 夜雨聆风
夜雨聆风
有些 OOM 很冤。
图片压过了,缓存也收紧了,堆上限看起来还有空间,应用跑久以后却还是越来越卡,最后被系统干掉。
团队通常会问:“到底哪个对象没释放?”
但更应该问的是——谁本来只该活 10 秒,却被一个能活 10 小时的对象抱住了?
这才是 Android 内存泄漏最常见的根。
它不是简单的“忘了置空”,而是生命周期所有权写反了。
先把原理说透: GC 只看“还能不能摸到”
Java/Kotlin 有垃圾回收,不代表不会泄漏。
GC 判断一个对象能不能回收,不看“业务已经不用了”,只看从 GC Root 出发,是否还能沿着引用链找到它。
常见的 GC Root 包括线程、静态字段、 JNI 全局引用,以及仍在执行的方法栈。
所以,一条典型泄漏链经常长这样:
GC Root → 单例 → Listener → Activity → 整棵 View 树
Activity 明明执行了 onDestroy(),只要这条链还在,它就死不了。更麻烦的是,一棵 View 树后面还可能挂着 Bitmap 、 Drawable 、 Adapter 和业务数据。
泄漏的危险,不在于一个对象有多大,而在于它身后拖着多少东西。
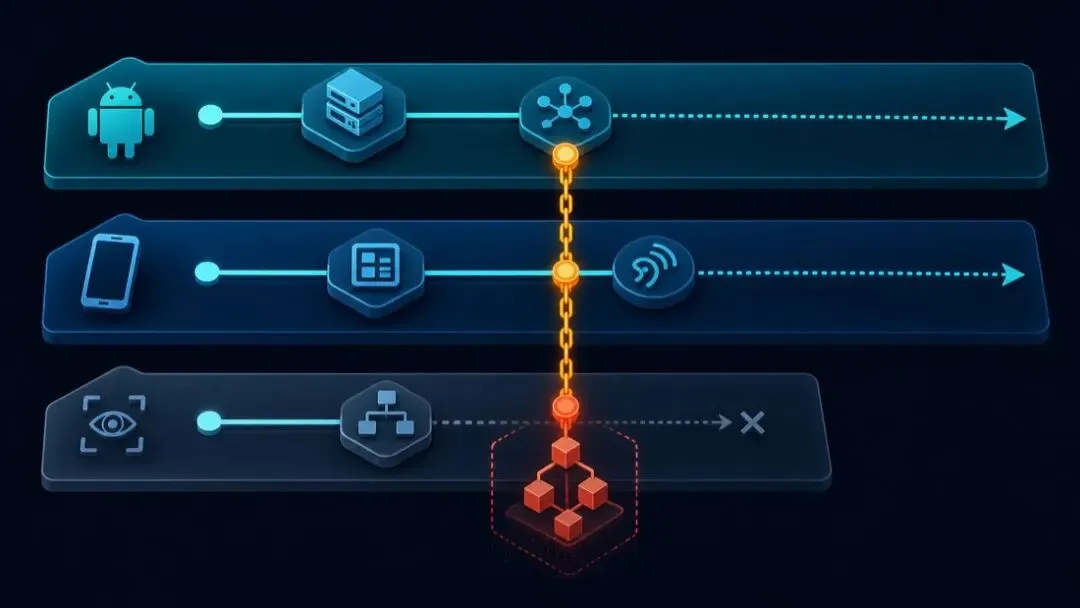
还要分清两个概念:
两者都可能导致 OOM ,但修法完全不同。前者要限容量,后者要断引用链。
这 6 种写法, Code Review 里最容易漏
1. 单例把 Activity 当成普通 Context 保存
这段代码看着只是“方便调用”:
单例跟进程活得一样久, Activity 只该活到页面关闭。
一旦赋值,进程级对象就接管了页面级对象的生命周期。旋转屏幕、反复进入页面后,旧 Activity 会一层层留下来。
如果确实只需要系统能力,保存 applicationContext。如果需要操作页面,把动作交给短生命周期回调,并在退出时解除绑定。
2. Fragment 销毁 View 后,还握着 ViewBinding
Fragment 的生命周期和它的 View 不是一回事。
Fragment 可能被保留在返回栈里,但 onDestroyView() 已经销毁了旧 View 。此时 Binding 如果仍在,就会把整棵旧 View 树留下。
这里的 null 不是仪式感。它是在告诉引用关系:Fragment 可以继续活,旧 View 到此为止。
3. 注册了 Listener 、 Observer ,却没有对称注销
地图、定位、传感器、播放器、 EventBus 、自研消息中心,都很容易出现:
真正持有页面的不是 manager 这个变量,而是 Manager 内部的监听器集合。
修复时别只盯着页面代码。要检查注册方是否支持 LifecycleOwner、是否能自动解绑,以及异常退出路径有没有漏掉注销。
4. 延迟消息执行完了,页面早没了
匿名 Runnable、Handler 消息和定时任务,通常会捕获外部 Activity 、 Fragment 或 Binding 。
如果延迟 60 秒执行,页面第 5 秒就退出,那么剩下 55 秒里,消息队列都可能替你保管旧页面。
更稳妥的做法,是把任务放进 lifecycleScope 或 viewLifecycleOwner.lifecycleScope,让取消跟生命周期绑定;必须用 Handler 时,在退出阶段移除回调和消息。
5. 协程没有泄漏,捕获的页面却泄漏了
GlobalScope、自建但不取消的 CoroutineScope,以及长时间挂起的任务,都可能把 Lambda 捕获的页面对象留住。
协程本身不是原罪。问题在于任务的生命周期比页面长,还捕获了页面。
页面 UI 任务优先使用 lifecycleScope; Fragment 的 View 更新优先绑定 viewLifecycleOwner;流式收集则用 repeatOnLifecycle 控制启动与取消。
6. WebView 、 Native 和线程,藏在 Java 堆之外
WebView 往往同时牵涉 Java 对象、 Chromium 资源和 Native 内存。仅仅从父容器移除还不够,通常还要停止加载、解除回调、移除子 View ,并在明确不用时销毁。
JNI 全局引用忘记释放、 Native malloc 没有对应 free、线程不断创建不退出,也会让进程内存持续上涨。
这类问题最容易误导排查: Java Heap 看着还行,进程的 PSS 却一直爬。
只看 Java 堆,等于只看了内存问题的一半。
LeakCanary :开发阶段抓引用链,快而准
LeakCanary 的思路非常直接:
它最强的地方,是把一句“Activity 没释放”,翻译成一条开发者能修改的路径。
比如:
Thread → Singleton → callback → MainActivity
不用在几百万个对象里手工找针。
LeakCanary 的优点很明确:
它的短板也同样明确:
一句话:LeakCanary 是开发现场的显微镜。
KOOM :线上监控更完整,但工程成本更高
KOOM 的目标更接近线上治理。
它不仅关注 Java 泄漏,还覆盖 Native 泄漏和线程泄漏。 Java OOM 监控会轮询堆、线程数和文件描述符等状态,连续达到阈值后触发采集。
为了减少传统 Heap Dump 对主进程的冻结, KOOM 使用 fork 和 Copy-on-Write :主进程短暂挂起并 fork 子进程,随后恢复运行,让子进程完成 Heap Dump ;分析过程还能放到独立服务中。
官方文档给出的设计目标很激进:把传统 Dump 可能造成的长时间卡顿,压缩到很短的冻结窗口。不过,完整 Dump 与分析仍然需要 CPU 、内存和磁盘,所以它要求抽样、远程开关和后台时机控制。
KOOM 的优势:
它的代价:
一句话:KOOM 是线上车队的内存雷达。

不是二选一:最好把它们放在不同防线
如果只是问“哪个工具更强”,答案很容易失真。
真正应该问的是:问题出现在哪一层?
更实用的组合是:
工具只能帮你看见引用链。
真正减少泄漏的,是团队对“谁创建、谁持有、谁释放”的统一约定。
排查内存泄漏,我只按这个顺序
第一步,先确认是不是泄漏。
重复进入并退出目标页面,主动触发 GC ,观察同类对象数量是否持续阶梯式上涨。如果只是单次峰值后回落,先别急着下结论。
第二步,沿引用链找第一个不该存在的强引用。
别从泄漏对象往后猜。直接从 GC Root 往下看:静态字段、线程、 Listener 集合、消息队列,谁拥有这条链?
第三步,修所有权,不是乱加弱引用。
弱引用只能缓解持有,不能替代正确生命周期。如果业务必须依赖这个对象,弱引用被回收后还可能制造另一类空状态问题。
第四步,做重复场景回归。
旋转屏幕、前后台切换、返回栈、配置变更、网络超时、异常退出、低内存重建,一个都别少。
第五步,再看进程全景。
Java Heap 降了,不代表 Native 、 Graphics 、线程栈也降了。最终要对照 PSS 和各内存分项,确认问题真的消失。
内存泄漏最麻烦的地方,是它很少当场爆炸。
它只是让一个已经结束的页面继续活着,再让第二个、第三个页面陪它一起留下。
直到某次普通图片解码,成了压垮进程的最后一根稻草。
OOM 是结果。错误的生命周期所有权,才是起点。

你们项目里最顽固的一次泄漏,最后藏在 Listener 、协程、 WebView ,还是 Native 代码里?
