 夜雨聆风
夜雨聆风你在搜索框里输入“适合夏天的清爽饮料”,系统为什么能找到“柠檬气泡水”“冰美式”“无糖茶”?
你上传一张鞋子的照片,购物软件为什么能找出一堆相似款?
你在视频库里搜“一个人在会议室里讲PPT”,系统为什么不用你输入文件名,也能把相关片段翻出来?
这些功能背后,都离不开一个听起来很数学、但其实很生活化的东西:
向量。
更准确一点,是 Embedding。
别急,一听到向量,不用立刻回忆高中数学课,也不用担心脑子里出现一堆坐标轴。
今天我们用尽可能容易理解的话讲清楚:AI 怎么把文字、图片、视频,变成可以比较远近的“意义坐标”。
一句话先放在前面:
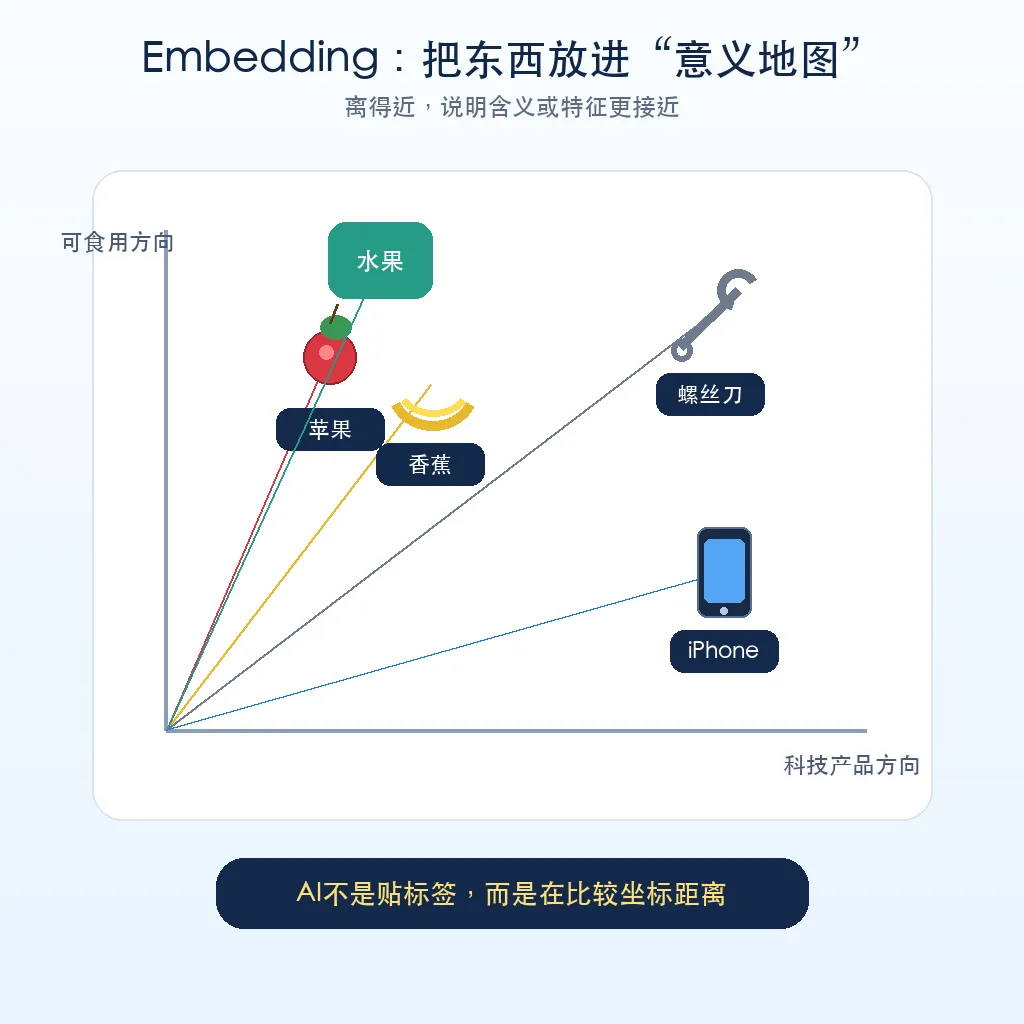
Embedding 就是把一个东西放进“意义地图”里,让 AI 能判断谁和谁更接近。
一、先从超市货架说起
想象你走进一家超市。
苹果通常不会摆在螺丝刀旁边。香蕉、橙子、梨,大概率会和苹果离得很近,因为它们都属于水果区。
矿泉水、气泡水、无糖茶,可能会放在饮料区。
手机壳、充电线、耳机,会在数码配件区。
人类逛超市时,靠常识理解这些东西的关系。
AI 没有真正逛过超市,也不会闻一闻苹果香不香。它要做的是另一件事:把每个词、每张图、每段视频,变成一串数字。
这串数字,就是向量。
如果“苹果”和“香蕉”的向量很接近,AI 就会认为它们语义相近。
如果“苹果”和“螺丝刀”的向量离得很远,AI 就会认为它们不太相关。
听起来像魔法,其实更像给每个东西分配一个位置。
苹果在水果区,香蕉也在水果区。螺丝刀在工具区。手机在数码区。
Embedding 做的事,就是把现实中的“分类和关系”,搬到一个数学空间里。
二、向量不是标签,而是坐标
很多人会把向量理解成标签。
比如苹果的标签是:水果、红色、甜、可吃。
这当然有帮助,但还不够。
因为现实世界里的关系,不是简单贴几个标签就能说清楚。
苹果既可以是水果,也可以是手机品牌;“冷”可以是温度低,也可以是态度冷淡;“轻”可以是重量轻,也可以是风格轻松。
Embedding 更像坐标,而不是标签。
你可以想象一张很大的地图。
地图上有很多方向:甜不甜、能不能吃、是不是科技产品、是不是颜色词、是不是抽象概念、常不常出现在厨房、常不常出现在办公室。
真实的模型不会只有两三个方向,而是可能有几百、几千个维度。
每个词、每张图、每段视频,都被放到这张高维地图上。
“苹果”和“香蕉”在“水果”“可吃”“甜味”“超市场景”这些方向上比较像,所以位置接近。
“苹果”和“iPhone”在某些上下文里也可能接近,因为“苹果”也可以指 Apple 公司。
这就解释了一个关键点:
向量不是死板标签,它会带着语境。
“我想吃苹果”和“苹果发布了新手机”,里面的“苹果”就不该被放到同一个小格子里。
三、AI怎么判断两个东西像不像?
当两个东西都变成向量以后,AI 就可以比较它们的距离。
距离近,说明含义更接近。
距离远,说明关系更弱。
这就是语义检索的基础。
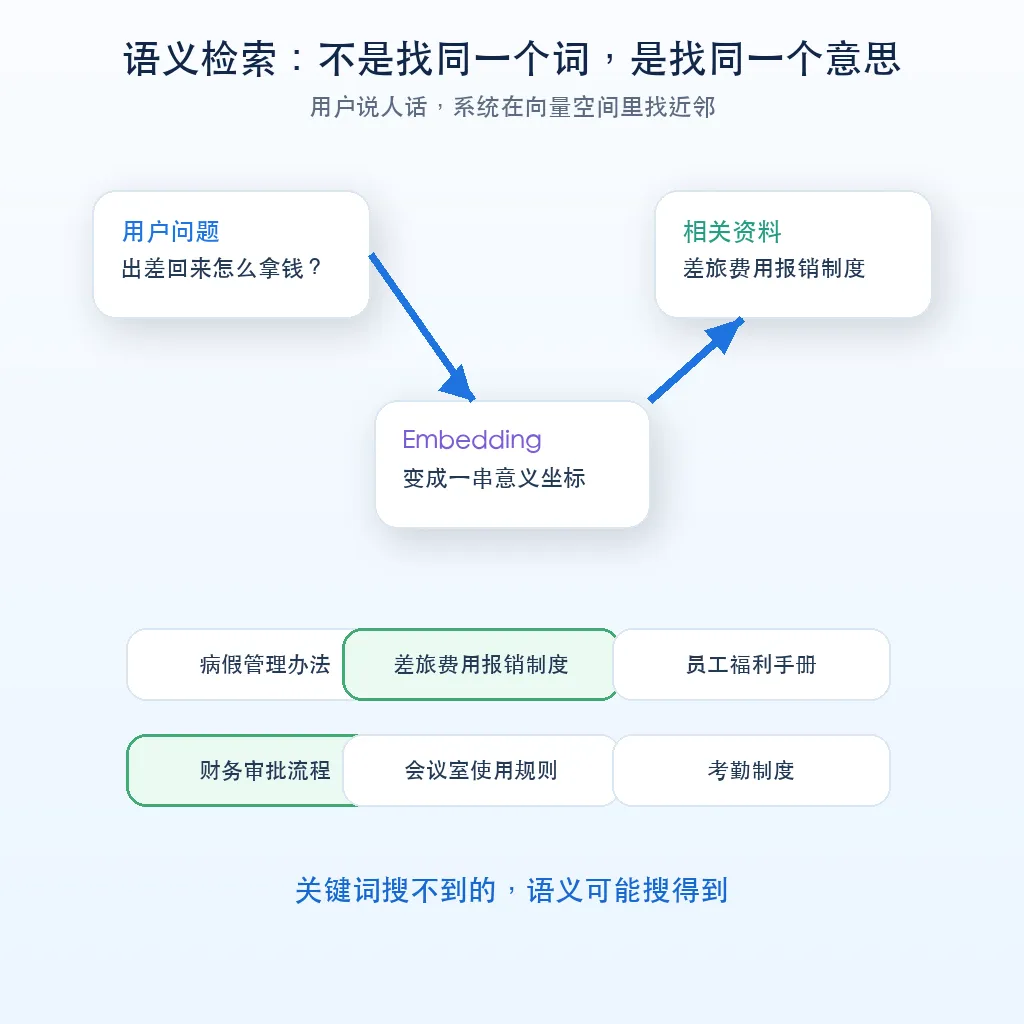
传统搜索更像查字典。你搜“报销流程”,它会找标题或正文里有没有“报销流程”这几个字。
语义检索更像问一个懂事的助理。你搜“出差回来怎么拿钱”,它也可能找到“差旅费用报销制度”。
因为在向量空间里,“出差回来怎么拿钱”和“差旅费用报销”离得很近。
这就是 Embedding 最有价值的地方:
它不是只看字面,而是看意思。
所以,哪怕你用的是口语、错别字、同义词,系统也可能找到正确内容。
当然,它也不是万能的。
如果资料本身写得乱,或者问题太含糊,向量也可能找错。语义相近不代表事实正确,就像超市导购把你带到饮料区,不代表每一瓶都适合你。
四、向量数据库:AI 的“意义仓库”
当我们把很多文本、图片、视频都变成向量以后,需要一个地方存起来。
这个地方就是向量数据库。
你可以把它想象成一个巨大的仓库。
普通仓库按货架编号找东西:A区3排5号。
向量数据库按“意义距离”找东西:谁和你的问题最接近,就先把谁拿出来。
比如公司有 10 万份文档。
用户问:“员工生病请假工资怎么算?”
系统先把这句话变成向量,再去向量数据库里找最近的资料。它可能找到《病假管理办法》《薪酬发放规则》《考勤制度》。
这些资料被取出来以后,再交给大模型组织语言,回答用户。
这就是很多企业知识库背后的基本流程。
它不是让大模型把所有资料都背下来,而是先用向量检索找到相关资料,再让模型基于资料回答。
这也是 RAG 的核心底座之一。
五、图片也能变成向量吗?
当然可以。
不只是文字能变成向量,图片也可以。
一张图片进入模型后,也会被压缩成一串数字。这个向量不再表示一句话的意思,而是表示图片里的视觉信息:颜色、形状、构图、物体、场景、风格。
所以你上传一张白色运动鞋,系统能找到相似鞋子。
你上传一张沙发照片,家居软件能找出相近款式。
你上传一张旅行照片,相册能找出“海边”“日落”“城市夜景”。
传统图片搜索很依赖文件名和人工标签。
图片叫 `IMG_2048.jpg`,人类看得懂内容,系统看文件名却一头雾水。
但如果图片能变成向量,系统就可以直接比较视觉相似度。
这就是相似图片检索的核心。
它不是在问“文件名像不像”,而是在问“画面里的东西像不像”。
六、文字能搜图片,图片也能搜文字
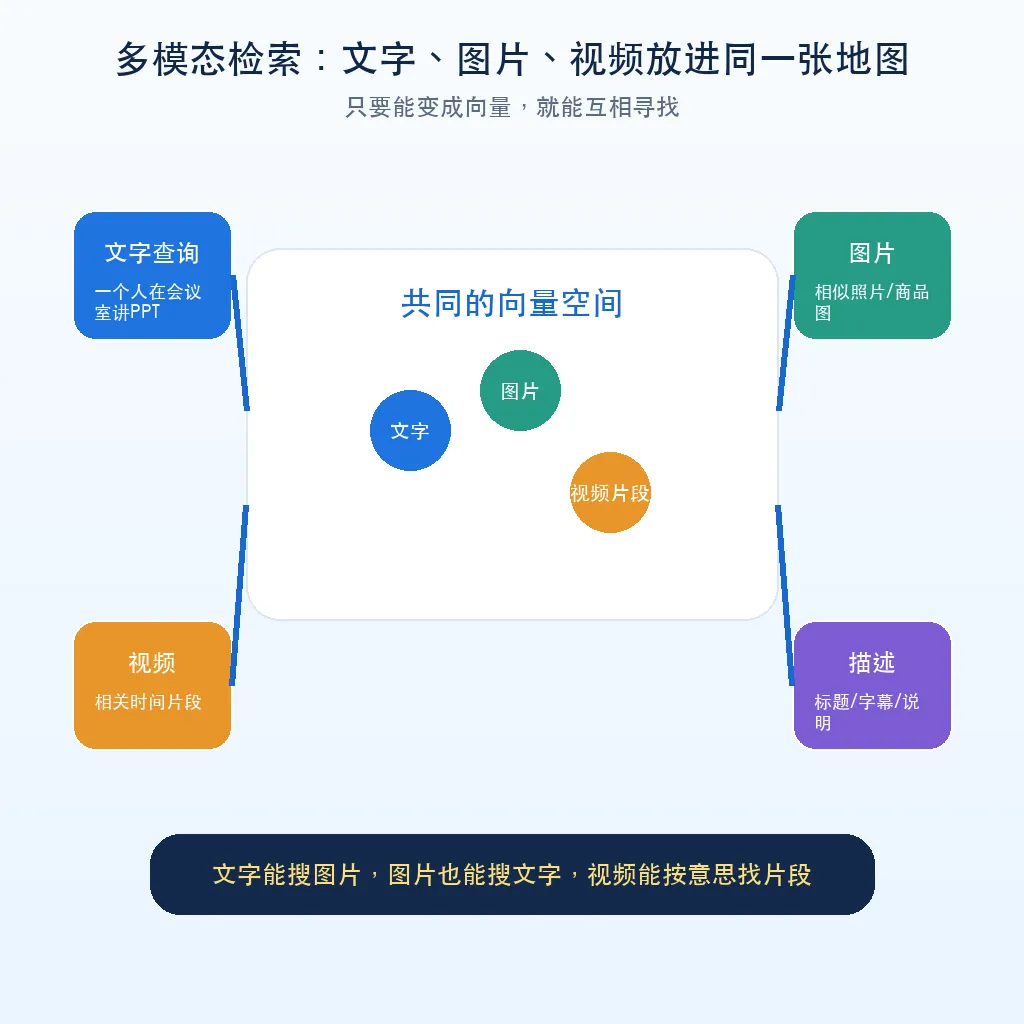
更有意思的是,多模态模型可以把文字和图片放到同一个意义空间里。
这句话很重要。
如果文字向量和图片向量能放在同一张地图上,你就可以用文字搜图片。
比如你输入:
“一个人在会议室里讲PPT”
系统可以找到符合这个意思的图片或视频帧。
反过来也可以。你上传一张图片,系统可以找到相关描述、商品标题、文档说明。
这就是多模态检索。
它背后的逻辑是:
文字说的是意思,图片展示的也是意思。只要两者能被映射到同一个空间,就能互相搜索。
就像你拿着一张椅子的照片去问店员:“有类似的吗?”
店员不需要你说出“北欧风浅灰布艺单人椅”这十几个字,也能看懂你大概想找什么。
多模态向量检索,就是让系统具备这种能力。
七、视频检索:把长视频切成很多“小抽屉”
视频比图片更复杂。
因为视频不是一张图,而是一连串画面,加上声音、字幕、动作和时间顺序。
所以视频检索通常不会把整段视频当成一个大黑盒。
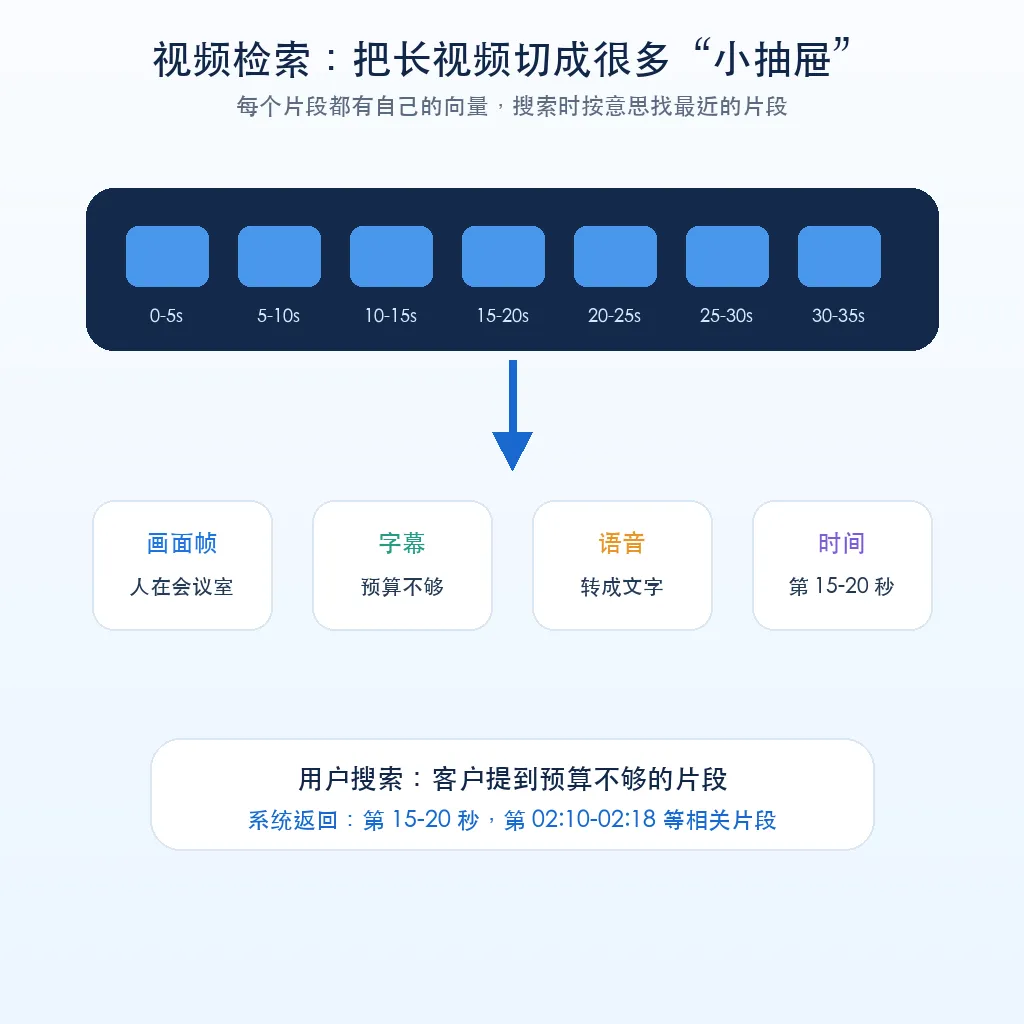
更常见的做法是:先把视频切成很多片段。
每个片段可能包含几秒钟的画面、对应的字幕、语音转文字、画面描述。然后系统把这些片段变成向量,存进数据库。
当你搜索“客户在会议里提到预算不够”时,系统就可以找到相关片段。
当你搜索“有人在厨房切水果”时,系统也可以找到对应画面。
这就是为什么未来的视频资料库会变得很不一样。
以前你找视频,要靠标题、标签、时间线。
以后你可能直接说:“找出老板上周提到增长目标的那一段。”
系统就能从一堆会议录像里把相关片段拎出来。
八、向量像不像,也要看“场景”
到这里,向量听起来很强。
但还是要泼一点冷静水。
相似,不等于正确。
“苹果”和“水果”相近,这很好理解。
但“苹果”和“苹果公司”什么时候相近,什么时候不相近,就要看上下文。
如果你在菜谱里说苹果,大概率是水果。
如果你在财报里说苹果,大概率是公司。
如果你在手机评测里说苹果,那就更明显了。
所以,向量检索通常还要配合其他东西:
关键词过滤、时间过滤、权限过滤、上下文判断、重排序模型。
通俗点说,向量负责把可能相关的东西先找出来,但最后还要有人把关。
它像一个眼力很好的仓库管理员,能迅速说:“你要的东西大概在这几排。”
但它不保证第一件拿出来的就一定是最终答案。
九、普通人理解向量,有什么用?
理解向量以后,你会更明白很多 AI 产品在做什么。
知识库问答,不是 AI 把所有文档都背了下来,而是在文档向量里找相近内容。
相似商品推荐,不是系统真的懂你的审美,而是图片和商品描述在向量空间里离得近。
视频搜索,不是系统记住了每一秒,而是把视频切片后存成可检索的向量。
AI 相册,不是它有情感记忆,而是它把照片里的场景、人物、物体、风格变成了可比较的数字。
这也能解释为什么有些推荐很准,有些又离谱。
因为“像不像”本来就是一件有弹性的事。
你想找“适合通勤的包”,系统可能理解成颜色低调、容量适中、外观简洁。
但你心里想的可能是“能装电脑、不压肩、下雨不怕湿”。
语义相近,是一个开始,不是最终答案。
写在最后
向量不是冰冷的数学符号。
在 AI 世界里,它更像一种“摆放万物的方法”。
文字、图片、视频、商品、文档、用户问题,都可以被放进一张巨大的意义地图。
离得近,说明它们更像。
离得远,说明关系更弱。
Embedding 就是把现实世界里的东西,变成这张地图上的坐标。
语义检索,是在地图上找离你问题最近的内容。
相似图片,是在地图上找视觉上最接近的图片。
视频检索,是把长视频切成很多片段,再在地图上找相关片段。
多模态检索,是让文字、图片、视频能在同一张地图上互相寻找。
所以,AI 怎么知道“苹果”和“水果”更接近?
不是因为它真的吃过苹果。
而是因为在它的意义地图里,苹果和水果站得很近,苹果和螺丝刀站得很远。
它不靠闻味道,不靠摸手感,也不靠逛超市。
它靠的是:把世界变成向量,再在向量之间比较距离。
听起来很技术。
但说到底,就是给万事万物安排座位。
坐得近的,关系近;坐得远的,关系远。
AI 的很多“理解能力”,就是从这张看不见的座位图开始的。
