 夜雨聆风
夜雨聆风「AI 看不懂屎山代码,不是因为它不够聪明——是因为你把所有隐性约束都写成了代码。而代码是 AI 最差的输入格式。」
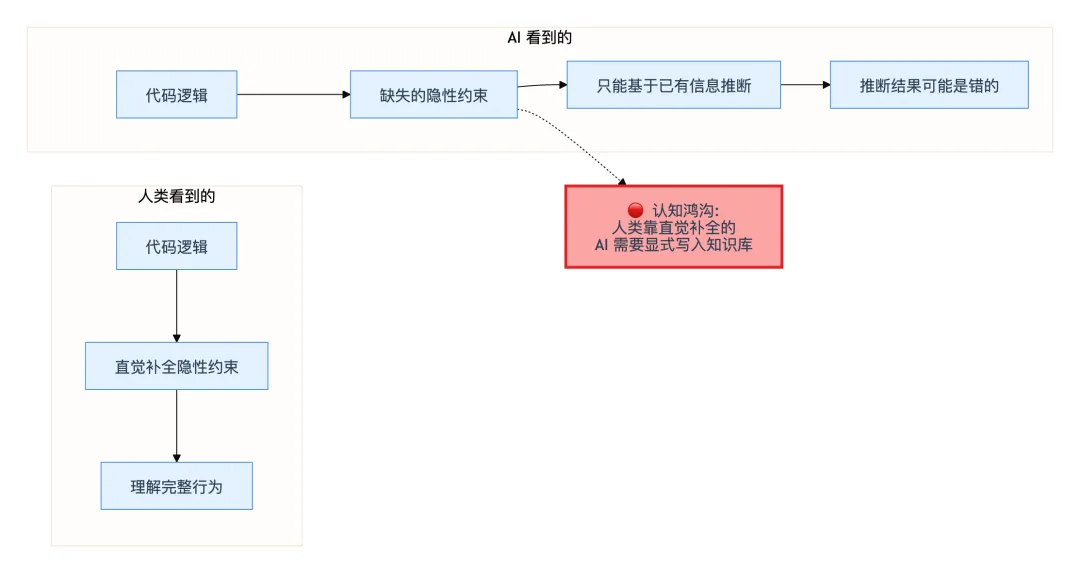
场景还原:AI 和你的认知鸿沟
你把支付回调模块的代码贴给 AI:"帮我理解这段代码,然后写一份概要。"
AI 读了几分钟。返回了一份分析:
这是一个支付回调处理模块,主要处理支付宝、微信、银联三种渠道的回调。代码结构不够清晰,建议使用策略模式重构。
你觉得 AI 说得没错——代码确实不够清晰。但你心里也知道,AI 完全没有触碰到这个模块的核心。它不知道:
支付宝的 sub_trade_type字段是支付宝文档里没写但回调里会返回的扩展字段——库存回补全靠它微信的金额负数修正是微信支付团队确认过的已知 bug——修正逻辑不能提取到"公共校验层" 银联的回调在 2021 年升级过接口——现在的新旧两种格式并存,需要兼容处理
这些东西没有一个写在代码注释里,更没有一个写在文档里。它们存在于以前同事的离职交接邮件里、三年前的线上事故复盘文档里、和支付渠道的对接聊天记录里——对这些信息,AI 完全是盲的。
AI 和屎山之间的核心矛盾不是"AI 太笨",是"知识在代码里的表达方式 AI 无法消费"。
第一层:问题诊断——为什么 AI 看不懂屎山
要给 AI 看懂屎山,得先精确理解"看不懂"的根因在哪。不是"代码太乱"这种模糊的判断——是知识在什么形式上出现了断裂。
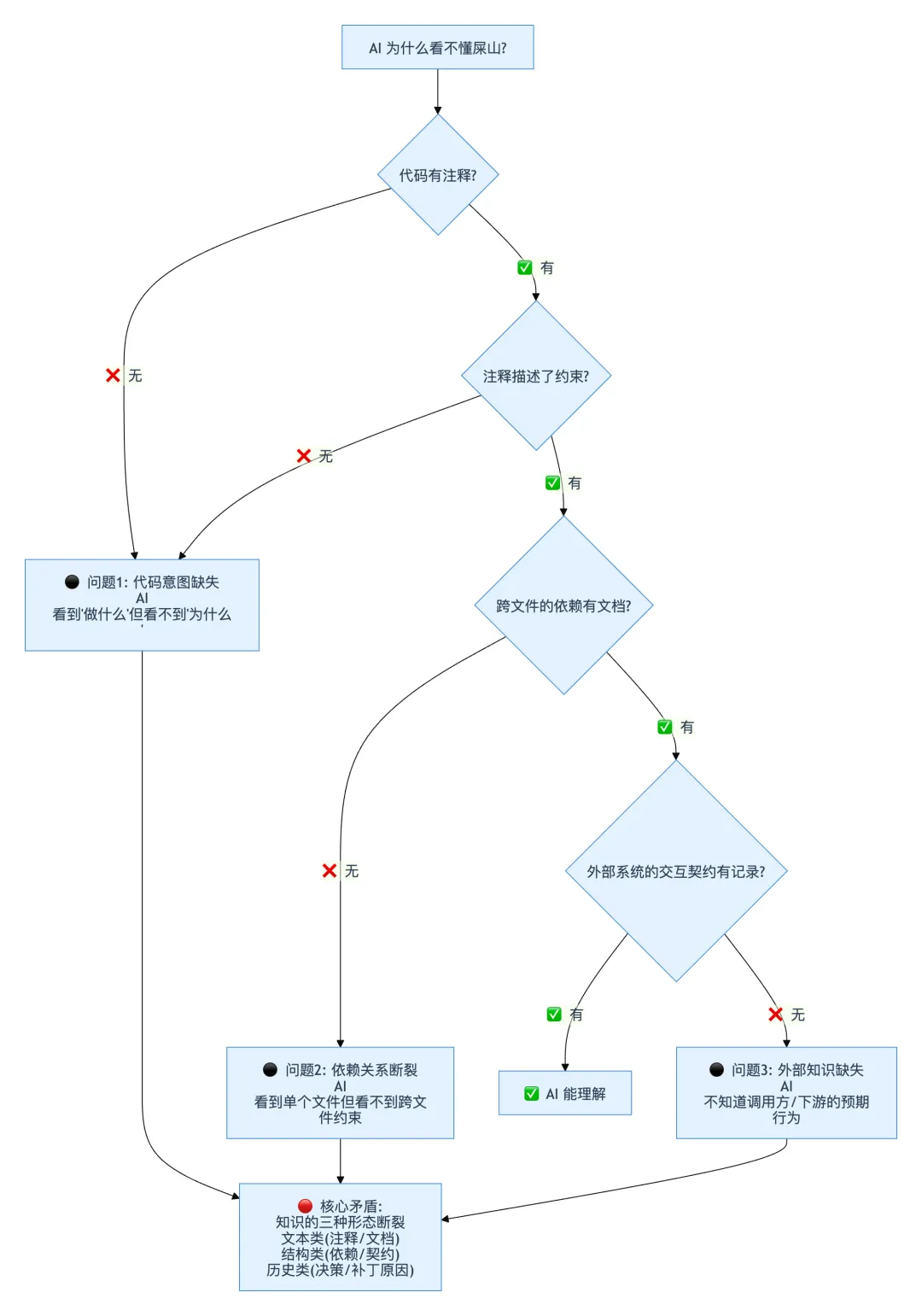
诊断结论:屎山项目的知识以三种形态存在——文本类(注释和文档)、结构类(模块依赖和 API 契约)、历史类(架构决策和补丁原因)。AI 需要的不是"更多代码",而是这三种形态的知识被提取为结构化文档,让 AI 不用从代码中逆向推断。
| 文本类 | |||
| 结构类 | |||
| 历史类 |
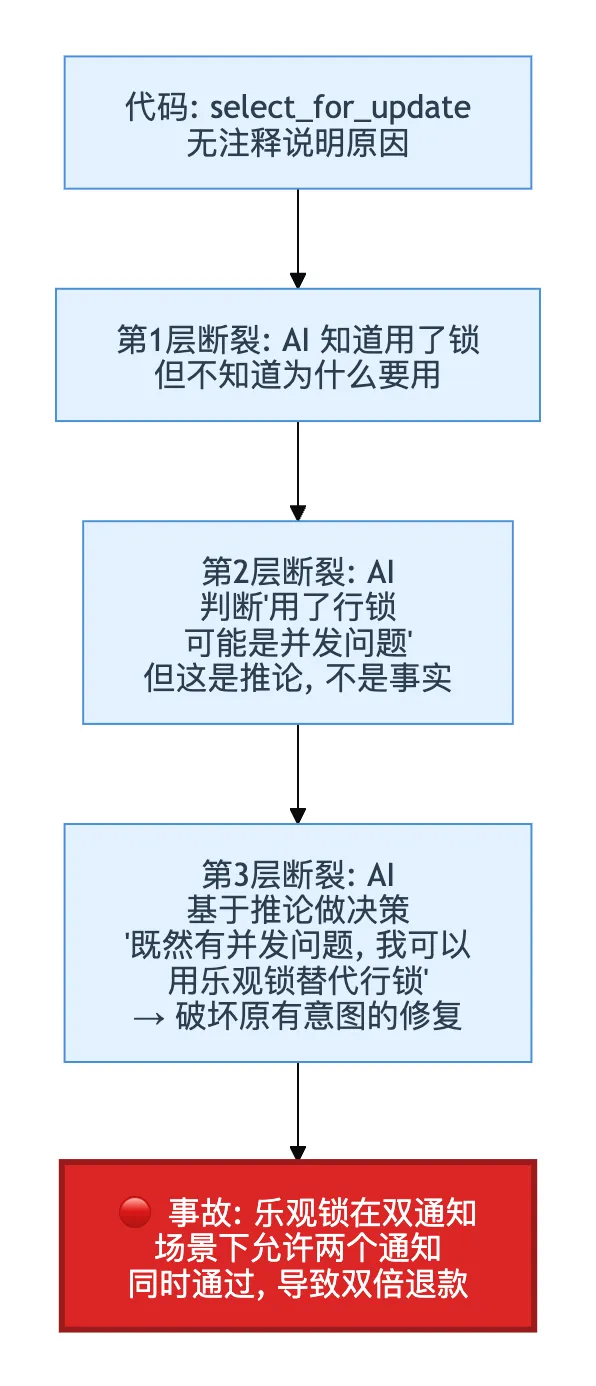
一个具体的知识断裂案例
# ═══════════════════════════════════════════════════════════
# AI 只能在代码中看到的
# ═══════════════════════════════════════════════════════════
defhandle_refund_callback(data: dict) -> bool:
order = Order.objects.select_for_update().get(id=data["order_id"])
# ── AI 视角 ──
# select_for_update() 会锁定这行记录,直到事务提交
# 为什么退款回调需要行锁?可能有并发问题
# ── AI 不知道的 ──
# 支付宝的退款通知和微信的退款通知可能在毫秒内同时到达
# 如果不加行锁,两个通知同时处理会导致双倍退款
# 这是2020年"618退款翻倍事故"后的修复——select_for_update 不是设计选择,是止血措施
# ── AI 视角 ──
# trade_status 是交易状态,为什么退款回调里要检查?
# ── AI 不知道的 ──
# 支付宝在退款成功后可能会再发一条 trade_status='TRADE_CLOSED' 的通知
# 这条通知不应该触发退款逻辑——需要在入口就过滤掉
# 支付宝文档里没有明确说明这个行为,是我们对接时踩到的坑
if data.get("trade_status") == "TRADE_CLOSED":
returnFalse# 不做处理
# ... 后续退款逻辑知识断裂的三层放大效应:
第二层:根因分析——"给人看的文档"和"给 AI 消费的知识"有什么本质差异
第一层诊断了"知识以什么形式断裂"。第二层追问:如果我现在开始补文档,应该写成什么样子 AI 才能消费? 因为大多数开发者的直觉是"写一份架构文档"——但这类文档是给人看的,对 AI 来说粒度太粗、表达太模糊。
给人看的文档 vs 给 AI 消费的知识
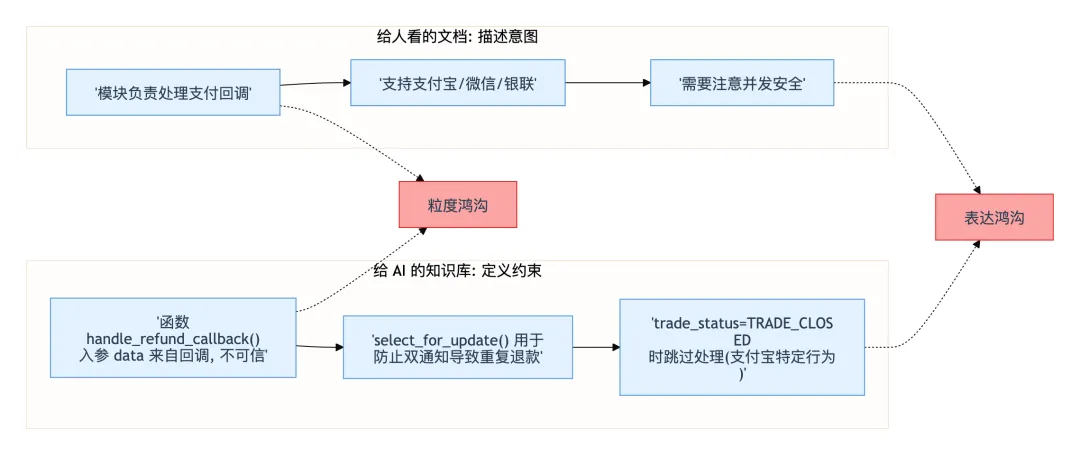
对比两者的本质差异:
| 粒度 | select_for_update() 的存在是为了防止 2020 年的双退款事故" | |
| 表达 | ||
| 完整度 | ||
| 结构 | ||
| 更新周期 |
粒度的本质差异
以"支付回调"为例:
# ═══════════════════════════════════════════════════════════
# 给人看的文档:一段话即可
# ═══════════════════════════════════════════════════════════
human_doc = """
支付回调处理模块负责接收支付宝、微信、银联三方的回调通知,
验证签名后将回调数据转换为内部格式。
需要注意支付宝可能发送重复通知,需要做去重处理。
"""
# ═══════════════════════════════════════════════════════════
# 给 AI 的知识库:每条约束精确到可执行
# ═══════════════════════════════════════════════════════════
ai_knowledge = {
"module": "payment_callback",
"constraints": [
{
"id": "C001",
"type": "security",
"description": "防伪造校验: order_id 和 amount 来自回调不可信",
"logic": "通过 select_for_update() 读数据库获取真实订单状态和金额",
"code_location": "handle_refund_callback:line 45",
"test": "传入伪造的 amount=99999, 断言实际使用的是数据库中的真实金额"
},
{
"id": "C002",
"type": "business_rule",
"description": "支付宝重复通知去重",
"logic": "notify_type='async' 时检查 notify_id 是否已存在于 dedup_cache(Redis)",
"code_location": "handle_refund_callback:line 32",
"test": "连续发送两个相同 notify_id 的通知, 断言第二个被跳过"
},
{
"id": "C003",
"type": "compatibility",
"description": "微信金额负数修正",
"logic": "amount < 0 时取绝对值, 不能 raise 异常(否则正常退款被阻断)",
"code_location": "handle_refund_callback:line 78",
"reason": "微信已知 bug, 在他们修复之前必须容错",
"test": "传入 amount=-100, 断言内部使用 abs(100) 且不抛异常"
}
]
}关键差异:给人看的文档中"需要注意支付宝可能发送重复通知"这句话,AI 需要自行推断"在哪里做去重、用什么机制去重、去重失败了怎么处理"。给 AI 的知识库中 C002 精确到"在 notify_type='async' 时检查 notify_id 是否存在于 Redis 的 dedup_cache 中"——AI 不需要推断,直接执行。
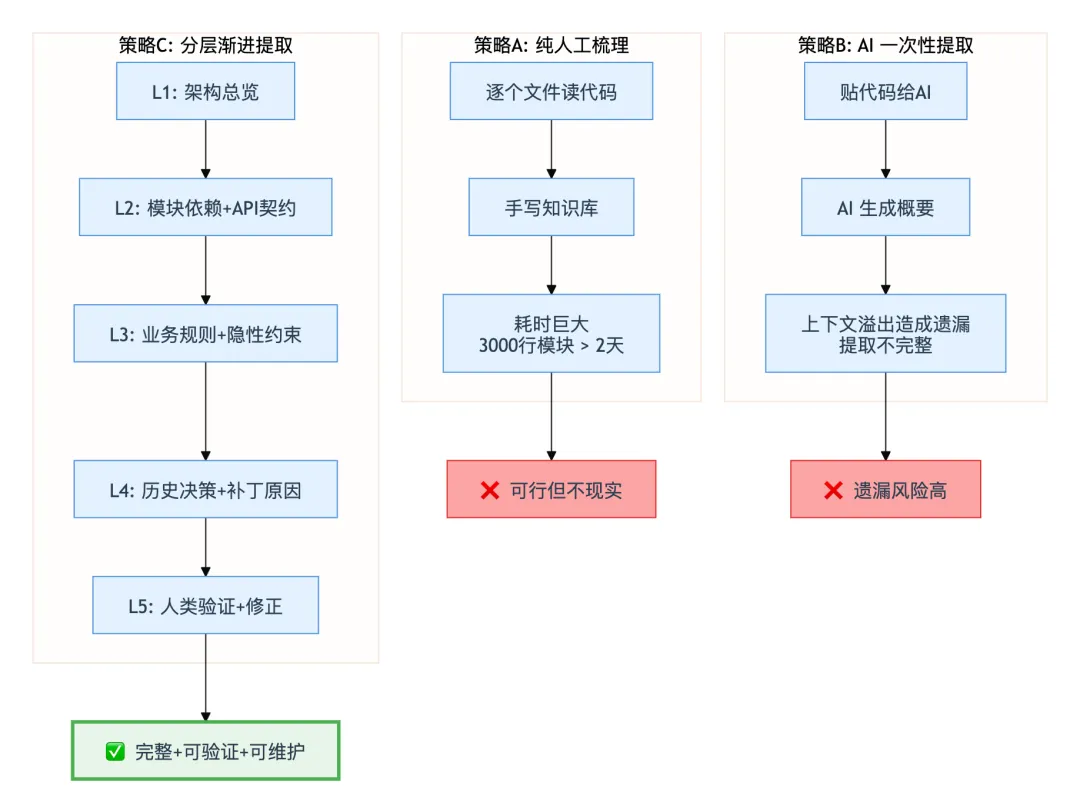
第三层:策略对比——三种知识提取方式
第一层诊断了问题(知识断裂),第二层分析了要求(粒度差异)。第三层对三种不同的知识提取方式进行对比。
| 纯人工 | |||
| AI 一次性 | |||
| 分层渐进提取 |
分层渐进提取的递进逻辑
不是"把代码拆成小块逐块分析"——这只是物理切分。分层渐进提取的核心是按知识类型分层,每层用 AI 辅助提取,人类验证:

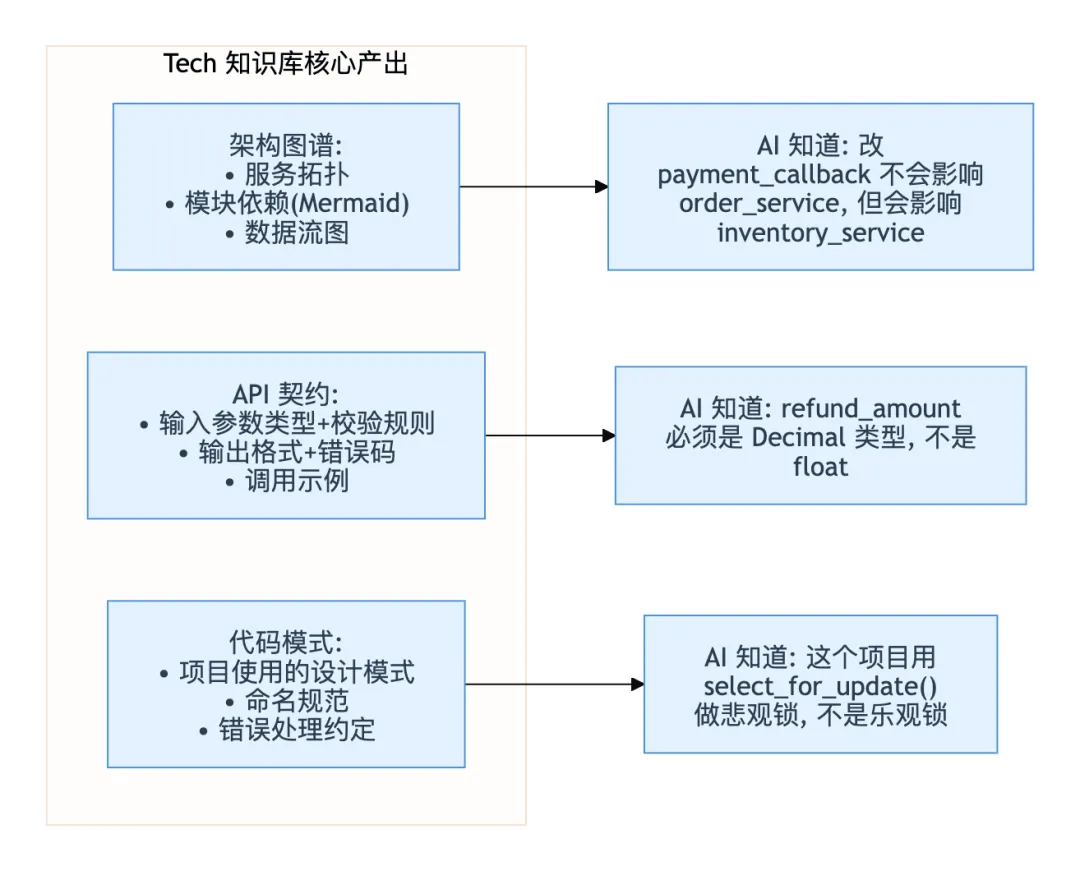
第四层:三模知识库——系统性方案
前三层完成了"问题→要求→策略"的分析。第四层给出系统性的知识库设计——参考 knowledge-init skill 的三模结构,为 AI 提供完整的项目理解。

Business 业务知识库:让 AI 理解"做什么"
业务知识库回答的问题是:"这个项目在业务上做了什么,用什么术语,有什么规则。"
# .aisdd/knowledges/business/glossary.md
# 业务术语表 — 消除 AI 对术语的歧义
terms:
-term:"退款 (refund)"
definition:"用户支付的款项退回给用户。分为全额退款和部分退款"
related: ["支付回调", "订单状态", "库存回补"]
ai_note:"refund 不等于 cancel——cancel 是未支付取消, refund 是已支付退回"
-term:"库存回补 (inventory_restore)"
definition:"退款后将商品库存数量恢复。仅在支付宝渠道场景下触发"
channel_specific:"alipay"
ai_note:"微信和银联在支付环节已预扣库存,不需要回补。不要把回补逻辑提取到通用退款层"# .aisdd/knowledges/business/rules-config.md
# 业务规则配置 — AI 可直接消费的规则
rules:
-id:"RULE-REFUND-001"
description:"支付宝退款触发库存回补"
condition:"channel == 'alipay' AND sub_trade_type == 'refund'"
action:"调用 restore_inventory(order_id)"
priority:"critical"
reason:"支付宝渠道设计和微信/银联不同——这不可修改"
test:"模拟 alipay 退款回调, 验证 inventory 数量是否正确恢复"
-id:"RULE-REFUND-002"
description:"退款金额不能超过订单金额"
condition:"refund_amount > order.total_amount"
action:"拒绝退款, 返回 AMOUNT_EXCEEDS"
priority:"critical"
reason:"防止超退——基本财务安全"
test:"传入 refund_amount=99999, order.total_amount=100, 断言返回 AMOUNT_EXCEEDS"Tech 技术知识库:让 AI 理解"怎么做"
Tech 知识库回答的问题:"这个项目在技术上怎么实现的,模块之间什么关系,API 长什么样。"
# .aisdd/knowledges/tech/contracts/payment_callback_api.md
# API 契约 — 精确到类型和约束级别
# ═══ 函数: handle_refund_callback ═══
"""
Input:
data (dict): 回调通知, 来自第三方支付网关
注意: data 不可信——所有字段在内部重新从数据库获取
data 结构:
{
"order_id": str, # 订单号, 必填, 格式: ORD-{timestamp}-{random}
"amount": float, # ⚠️ 不可信! 内部用 Order.total_amount 覆盖
"channel": str, # 渠道: "alipay"|"wechat"|"unionpay"
"notify_type": str, # 通知类型: "async"|"sync", 支付宝特有
"notify_id": str|None, # 通知ID, 用于去重, 支付宝异步通知必传
"trade_status": str, # 交易状态, TRADE_CLOSED 时不处理
"sub_trade_type": str, # 子交易类型, "refund" 表示退款, 支付宝特有
}
Output:
bool: True=处理成功, False=跳过处理(TRADE_CLOSED)
Side Effects:
- 数据库: SELECT ... FOR UPDATE (行锁)
- 数据库: UPDATE inventory (仅支付宝退款)
- Redis: SET dedup_cache:{notify_id} (去重)
- 通知: 发送退款处理结果通知 (事务内)
"""Engineering Manual:让 AI 理解"怎么协作"
Engineering Manual 回答的问题:"这个项目怎么运行、怎么贡献、有什么历史决策。"
| project-overview.md | ||
| quickstart.md | ||
| faq.md | app:prod: 不是 app:" | |
| adr/ADR-001.md | ||
| external-integrations.md |
知识库的 INDEX.md 全局索引
# .aisdd/knowledges/INDEX.md — AI 的导航地图
index:
project:"电商平台支付系统(存量改造项目)"
business:
-glossary:"术语表: refund/callback/settlement 等 27 个术语"
-domain_model:"核心实体: Order/Refund/Inventory/Payment 的 ER 图+状态机"
-rules:"12 条关键业务规则, 7 条有 channel_specific 限制"
tech:
-architecture:"Django + PostgreSQL + Redis, 3 个核心服务"
-diagrams:"组件图/核心流程时序图/类图/模块引用关系图"
-contracts:"payment_callback/order_service/inventory_service 三个 API 契约"
-patterns:"select_for_update 悲观锁 / transaction.atomic 事务边界"
manual:
-quickstart:"Python 3.11, Django 4.2, Redis 7"
-adr:"ADR-001: 用 Redis SETNX 做去重而不是数据库唯一索引"
-faq:"Q: 为什么 refund 不用乐观锁? A: ADR-001 说明了双通知场景乐观锁漏检的问题"全局审视:知识库在整个改造路径中的位置
回顾这一篇在整个屎山改造系列中的位置和这篇内部的分析路径:
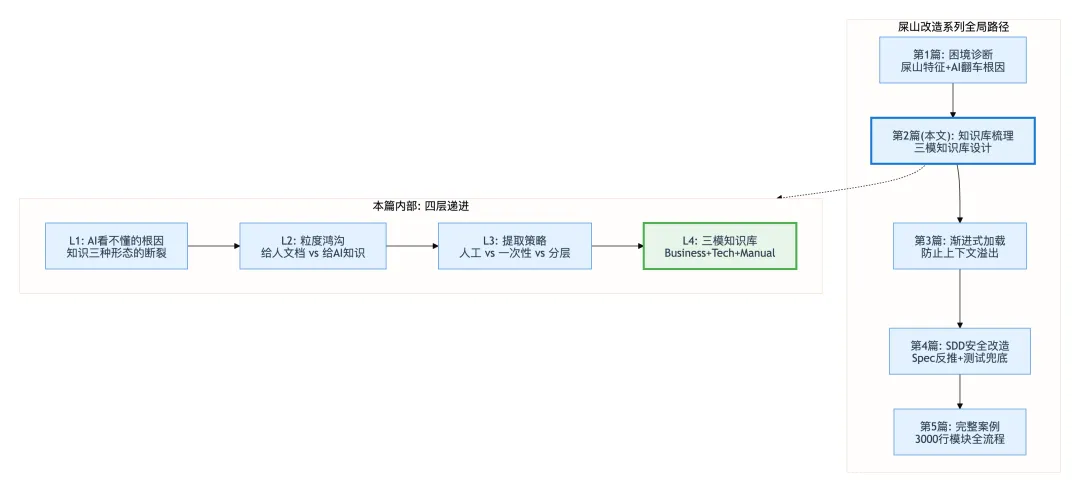
核心洞察:知识库梳理的本质不是"写文档"——是把散布在代码、注释、git log、前同事记忆中的隐性约束,翻译为 AI 可精确消费的结构化知识。这个翻译的精度决定了后续所有 AI 操作的安全上限。如果知识库里漏掉了一条"库存回补仅支付宝"的约束,后面的 Spec 反推、测试补全、渐进替换全部会在这个缺口上出问题——不是后面的环节做得不好,是前面的输入就不完整。
在系列中的位置:知识库梳理是破局三支柱的第一根——没有它,渐进式加载没有内容可加载,SDD 安全改造没有约束来源。它是整个改造链条的质量上限。
延伸思考
个人判断:知识库最大的敌人不是技术难度,是维护意愿
知识库梳理的技术门槛不高——分层渐进提取的方法论不难掌握。真正让知识库失效的不是"不知道怎么建",而是"建完之后不维护"。
知识库的腐化速度取决于两个因素:代码变更频率和团队的维护习惯。一个每两周有 3 次变更的模块,如果每次变更不在知识库中同步 Delta,两个月后知识库的准确度可能降到 60%。AI 基于 60% 准确度的知识库工作,它的推断错误率会比没有知识库时更高——因为它在"相信"一份不完全正确的知识。
我的判断是:知识库的价值随时间推移呈倒 U 型曲线。建库初期价值快速上升,峰值在维护最好的那段时间,然后随腐化开始下降。关键不是把曲线推得更高,而是让峰值持续更久。这就需要在 CI 管线中加知识库同步检查——Spec/Delta 变更时触发对应知识库模块的更新提醒。
替代路径的审视
| 只用代码注释替代知识库 | ||
| 用 RAG 向量检索替代分层加载 | ||
| 不做知识库,直接让 AI 追问 |
选择三模知识库方案的核心判断是:屎山场景下需要的是确定性,不是概率性。RAG 检索的"80% 相关性"对于代码生成任务有 20% 的遗漏概率——这个概率在屎山上意味着"关键约束有 20% 的概率被 AI 当作需要优化的代码删除"。分层加载的确定性——每层经过人类验证——是这个方案的核心价值,不是性能更优,而是遗漏概率更低。
适用边界
三模知识库最适合的核心条件是:隐性约束密度高 + 文档空白 + 团队有至少一个对模块比较熟悉的开发者。如果没有人对模块有基本理解,知识库梳理的第一步(反向提取)就没法做——你无法验证 AI 提取出的约束是否正确。
不适用的场景:已经有完善文档的项目(知识库已经在文档里,不需要重建)、团队里没人对模块有基本理解且无法从前同事获取信息(只能靠纯逆向分析,这种情况下知识库的质量天花板很低)、快速废弃的模块(知识库的投入回报不成比例)。
一个实操建议:不要对全项目做知识库梳理。挑 2-3 个最核心、变更最频繁、出事影响最大的模块先做。做完这几个模块后你会得到两个东西:知识库模板(可以直接复制到其他模块使用)和团队对知识库维护的习惯。这两样东西到位之后,再考虑推广到更多模块。
