 夜雨聆风
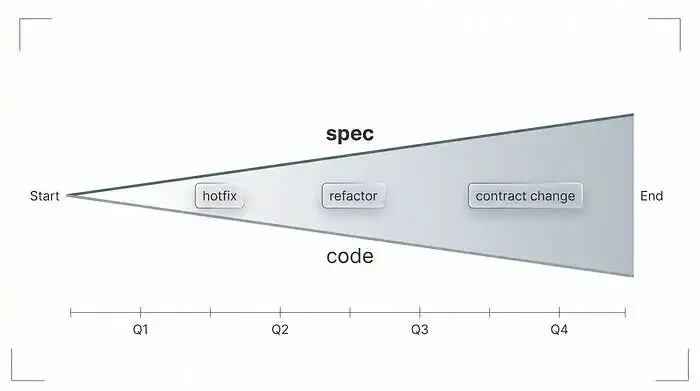
夜雨聆风你是不是也见过这样的场景:代码仓库里躺着四十几个版本的需求文档,文件名五花八门 ——spec_final_v2、spec_FINAL_THIS_ONE、spec_final_seriously_last_one,可没一个能准确描述线上运行的代码到底是什么样。
这不是教科书里的虚构案例,而是很多团队在用 AI 根据需求文档生成代码几周后,必然会陷入的困境。一开始一切都好,测试全过、团队士气高涨,可没过多久,最初的文档就悄悄和实际交付的代码脱节了。
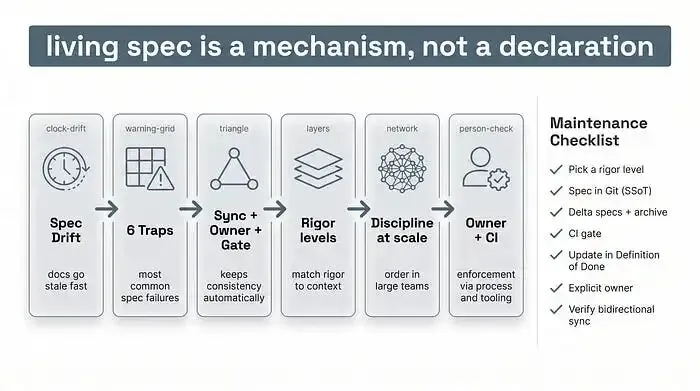
今天就和大家聊聊,为什么需求文档总会和代码渐行渐远,加速这种 “文档漂移” 的 6 个坑,以及能让 “活文档” 从空谈变成可落地产物的核心机制 —— 同步、责任人、门禁。
最核心的真相,一句话就能说透

“活文档” 从来不是文档本身的属性,而是围绕它搭建的流程体系的属性。一份文档能保持 “鲜活”,全靠有机制逼着它随每一次代码变更同步更新,这需要同时满足三个条件:
第一,自动同步—— 不管是用增量文档、还是 AI 比对文档和代码,总得有办法让文档贴近实际情况,而不是靠人记;
第二,唯一且明确的责任人—— 得有具体某个人负责核对校准,而不是模糊的 “团队负责”;
第三,CI 门禁—— 一旦文档和代码不一致,构建就直接失败。
少了其中任何一个,“活文档” 都会打回原形,变成没人看的陈年 Word 版本文档。最常见也最省钱的误区,就是觉得靠大家的自觉就够了。但事实是,没有机制约束的系统,漂移是默认状态。
其实这事儿和做工程一样好理解:把需求文档当成数据库 schema(模式)或者基础设施即代码(IaC)来看待就行。一个没有迁移方案、没有审核的 schema,一周就能和应用程序脱节,没人会觉得靠 “好心” 就能维护好它。需求文档也是同理,问题不在于写文档,而在于维护文档 —— 这是机制和责任归属的问题,不是技术问题。
如果只能花三分钟看这篇内容,就记住这句话:在添新工具之前,先确保同步、责任人、门禁这三样都到位。
想明白这个核心机制,我们先聊聊 “文档漂移” 本身到底是怎么回事。
为什么文档最后都成了抽屉里的摆设

“需求文档漂移”—— 也就是文档描述的内容和代码实际功能的偏差不断累积,从来都不是意外,而是没有机制约束下的必然结果。文档写一套,代码做一套,直到线上出问题才被发现,这是常有的事。
漂移的模式其实很有规律:API 签名改了,文档说明还停留在老版本;重构代码时悄悄删掉两个字段,文档里却还写着必须包含这两个字段;契约变更没做版本控制,下游使用者只能从报错里发现问题。
这些情况单看都不算大事,但合在一起就足以致命。
背后的原因其实特别贴近日常工作状态:开发者知道文档需要更新,但转头就去处理下一个工单,心里想着 “回头再更”。可实际情况是,“回头” 基本等于 “永远不”—— 这不是因为懒,而是在紧急修复和截止日期的压力下,文档维护永远排不上优先级。
在 AI 辅助开发的时代,这种漂移还会被放大。第一周大家都觉得顺风顺水:AI 生成代码又快又好,测试全过,团队都很兴奋。可几周后,和文档脱节的代码成了下一轮 AI 调用的基础,团队开始调试那些源于过时文档的错误结论。一份失效的文档不是中立的,它会污染后续每一次迭代。
更糟的是,当文档的错误多到一定程度,开发者就不再信任它了。每句话都要去核对代码,文档从参考依据变成了质疑的起点。一份没人信的文档,比没有文档更费成本,因为它还假装自己有参考价值。
有个流传很广的说法得澄清下:“约 70% 的团队放弃文档” 这个数据并没有可靠来源。但趋势是明确的:对 3000 多个 GitHub 项目的分析发现,绝大多数项目的文档都曾出现过失效的引用(arXiv 2212.01479);近 29% 把示例当作验收标准的团队,完全没有自动化这些示例(Adzic 2020 研究,样本量 339)。
很多开发者都坦言,写文档是他们最抗拒的工作之一 —— 这一点也被不少实践研究印证。核心问题不是写,而是维护。
想通这一点,就别再问 “怎么让团队更自律”,而是要问 “该设计什么机制来强制更新文档”。既然漂移不可避免,我们就来看看它最常出现在哪些地方。
搞垮需求文档的 6 个坑

这 6 个坑不是孤立的问题,而是同一个核心问题的 6 种表现形式—— 缺少文档维护机制。把这份清单当成诊断表:认出自己踩了哪个坑,就知道该补机制里的哪块短板(同步、责任人、门禁)。

6 种失效模式
“抽屉文档”:项目启动时读一遍需求文档,之后就束之高阁。文档只在开头 “活” 过一次,因为没有任何机制逼着它更新。这是最经典的 “一次性使用致死”。
“双重真相源”:给 AI 生成的代码做版本控制,却不管生成代码的需求文档。搞反了关键的依赖关系:维护输出物,却抛弃了源头。迭代几次后,根本没法还原代码为什么是现在这个样子。
“无人负责”:所有人都以为别人会更文档,最后没人更。工具割裂会让问题更严重:文档存在 Notion,API 契约在 Swagger,设计稿在 Figma,彼此完全脱节。模糊的责任归属是隐形杀手。
“无 CI 门禁”:没有自动的契约校验,文档和代码的偏差悄无声息溜到线上。漂移从 “显眼的问题” 变成 “沉默的隐患”,而沉默的漂移永远会赢,因为没人及时制止它。
“过度版本化(也就是 47 个版本的坑)”:不归档变更记录,反而复制出一堆完整的文档副本。最后文件多到像一片森林,就像有团队吐槽的:“最新的页面说了算,不管它描述的是哪个版本的系统。” 这不过是把漂移包装成了有序的样子。
“手动同步”:靠记性和自觉维护文档。改一次 UI,就要手动改几十条 Given-When-Then 场景。但凡维护过遗留 BDD 套件的人都知道,手动同步根本无法规模化。
我见过的大多数团队,不是只踩一个坑,而是同时踩三个。最常见的组合就是:无人负责 + 无 CI 门禁 + 过度版本化。这不是运气差,而是缺少流程架构设计。知道了这 6 种失效模式,该说说怎么解决了。
核心机制:同步 + 责任人 + 门禁,还有匹配风险的严谨度

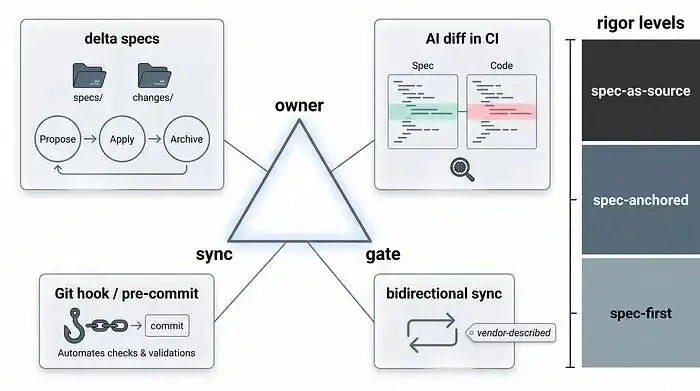
没有任何一款工具能 “解决” 漂移问题,真正管用的是同步 + 责任人 + 门禁这三件套,而且要根据风险调整严谨度,不是跟风选最 “高级” 的。接下来提到的工具,只是这个核心机制的落地形式,不是非选不可的 “标准答案”。真正该做的工程决策,不是 “选哪个工具”,而是 “要多高的严谨度”。
增量文档与变更归档

先理清一个思路:维护需求文档,该像维护数据库 schema 那样 —— 靠迁移,而不是重写整个文档。不会因为改了一行内容,就重新写一遍整个文件。
“增量文档” 就是这个思路的落地:只描述变更点 —— 新增了什么、修改了什么、删除了什么,而不是写完整文档。实际操作中,specs/目录存 “当前状态” 的基准文档,changes/目录存变更提案。“提案→应用→归档” 的流程会把增量内容合并到基准文档里,再把变更记录按日期归档,形成可追溯的审计轨迹。这也能解决 “47 个版本” 的问题:归档变更,而非复制副本。
不过有个坑要注意:增量工具的专用表述可能会混入正式文档,比如留下 “已删除字段 X” 这类记录,时间久了就成了无效信息。
AI 比对与 CI 门禁

第二个关键是,在漂移到线上前就发现它。用 AI 比对文档和代码,做的是语义层面的对比,不是字符串匹配:模型读文档、分析代码、标记偏差,要么自动提 PR,要么直接让构建失败。这种检测能力是正则表达式比不了的,因为偏差很少是字面意义上的不一致。这类工具还在迭代中,落地前最好验证下具体效果。
但也要承认一个局限:只在 CI 阶段运行的工具,只能在部署时发现漂移,没法在变更刚发生时就检测。两次部署之间,偏差可能悄悄累积。
这时候就需要CI 门禁—— 比如提交前的钩子:只要/src目录有变更,就必须同步改/docs目录;或者加契约校验,文档和代码不一致就不让合并。这是 “完成定义(Definition of Done)” 最简单的落地方式:功能没更文档,就不算做完。门禁让漂移从 “默默累积” 变成 “即时暴露问题”—— 而这正是我们想要的效果。
双向同步:是工程方案,还是营销话术?

现在市场上最吸引人的说法,就是 “双向同步”—— 改代码自动更文档,改文档自动更代码,两边永远同步。听着好像能一劳永逸解决问题。
但得保持理性:这类说法大多来自厂商宣传,还没有独立验证的结果 —— 很多厂商自己也承认这一点。有从业者质疑,文档的核心价值不是 “双向同步”,而是可执行性—— 文档是真的能验证代码,还是只是好看的文字,和代码摆在一起而已?目前也没人能证明,双向同步在老旧的遗留代码库(棕地)里能规模化落地。
选这类工具时,不妨问自己:它是验证正确性,还是只是协同编辑文本?
严谨度分级:该 “较真” 时才较真

把上面这些机制用起来,还要匹配对应的严谨度。有个很实用的分级思路(是一位从业者在分析 SDD 工具时提出的),分三个级别:
文档优先:合并后文档可以 “失效”。零维护成本,但相当于主动接受 “抽屉文档” 的结果。适合一次性的探索性工作。
文档锚定:文档作为和系统一起演进的核心锚点。只有严格遵守 “先改文档,再改代码”,才能落地。这是大多数生产系统的最优解。
文档即源码:只改文档,代码全靠生成。严谨度最高,但也面临输入层面模型非确定性的风险。
选择原则很简单:严谨度匹配风险和复杂度 —— 别用大炮打蚊子。多数团队对生产环境用 “文档锚定”,对原型用 “文档优先” 就够了,很少需要中间状态。
理论听着很清晰,但放到成百上千人的团队里,实际落地是什么样?答案可能比厂商宣传的 “魔法方案” 实在得多。
大厂实操:没有 “魔法同步”,只有流程纪律

这里要纠正一个常见认知:规模化落地时,根本没有 “文档和代码自动同步” 的魔法操作。那些 “数百团队都能自动维护文档” 的说法,在实际落地案例里根本找不到依据。真正管用的,是契约纪律 + 人工介入。
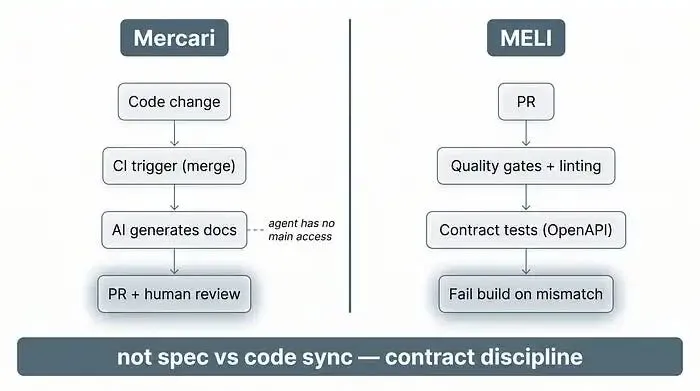
案例 1:AI 写文档,人来审核

有大厂的做法很务实:AI 没有主分支的写入权限。代码合并时,CI 触发模型分析变更,生成更新后的文档,单独提 PR 等待人工审核。触发时机只限于合并和发布事件 —— 部分原因是控制成本,每次执行成本约 50 美分。同时保留标准的人工设计文档流程:预计耗时超一个月的工作,都要先写设计文档。
这是让文档贴近代码,而非文档和代码双向同步。
案例 2:用契约代替同步

另一家大厂的思路不同:靠契约。他们的内部开发者平台(团队部署代码的统一网关)会在每个 PR 里,对代码做自动质量门禁、校验和代码检查。在此基础上,还会对 API 接口跑契约测试:服务消费者定义预期的契约,只要不匹配,CI 流水线在变更进入集成阶段前就会失败。这是 “左移” 的纯粹落地形式 —— 同样,全程没有文档和代码自动同步的痕迹。
这家公司的规模很有参考性:数万名工程师、每天数十万次部署、数万个微服务。但规模只是背景,不是 “魔法同步” 的证明。
核心结论很明确:别再找 “文档即基础设施” 的神奇工具了,不如搭建真正能规模化落地的体系 —— 契约、门禁、人工审核。
既然规模化落地靠的是纪律,那还有个绕不开的组织问题:到底该谁来管文档?
文档该归谁管?

“伟大的代价是责任。”
文档所有权不是头衔,而是被强制执行的责任。常有人争论 “该产品经理管还是技术负责人管”,其实问错了问题。没有唯一正确的模式,但有一条铁律:责任必须明确,且在审核环节强制执行。
有个经典的思路值得参考:给文档指定一位署名作者,对内容全权负责。这仍是最清晰的问责模式,就算不照搬,也能作为参考基准。
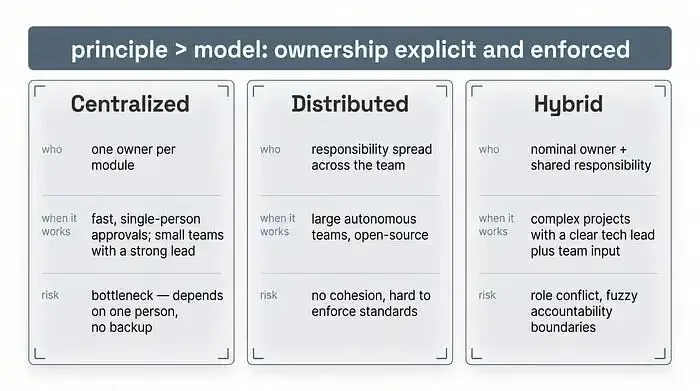
三种归属模式
实操中常见三种模式:
集中式:每个模块对应一位负责人,就像上面说的 “署名作者”;
分布式:责任分散到整个团队;
混合式:名义上有一位负责人,同时团队共同担责。
要注意的是:所谓 “集体所有权”—— 只说 “所有人都负责”,却没有流程层面的强制约束 —— 最后往往是没人觉得自己该负责,规模一大就会崩盘。
原则比模式更重要

有个有意思的反例:某大厂把文档责任分散到 QA、产品、研发团队,核心思路是 “质量是整个 Scrum 团队的责任,不是某一个角色的事”。他们的文档能落地,是因为靠流程维护,而非靠头衔约束—— 审核和 CI 机制能做到单个人做不到的事。
“强制执行” 是关键词:绕过文档的变更会被 CI 标记;审核时总会问 “这部分在哪里记录了?”;用统一的 ID 把需求、文档、代码、测试关联起来(比如 REQ-123),让偏差无处隐藏。
需求→文档→代码→测试的链路,把 “自觉” 变成了可验证的审计轨迹。
有个研究结论值得重视:只发现漂移,并不会自动修复漂移。没有真正担责的人,CI 告警不过是又一条被忽略的通知。模糊的责任归属,比差工具更能搞垮文档。最后,把这些内容整合为一套能直接落地的做法。
总结:让文档 “活” 下去的检查清单

回到开头那 47 个文档版本的问题:靠团队 “更努力” 解决不了,只有围绕文档搭建机制,问题才会消失。文档是机制,不是口号—— 同步、责任人、门禁缺一不可,否则只是换了个地方存的版本化 Word 文档。
分享一份可直接复用的文档维护清单,明天就能用:
给每个文档定严谨度级别 —— 生产环境默认选文档锚定,原型选文档优先;
把文档和代码一起存在 Git 里,作为唯一真相源,别存在孤立的工具里;
用增量文档(新增 / 修改 / 删除)和变更归档,代替复制多份版本;
搭建CI 门禁:文档和代码不一致时,通过 AI 比对或契约测试让构建失败;
把文档更新纳入 “完成定义” 和审核流程 ——“这部分在哪里记录了?” 要成为常规问题;
给每个模块指定唯一且明确的负责人—— 并在审核中强制执行;
对厂商的 “双向同步” 宣传保持理性 —— 先问清楚工具是验证正确性,还是只做协同编辑。
就算忘了其他内容,也请记住这 5 点:文档是一套机制(同步 + 责任人 + 门禁),不是一句口号;6 个坑都是缺少机制的表现;严谨度要匹配风险,而非跟风;规模化落地靠契约纪律,而非魔法同步;没有明确且被强制执行的责任人,再好用的工具也救不了文档。
感谢读到这里 —— 这是 SDD 落地中最实用,却也最不 “光鲜” 的部分,很珍惜你的时间。如果这篇内容改变了你对文档维护的看法,不妨分享给正在落地 SDD 却踩坑的朋友。也欢迎在评论区聊聊,你所在的团队踩过的 “第七个坑” 是什么?
