"我想加一个功能 / 我想去掉一些模块 / 我想改成移动端布局,应该动哪些文件?"AI 能准确地指路。
实现修改。 确定目标文件之后,让 AI 写修改代码。这是最爽的一步——我描述需求,它生成代码,我粘贴、运行、看结果。
迭代验证。 跑起来几乎不可能一次完美。布局不对、数据不显示、接口报错——这些我都遇到了。但没关系,我直接把报错信息复制给 AI,它继续修。来回几轮,基本就稳了。
最真实的感受是:不是我自己学会了编程,而是 AI 成了我的翻译和助手。 我懂业务逻辑,我懂我想要什么,AI 负责把这两者翻译成代码。
改编开源软件的方法论
跑了几个项目之后,我总结了一套自己的套路:
选项目看协议。 开工之前先看一眼 License 文件。MIT、Apache-2.0 基本随便改(保留版权声明就行)。GPL 也能改,但改完如果分发,你的代码也要开源。不想碰法律风险的,避开那些没有协议或者协议不明确的项目就行。
定方向不贪多。 明确自己要加什么功能、改什么部分。野心太大容易陷入"改到一半发现改不动"的窘境。我最成功的改编都是目标极其清晰的:减功能、加 UI、改配色。而已。
一次只改一个功能点。 改完一个功能,跑通,确认没问题,再改下一个。否则出 bug 了你都不知道是哪一步引入的。
很多时候核心修改只是"个性化"。 改文案、改配色、改默认配置、改成中文。这些听起来简单,但恰恰是最提升幸福感的改动。一个英文界面的工具改成中文,体验差别巨大。
做好版本管理。 Fork 原项目,在自己的分支上改。这样如果原项目更新了,你还能合并上游的改进。不要直接在原仓库里改,否则后面想同步就难了。
重要的提醒:版权问题
说了这么多改编的好话,接下来这部分可能是全文最重要的话。
我先说清楚我自己的立场:我做所有这些改编,全部用于个人需求,没有任何商业性质。我不发布闭源的分发版本,我不拿它卖钱,我不声称这是我的原创。
为什么要把这句话放在前面?因为改编开源软件这件事,边界有时候会模糊。这里整理几条清晰的红线,大家共勉:
保留原作者版权声明。 这是底线中的底线。不管你怎么改,原项目的版权声明不能动。
不能去掉 License 文件。 很多项目之所以能让你改,是因为作者选择了开放协议。去掉 License 文件等于抹掉了作者给你的许可,这是最不应该做的事。
注意协议的类型。 如果你改编的是 GPL 或 AGPL 协议的项目,并且你会把修改后的版本发布出去,那你的代码也必须开源。MIT 和 Apache 协议则没这个要求,但必须保留版权声明。
绝对不能二次售卖。 即使你做了大量修改。开源的核心精神是共享,不是拿别人的作品经过改编去赚钱。
不能声称"这是我写的"。 哪怕你改了 80% 的代码,原作者构建的架构和付出的劳动也不该被抹去。标注"基于某某项目改编",是对他人劳动的起码尊重。
我的做法是:在自己的修改版里用 README 显著标注原项目地址、原作者信息和我的改动说明。 这样既尊重了原作者,也让别人知道这个版本从哪来的、改了什么。
说到底,正是因为开源社区慷慨分享,我们才有这么多优秀软件可以拿来改。改编不是掠夺,是站在巨人肩上做自己的东西。
一些不算总结的反思
关于能力边界。 虽然 AI 帮我改了不少项目,但遇到深层架构问题的时候,它也会有搞不定的情况。有些 bug 绕了好几圈都没修好。这种时候我反而更佩服原作者——能把一个项目做到结构清晰、可维护,本身就是一件了不起的事。
关于改编者心态。 我改了一行代码,和原作者写了十万行代码,差距是真实存在的。保持谦逊不是客套,是事实。
关于法律风险。 我只是个人使用,但不同国家地区对开源协议的法律解释不同。如果你计划做更多的事(比如发布、商用),建议咨询专业意见,不要只看我这篇文章就冲。
关于回馈。 如果你在用 AI 改编的过程中发现了原项目的 bug,或者做出了有价值的改进,向原项目提个 Pull Request 吧。或者给作者买杯咖啡。或者只是在社交媒体上推荐一下。这些都是很好的开源社区行为。
结语
AI 时代给了我这种非开发者一个前所未有的能力:改编软件。
不是从零开始写——那太难了。而是拿来已有的优秀开源项目,去掉我不需要的,加上我想要的,改成适合我的。这比从零开始写有价值得多,因为你站在了巨人的肩膀上。
如果你也有"某某软件要是能再加个这个功能就好了"的想法,现在真的可以去试试。开一个 OpenCode 或者 CODEX,把项目源码丢给它,告诉它你想要什么。从改一个小小的功能开始。
只是请记住:享受改编的乐趣,也尊重来源的善意。
PS:文中提到的 OpenCode、Claude Code、CODEX、GLM、KIMI、Hermes 均为 AI 编程或部署工具。提到的 baostock 是一个免费、开放的中国股市数据平台。我不是任何工具的代言人,单纯是一路用下来的真实推荐。
