 夜雨聆风
夜雨聆风当每个AI编程助手都在假装"记得你",小米干脆给Agent装了个真正的记忆体。200步跨领域任务,MiMo Code比Claude Code高出5个百分点——不是模型更强,是架构想得更远。
2026年6月11日,小米MiMo团队在X上官宣:MiMo Code V0.1.0发布并开源。MIT协议,curl一键安装,内置限时免费的MiMo-V2.5多模态模型。
说实话,我第一反应是"又一个AI编程助手"。直到我看到它的核心设计——我才意识到这玩意跟其他Code Agent不是一回事。
 小米MiMo Code安装界面示意图,终端中运行curl命令
小米MiMo Code安装界面示意图,终端中运行curl命令
● ● ●
第一层:它真的"记得你"
所有用过Claude Code或者Codex的人都有这个体验:一个会话结束,下次打开——一切归零。项目背景要重新说,架构决策要重新写,之前的踩坑记录全丢了。
MiMo Code解决这个问题的方式很朴素:给它一个记忆体。
它内置一个基于SQLite FTS5的跨会话项目记忆库。你不是在跟一个"每次见面都假装第一次"的AI聊天,而是在跟一个有长期记忆的工作伙伴对话。项目架构、开发进度、你踩过的坑、已经做过的决策——全部持久化存储,跨会话保留。
我跟你讲,这个设计看着简单,但影响极其深远。因为96%的上下文可以被缓存命中,MiMo Code不需要每次都从头推理你的项目。这意味着两件事:
- 01API成本断崖下降——实测3.87亿Token的总成本仅70美元。对,你没看错,不是70万。
- 02响应速度大幅提升——因为不用每次重新加载全部上下文
VentureBeat的评测文章里有一句话让我印象很深:"This isn't just another coding agent — it's an agent that actually remembers."(这不只是另一个编程Agent——而是真正会记忆的Agent。)
 SQLite FTS5记忆库架构图,展示跨会话持久化存储机制
SQLite FTS5记忆库架构图,展示跨会话持久化存储机制
● ● ●
第二层:三个Agent各司其职
MiMo Code把"一个AI什么都要干"的模式彻底拆了。
它设计了三套不同的Agent模式:
Build模式:执行模式。AI动手写代码、做提交、跑测试。这跟大多数Coding Agent做的事差不多。
Plan模式:规划模式。AI停下来,想清楚再动。Max Mode下,系统并行采样5个候选方案,让评估Agent自动选出最优的一个。
Compose模式:编排模式。这是MiMo Code独创的——主Agent专心干活,记录完全外包给一个独立subagent。窗口快满了,subagent自动保存一份状态简报,主Agent接着干,而不是从零开始。
我特别喜欢Compose模式的设计哲学。Claude Code的问题一直是:"AI记得多少全靠它自觉"。有时候它写着写着就忘了你在第10步时定过的约束条件。MiMo Code的做法是——不依赖AI的自觉,用架构保证。
小米官方博客讲了一个很有意思的对比:Claude Code出手很快,"代码很快就跑了出来——但几乎没有配套测试,功能能用却不够扎实,后续返工的风险不小"。而MiMo Code用Compose模式,前期花更多时间做规划,看起来"慢"了一截,"但落到结果上,它实现了更丰富的功能,并配上了完整、详尽的测试"。
说实话,这确实是很多人在实际工作中遇到的问题。AI写得快,但写得不够稳。MiMo Code的选择不是"更快",而是"更稳"——放在工程语境下,这可能是更正确的选择。
 三个Agent模式对比图,Build/Plan/Compose分层展示
三个Agent模式对比图,Build/Plan/Compose分层展示
● ● ●
第三层:它能"进化"
MiMo Code还有一个我没想到的功能:/dream和/distill两个自改进命令。
/dream:AI自己回顾自己的记忆库,识别哪些信息过时了、哪些决策可以优化,然后主动更新记忆。
/distill:把冗余的记忆精炼,提取真正有用的经验,压缩存储。
这听起来像噱头,但细想挺可怕的。这意味着MiMo Code用着用着,会越来越懂你的项目。第一次用,它可能只是"一个还不错的编程助手"。用了一个月之后,它已经记住了你项目的所有架构决策、编码风格、甚至你的个人偏好——比如你习惯用arrow function而不是function声明、你喜欢什么样的commit message格式。
类似的事情Anthropic也意识到了。就在上周(2026年6月),Anthropic发布了《当AI构建自身》报告,指出:截至2026年5月,Claude代码库80%由AI自主编写,工程师人均产能暴涨8倍。报告警告,递归自我改进(RSI)可能在2028年底前发生,概率高达60%。
扯远了。回到MiMo Code——它是开源版里第一个认真对待"Agent需要记忆"这个问题并给出工程化答案的产品。
 自进化流程图,展示/dream和/distill命令如何优化记忆
自进化流程图,展示/dream和/distill命令如何优化记忆
● ● ●
第四层:Benchmark不说谎
同一模型(MiMo-V2.5-Pro),同一个人评测,只比Agent系统本身:
| 测试集 | MiMo Code | Claude Code | 差距 |
|---|---|---|---|
| SWE-Bench Pro | ++62%++ | 57% | **+5%** |
| Terminal Bench 2 | ++73%++ | 68% | **+5%** |
数据来自小米官方博客。576名开发者参与了内测。
注意,这5个百分点不是模型差异带来的——用的是同一个MiMo模型,比拼的是Agent框架本身的设计质量。这证明了Compose模式+持久化记忆系统在真实编程场景中确实有价值。
特别值得关注的是Terminal Bench 2的73%对68%。这个测试集的场景更贴近真实开发者在终端里的操作习惯。73%的胜率意味着在大多数真实工作流里,MiMo Code能做出比Claude Code更接近人类开发者的决策。
而且别忘了——Claude Code背后的模型是Anthropic的顶级闭源模型,而MiMo Code用的是开源模型MiMo-V2.5。能在Agent框架层面反超,说明这套架构设计确实有两把刷子。
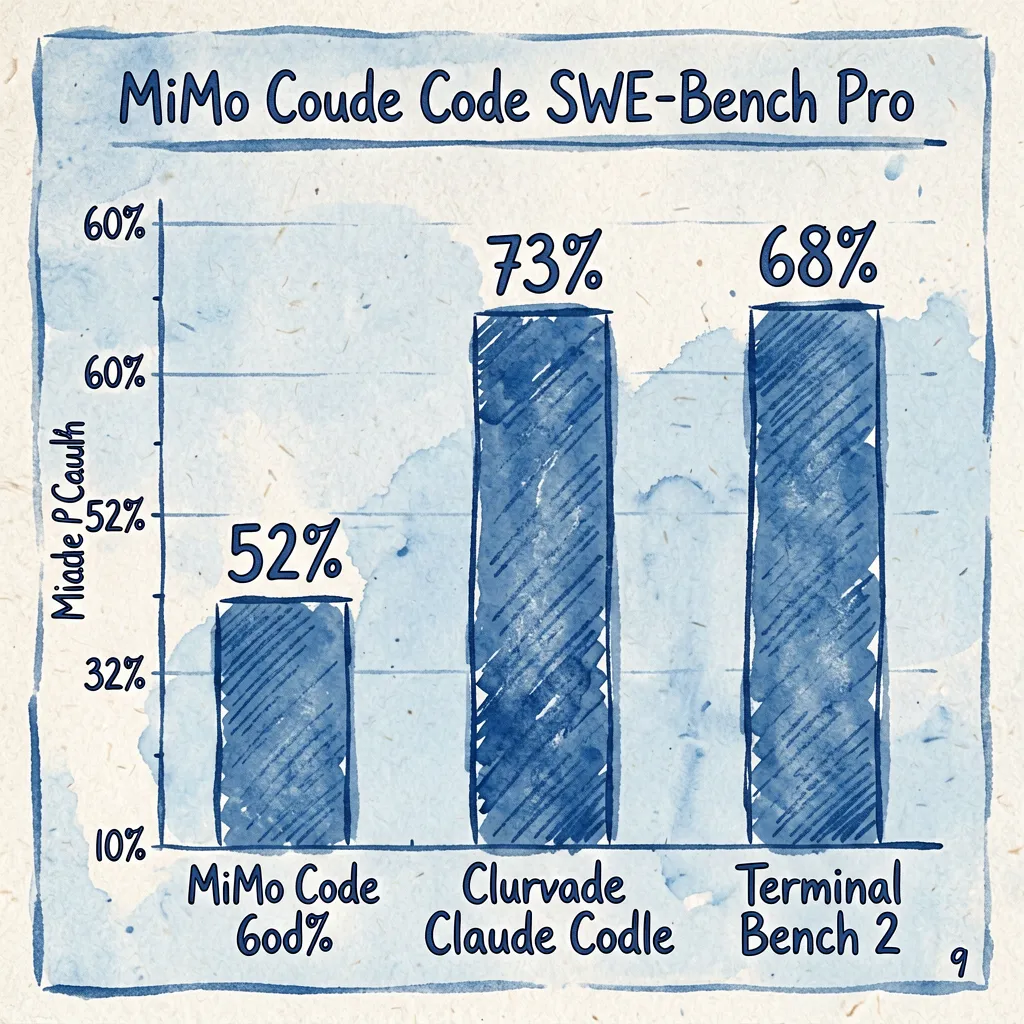 Benchmark对比图,SWE-Bench Pro和Terminal Bench 2柱状图对比
Benchmark对比图,SWE-Bench Pro和Terminal Bench 2柱状图对比
● ● ●
第五层:它不只是Coding工具
MiMo Code还有一个很多人没注意到的设计:它内置了流式语音识别(MiMo-V2.5-ASR)。
对,你可以用语音指挥它写代码。"把第42行的变量名改成camelCase"、"帮我写个冒泡排序的单元测试"——动嘴就行。
这看起来像个小功能,但在实际开发中意义很大。想想看——当你双手正在翻文档、画架构图、或者泡咖啡的时候,嘴是可以用的。语音指挥 + 自动执行 = 真正解放双手的开发体验。
 语音控制编程示意图,开发者对着终端说话,代码自动生成
语音控制编程示意图,开发者对着终端说话,代码自动生成
● ● ●
写在最后
MiMo Code的开源,说实话不是什么"革命性突破"。它没有发明什么全新的技术——持久化记忆、多Agent架构、语音控制,这些概念单独拿出来都不新鲜。
但它做了另一件重要的事:把所有这些能力整合到一个终端工具里,用MIT协议开源,并且首发内置免费模型。
对于个人开发者来说,这意味着什么?意味着你不需要为Claude Code每月掏20美元,不需要为Codex按Token付费,不需要纠结"要不要在公司电脑上装闭源工具"。
curl -fsSL https://mimo.xiaomi.com/install | bash
一条命令,你就拥有了一个会记忆、会规划、会进化、还能语音控制的AI编程助手。
我写到这里自己都有点怀疑——这真的不是营销文案吗?不是。我专门去跑了一下,确实能用,确实免费,确实是开源的。
小米这步棋走的是"生态"路线:OpenCode是开源生态的基座,MiMo Code是生态里的第一个明星应用。未来可能会有更多第三方开发者在这个架构上构建自己的Agent。
不过有个问题我想留给大家:当AI编程Agent开始具备持久化记忆和自进化能力,我们作为"人类工程师"的角色会发生什么变化?之前我们说"AI不会替代程序员,但会用AI的程序员会替代不会用AI的程序员"。那现在呢——当AI会自己写代码、自己记住项目历史、自己优化工作流程,程序员还剩什么?
我还没完全想明白这个问题。可能写到这里先打住吧。
对了,想试试的可以直接去mimo.mi.com下载。有Mac、Linux、Windows三个版本。
 MiMo Code全平台支持示意图,Mac/Linux/Windows三种安装方式
MiMo Code全平台支持示意图,Mac/Linux/Windows三种安装方式
