 夜雨聆风
夜雨聆风一切都跑得挺好,直到你的模型服务商某天凌晨发生了抖动。请求超时,Agent 卡住,用户收到了一条没有回复的消息。你早上醒来才发现。
这不是概率问题,是结构问题。只要你的出海 AI 智能体只绑定一个模型提供商,这就是迟早会遇到的事。
OpenClaw(开源 AI 多平台智能体框架)和 OpenRouter(统一模型路由层)的组合,就是为了解决这个问题。今天这篇文章是实战配置手记,六个月来我在出海 Agent 项目里一直在用这个方案。
OpenClaw 和 OpenRouter 分别是什么
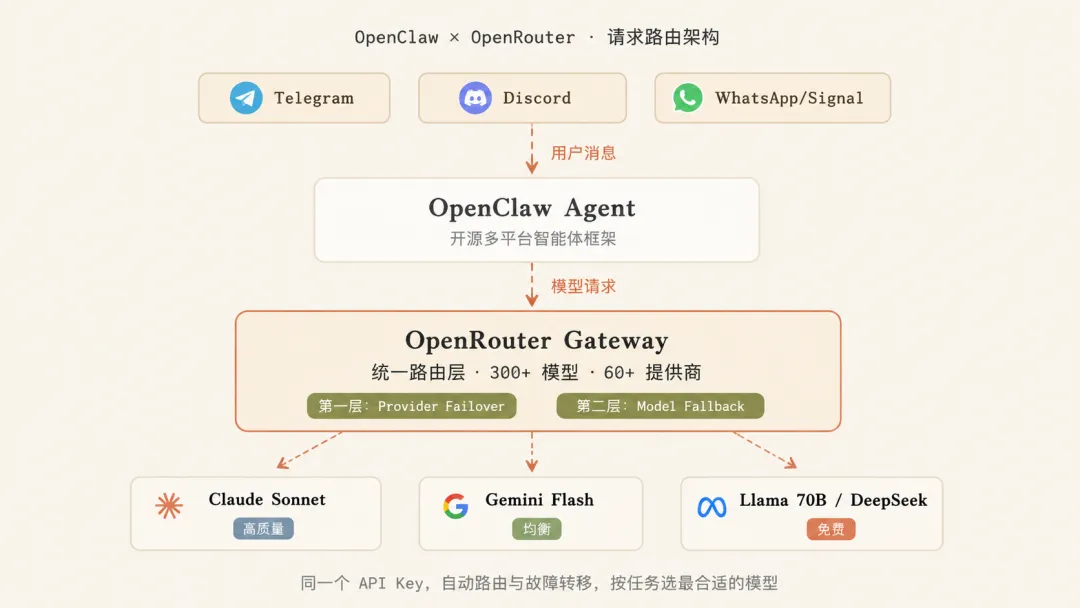
OpenClaw 是一个开源 AI 智能体框架,让你用同一套代码把 Agent 跑在 Telegram、Discord、Slack、Signal、iMessage、WhatsApp 上。它本身不带模型,需要你指定一个模型提供商。
据 36 氪今年初的报道,OpenClaw 一度成为 OpenRouter 平台上 token 消耗量最大的应用。一个配置合理的 OpenClaw Agent,每天可能发起数百次到上千次模型调用,每次还要携带完整上下文,单个用户的 token 消耗是普通聊天用户的几十到上百倍。
OpenRouter 是一个统一 API 层,把 300+ 模型、60+ 提供商接在一个端点后面。一个 API Key,统一账单,请求自动故障转移。
两者配合之后:OpenClaw 不再只绑一个模型,而是绑了整个模型市场。
接入后你真正得到的是什么
这是我认为最值得说清楚的一点,不只是"换个 API 地址"那么简单。
第一:自动故障转移,不再人工守夜。
OpenRouter 的故障转移分两层。第一层是同一个模型换提供商,例如 Claude Sonnet 在某个节点挂了,自动切到另一个节点。第二层是整个模型挂了,切到你预设的备选模型。两层叠加,你的请求有更高概率被成功处理,Agent 不会因为单点抖动而卡住。
第二:多模型分工,降低成本。
并非每一步 Agent 动作都需要最贵的模型。研究类任务用 Claude Opus,快速摘要用 Llama 70B,状态心跳用免费模型,把任务和模型匹配起来,成本差距可以很大。OpenClaw 支持按 Agent 设置不同的主模型,OpenRouter 的 Auto Router 还能按任务复杂度动态匹配模型(不保证每次最便宜,复杂任务会自动选质量更高的模型,按需启用)。
第三:扩展能力一步到位。
图像生成、视频生成、TTS 语音合成、STT 语音识别,均可通过 OpenRouter 统一接入(支持情况取决于具体模型),在 OpenClaw 配置里统一管理,不需要再对接多个服务商的鉴权系统。
五步接入配置
第一步:拿到 OpenRouter API Key
在 openrouter.ai/keys 注册并创建 Key。充值按使用量计费,平台费 5.5%,无订阅费,不用模型就不扣钱。
第二步:一条命令完成接入
openclaw onboard \--auth-choice apiKey \--token-provider openrouter \--token"$OPENROUTER_API_KEY"
命令执行后,凭证写入 ~/.openclaw/openclaw.json,默认模型设为 openrouter/auto。这就接通了。
如果你跑在 VPS 上, Key 必须写进 env 块,而不是 shell profile:
{"env":{"OPENROUTER_API_KEY":"sk-or-你的key"}}
服务进程的 shell 环境和你交互式 shell 不同,profile 里的变量它读不到。
第三步:确认模型已加载
openclaw models list看到模型列表说明连通了。
第四步:按任务分配模型(可选,推荐做)
不同 Agent 用不同模型,在配置里加 overrides 块:
{"agents":{"overrides":{"researcher":{"model":{"primary":"openrouter/~anthropic/claude-sonnet-latest"}},"responder":{"model":{"primary":"openrouter/meta-llama/llama-3.3-70b-instruct:free"}}}}}
模型名格式是 openrouter/<作者>/<模型名>,加 ~ 前缀自动追最新版,不加就锁定具体版本号。
第五步:设置故障备选链(推荐加)
主模型挂了切备选,在 model 块加 fallbacks:
{"agents":{"defaults":{"model":{"primary":"openrouter/~anthropic/claude-sonnet-latest","fallbacks":["openrouter/~google/gemini-flash-latest","openrouter/deepseek/deepseek-chat"]}}}}
三个模型依次兜底,提供商层面的故障转移是自动的,这里配的是模型层面的备选。
注意:OpenClaw 和 OpenRouter 均在持续迭代,CLI 参数和配置字段随版本可能有差异,建议以各自官方文档为准。
三个最常见的报错,先替你排好
env 块,不要只放 shell profile | ||
openrouter/openrouter/auto,两个 openrouter 不是手误 | ||
openrouter.ai |
出海场景下的模型选型建议
这是我自己目前在用的分配逻辑,仅供参考:
Kimi K2.5 值得特别提一下。36氪的数据显示,它在 OpenRouter 平台上的 OpenClaw 调用量曾经周增长 261%,在价格和 Agent 能力的平衡上确实有竞争力,出海场景的中英双语处理也够用。
最后说一句
多模型路由层不是为了让你"用更多模型"而存在的。它真正解决的问题是:让你的出海 AI 智能体不再依赖任何一个单点。
当你的 Agent 在帮海外用户解决问题的时候,模型层面的稳定性不应该是你需要去操心的事。OpenClaw × OpenRouter 这套组合,是目前我见过在出海 Agent 场景里最务实的配置方案之一。
适合接入的阶段:Agent 已上线且日均调用量超过 500 次,或者你正在计划把 Agent 从一个平台扩展到多个平台。如果你还在本地调试阶段,先把核心逻辑跑通,不用急着搞路由层。
配置和测试是一次性的,但它带来的稳定性是每天都在省心的。
今天就聊到这,有问题欢迎留言交流,我们下回见。
如果觉得文章对你有帮助,记得点。赞。转。发。收。藏喔!
关注也船长AI,每周更新 AI 工具实测和行业判断。
