 夜雨聆风
夜雨聆风昨天,Anthropic 发了一篇博客。
博客的标题叫《Steering Claude Code: Skills, hooks, rules, subagents, and more》。
它把 Claude Code 里所有的「自定义机制」全部拆开给你看。
看完你就知道一个事:
为啥同样是 Claude 模型,同样是写代码,有人用 Claude Code 跟玩玩具似的,有人用起来还是像在跟一个聪明但完全不听话的实习生说话。
差距在哪?
不在模型。
在 Harness。
Harness 是个啥?先讲个故事
我先讲个故事。
1880 年代,电力开始在美国普及。很多工厂主花大价钱买发电机、买电动机,装到自己的工厂里。
但装完之后呢?
很多人的工厂,效率并没有显著提升。
为啥?因为他们只是用电动机替代了蒸汽机。但整个工厂的布局、流程、生产方式,一行代码没动。
那些真正吃到电力红利的人,反而是最早想明白「电力到底是什么」的人。 他们重新设计了整个工厂。用电动机让生产线可以按工序灵活排布,让不同环节可以并行作业,让一个人能同时管理多台机器。
这些人才是赢家。
AI 时代,本质上一模一样。
大模型就是那个电动机。模型越强,「电动机」的马力越大。但如果你不重新设计「工厂的布局」。也就是你使用 AI 的方式。那再强的模型也是白搭。
这个「重新设计的使用方式」,就是 Harness。
Harness 这个词,直译是「马具」。给一匹马套上缰绳、笼头、马鞍、马蹬、嚼子,这样你才能真正驾驭一匹野马。
AI 也是一匹野马。能力爆表,但你骑不上去。Harness 就是让你骑上去的那整套装备。
Harness 跟模型,到底是什么关系
我先把一个最常见的误解打破:
「AI 牛不牛,主要看模型牛不牛。」
错。
在 2026 年的今天,模型之间的能力差距,正在快速缩小。Claude 、GPT、Gemini、包括各种国产模型,你用一个牛逼的问题去测试,答案的差距可能只有 5% 到 10%。但产出质量的差距,使用同样模型的人,差距可以是 10 倍、100 倍。
为啥?
因为模型提供的是「原始能力」。Harness 提供的是「把能力转化为产出的工程系统」。
我打个更直白的比方:
模型 = 大厨的厨艺(刀工、火候、味觉) Harness = 餐厅的运营系统(菜单设计、点餐流程、后厨动线、库存管理、上菜速度)
你就算请来米其林三星大厨,如果让他在混乱的苍蝇馆子里颠勺,他做出来的菜也一般。
但如果你给他一个高效的厨房、清晰的菜单、稳定的供应链,他就能发挥出 10 倍的威力。
AI 模型就是大厨,Harness 就是那套餐厅系统。
这就是为啥过去一年,硅谷最火的概念不是「更大的模型」,而是 Harness Engineering。LangChain 在 2025 年末率先把这个词喊出来,到 2026 年中,已经成了 AI Agent 圈所有人都在聊的事。
Claude Code 的 Harness 七件套
OK,理论说完了,上干货。
昨天 Anthropic 官方博客把 Claude Code 的 Harness 体系拆成了七件套。
但在我挨个讲这七件套之前,先记住一句话:
这七种方法,本质上是 7 种不同的「给 Claude 下指令的方式」。每种方法都在三个关键维度上做不同选择:
何时加载到上下文(session 启动 / 按需 / 事件触发) 会不会被压缩(永不压缩 / 压缩后重新注入 / 加载一次就消失) 占多少 token(一直占 / 按需占 / 不占)
理解这 3 个维度,你就理解了 7 种方法为什么存在、为什么不能互相替代。
七件套速查表
| 方法 | 加载时机 | 压缩行为 | 上下文成本 | 适用场景 |
|---|---|---|---|---|
| CLAUDE.md(根) | session 启动,整个会话都在 | 缓存读一次,压缩后重读 | 高。每行都占 token,无论是否相关 | 构建命令、目录结构、monorepo 布局、编码规范、团队约定 |
| CLAUDE.md(子目录) | 按需:读该子目录文件时 | 消失,直到下次再触达 | 低 | 子目录专属约定 |
| Rules | session 启动(无范围)/ 文件匹配时(路径范围) | 压缩后重新注入 | 中 | 特定约束(如「所有 API handler 必须用 Zod 校验」) |
| Skills | 启动时只加载 name+description;正文按需加载 | 被调用的 skill 在共享预算内重新注入 | 低 | 程序化工作流(部署 / 发布 / 审查 checklist) |
| Subagents | 启动时只加载 name+description+工具列表;正文通过 Agent tool 显式调用 | 隔离运行,只有最终消息回主上下文 | 低 | 隔离运行的并行或侧任务(深度搜索 / 日志分析 / 依赖审计) |
| Hooks | 事件触发(PreToolUse / PostToolUse / Stop / PreCompact) | 完全绕过压缩 | 低。配置在主上下文外 | 确定性自动化(跑 linter、发 Slack、阻止命令) |
| Output styles | session 启动,注入系统提示 | 永不压缩 | 中高。会覆盖默认系统提示 | 重大角色转变(代码助手 → 通用助手) |
| --append-system-prompt | session 启动,CLI 参数传入 | 永不压缩;只对当前这次调用有效 | 中。第一次请求后被缓存 | 语气、回复长度、格式偏好 |
这表格就是 Claude Code 自定义体系的「全图」。先扫一眼有个全局印象,下面我挨个讲。
1. CLAUDE.md:项目级「员工手册」
CLAUDE.md 是放在项目根目录的 markdown 文件,session 启动时自动加载。
你可以把它理解成:新员工入职时,公司给他的那本员工手册。
里面写啥?写项目里「Claude 始终要知道的」事实:构建命令、目录结构、monorepo 布局、编码规范、团队约定。
CLAUDE.md 有两种,加载方式完全不同:
根目录 CLAUDE.md(Always loaded)
session 启动就加载,整个会话都在 压缩后会自动重读 缺点:每一行都吃 token,无论当下任务是否相关
子目录 CLAUDE.md(On-demand)
只有 Claude 读到该子目录文件时才加载 离开该子目录后从上下文中消失 适合:只跟某个子目录相关的约定
Tip(来自官方博客):把 CLAUDE.md 控制在 200 行以内,给它一个 owner,像 review 代码一样 review 它的变更。把它当作 Claude 对你代码库的「概览」或「索引」,指向 Claude 在需要时可以深入查的其他文件。
在 monorepo 里,给每个团队的目录配一个子目录 CLAUDE.md,让团队只加载自己的约定。还可以用 claudeMdExcludes 跳过那些你从来不碰的团队的 CLAUDE.md。
企业级部署:对于全公司必须遵守的规范(安全策略、合规要求),可以通过 MDM 或配置管理把一个集中管理的 CLAUDE.md 部署到所有开发者的机器上,且用户不能通过本地设置排除它。
2. Rules:项目级「细则」
Rules 是放在 .claude/rules/ 目录下的 markdown 文件,给 Claude 具体的约束或约定。
Rules 分两种:
无范围(Unscoped)
session 启动就加载,压缩后会重新注入 跟根目录 CLAUDE.md 行为一致:一直占 token,哪怕当下任务不相关
路径范围(Path-scoped)
通过 frontmatter 里的 paths字段指定生效范围只有 Claude 读该路径下的文件时才加载 跟子目录 CLAUDE.md 类似,但更适合「跨切面」的约束
举个官方例子:
---
paths:
- "src/api/**"
- "**/*.handler.ts"
---
所有 API handler 必须用 Zod 在处理前校验输入。
这段规则只在 Claude 动 src/api/ 下的文件时才被加载。docs-only 的会话它根本不会出现,省 token。
Tip(来自官方博客):文件特定的约束(如「migrations 是 append-only」)最适合做成带 paths 范围的 rule。当这条指令涉及「跨切面」或「在多个(但不是全部)位置出现」的文件时,用路径范围的 rule 比用子目录 CLAUDE.md 更合适。
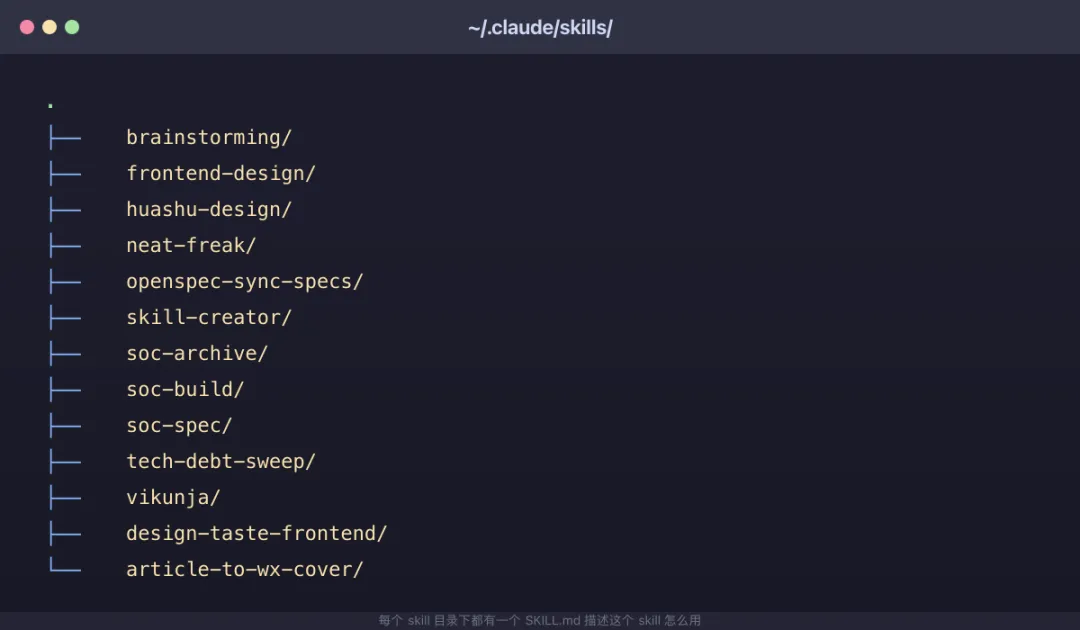
3. Skills:按需调用的「SOP 工具箱」
Skills 放在 .claude/skills/ 目录下,是「指令、脚本、资源」的文件夹。每个 skill 都有一个 SKILL.md 文件,包含 name、description 和正文。
加载机制很巧妙:
session 启动时,只加载 skill 的 name 和 description(不占太多 token) 当 skill 被真正调用时,正文才加载 调用方式:slash command(如 /code-review)或者由 Claude 根据任务自动匹配
这就让 Skills 既有「Claude 知道它存在」的能力,又不会在不用的时候占 token。
Compaction 行为:被调用的 skill 在压缩后会被重新注入,但所有被调用的 skill 共享一个总 token 预算。调用的 skill 多了,最老的会先被丢弃。
Tip(来自官方博客):程序化的指令(如部署工作流、发布 checklist、review 流程)应该放在 skill 里,而不是 CLAUDE.md。CLAUDE.md 是「Claude 应该一直记住的事实」;skill 是「执行某件事的剧本」。
Claude Code 自带了一些 skill(/code-review 就是内置的),你也可以自己写。
4. Subagents:隔离上下文的「AI 团队」
Subagents 放在 .claude/agents/ 目录下,是为特定侧任务定义的「隔离助手」。每个文件用 YAML frontmatter(name、description,可选 model 和工具访问)开头,正文会成为该 subagent 的系统提示。
和 Skill 的关键区别:
Skills 的 body 会被加载到主对话 Subagents 的 body 永远不会进入父对话 Subagents 在自己独立的、隔离的上下文窗口里跑 只有 subagent 的最终消息(往往是多个子任务的汇总结果)加上元数据回到主会话
这就让 Subagent 特别适合「不要让中间过程污染主上下文」的任务。
Subagent 还能嵌套(最多 5 层),而且 dynamic workflows 可以编排几十到几百个后台 agent 而不需要你指定每个 subagent 的架构细节。编排计划和中间结果存在脚本变量里,而不是存在 Claude 的上下文窗口里,这让规模可以扩大但指令保真度不丢失。
Tip(来自官方博客):这种隔离是「用 subagent 而不是 skill」的主要理由之一。
用 subagent:当一个侧任务(深度搜索、日志分析、依赖审计)会让主对话塞满你再也不会看回去的中间结果 用 skill:当你想让流程在主线程里跑,你可以看到并引导每一步
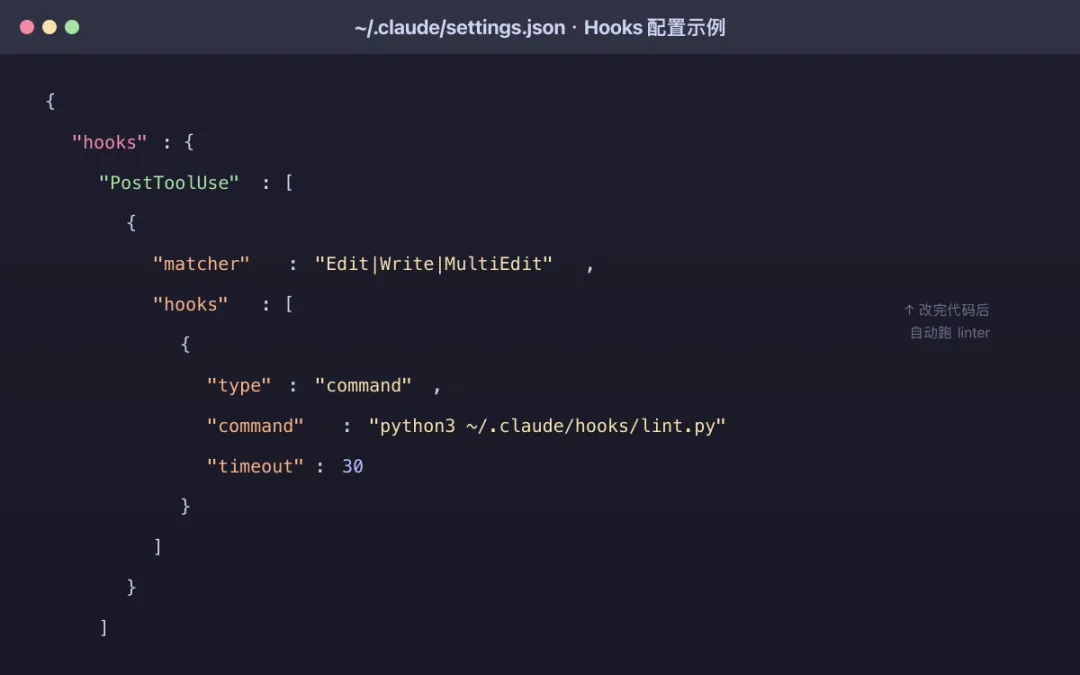
5. Hooks:确定性事件触发器
Hooks 是「用户定义的命令、HTTP 端点或 LLM 提示」,通过在 Claude 生命周期的特定事件(如文件编辑、工具调用、session 启动)触发,提供更确定性的 Claude 行为控制。
你在 settings.json、managed policy settings 或 skill/agent frontmatter 里注册 hooks。
有 5 种 hook 类型:command、HTTP、mcp_tool、prompt、agent。
前三种是确定性地执行的 后两种(prompt 和 agent)用 Claude 自己的判断来决定输出
Hooks 的上下文成本很低,因为配置或指令本身在主上下文窗口之外。harness 跑的是 handler(command、http、mcp_tool),或者用独立窗口跑 model 调用(prompt、agent),取决于 hook 类型。
有些 hook 的输出会回到主上下文。比如一个 blocking hook 的标准错误会留在上下文里,让 Claude 知道为什么调用被拒绝。
但大部分 hook 的输出不会回到主窗口。除非配置明确要求返回。比如你在 PreCompact 事件前把聊天记录备份到另一个文件,Claude 根本不会知道聊天记录备份到了哪个文件(因为 hook 输出没回到上下文)。
Tip(来自官方博客):用 hooks 做任何应该「确定地」发生的事:
编辑后跑 linter 完成后发 Slack 阻止特定命令在执行前
一个 PreToolUse hook 可以检查任何工具调用,以 exit code 2 退出就能直接拒绝它。
它们上下文成本低,因为它们是「harness 跑的代码」,而不是「加载到上下文的指令」。
6. Output styles:注入系统提示的「人格」
Output styles 放在 .claude/output-styles/ 目录下,把指令注入到系统提示里。
关键特性:
session 启动就加载 永不压缩 第一次请求后被缓存(所以上下文成本中等) 占用上下文窗口 会覆盖默认的输出样式(除非你在 frontmatter 里设 keep-coding-instructions: true)
这就让 Output styles 成为所有方法里「指令遵从权重最高」的一种,需要谨慎使用。
关键警告(来自官方博客):在 Claude Code 里自定义 output style 会移除告诉 Claude 它在帮用户做软件工程任务的指令,以及其他重要的默认指令:
如何限定变更范围 何时加或不加代码注释 怎么处理安全问题 像「声明完成前跑测试」这样的验证习惯
默认情况下,自定义 output style 会丢光这一切,Claude Code 会从「软件工程师助手」变成「通用助手」。
Tip(来自官方博客):在写自定义 output style 之前,先看看内置的样式。Proactive、Explanatory、Learning 已经覆盖了最常见的需求(自主模式、教学模式、协作编程),不用你自己维护样式文件。
7. Appending the system prompt:单次叠加
--append-system-prompt 是修改 output style 之外的另一种选择。
跟修改 output style 文件(可能产生大范围、意料之外的行为变化)不同,append flag 是叠加的(additive)。它不会修改 Claude 的角色,只是给它默认角色增加指令。
它也是调用时传入的,只对那一次调用有效,不会以文件形式在 session 之间持久化。
上下文成本可能更高:它会增加 input token(虽然 prompt caching 在第一次请求后会降低这个成本)。让 Claude 用更冗长或更长的风格也会增加 output token。
Tip(来自官方博客):append-system-prompt 适合添加特定的编码标准、输出格式或领域知识。注意用这个方法有「收益递减」效应。你给的指令越多,Claude 反而越不严格地遵循它们,特别是当指令之间有矛盾时。
5 个迁移规则:把指令放到正确的地方
如果你发现自己做了下面这些事,可能需要重新考虑指令的存放位置:
1.「每次 X,总要 Y」写在 CLAUDE.md
如果这个行为必须可靠发生(比如「每次编辑后跑 prettier」、「完成后发 Slack」),用 settings.json 里的 hook 代替。「让模型选择跑 formatter」和「formatter 自动跑」是两码事。
2.「绝对不要做这件事」写在 CLAUDE.md
当有「绝对不能发生」的事,指令是错的工具。Claude 多数时候会遵循指令,但在压力下、长会话、模糊情境,或者被 prompt injection 污染时,模型可能不遵循被提示的规则。真正的护栏需要确定性,执行机制是 hooks 和 permissions。一个 PreToolUse hook 可以检查调用并以 exit code 2 阻止它。
Managed settings 更进一步:它们由管理员部署,不能被用户的本地配置覆盖,是实施「确定性的、组织级护栏」的唯一方式。
3. 30 行的程序写在 CLAUDE.md
程序应该放在 skills 里。CLAUDE.md 是「Claude 应该一直记住的事实」(构建命令、monorepo 布局、团队约定);部署 runbook 或安全审查 checklist 应该放在 .claude/skills/,只有调用时才加载正文。
4. 不带 paths 的 API 专属规则
如果一条规则只对 src/api/** 适用,用 paths: 把它圈起来,让它不相关的会话里不进上下文。不带 paths 的 rule 跟把内容放在 CLAUDE.md 是一回事:一直加载、一直吃 token。
5. 把个人偏好写到项目级 CLAUDE.md
所有文件型方法都有「用户级」的对应版本,它们在每个 Claude Code session 都会被加载,不管你在哪个 repo。用本地文件放个人偏好(比如「总是用语义化 commit message」)。把项目级文件留给那些「团队共识但跟特定代码库相关」的偏好。
进阶:把它们打包成 plugin
一旦你把 CLAUDE.md、Rules、Skills、Subagents、Hooks、Output styles 玩顺了,你可以把它们打包成 plugin,在团队成员或项目之间分享一套连贯的配置。
这是 Harness 真正变成「团队资产」的方式。不是每个人都从零搭一遍,而是一套经过验证的 Harness 配方在团队里复用。
真实案例:一个朋友的 Harness 实战
光说不练假把式。
讲个真实例子。
我一个做内容的朋友,上周花了 10 分钟搭了一套 Harness:写一份 CLAUDE.md 规定风格偏好、写两个 Skill(一个负责选题流程、一个负责文章自检)、配一个 Hook 自动跑 L1 检查。
然后他开始写文章。
从选题到发布,整个流程他只说了三句话:「写今天的文章」、「这个角度不行换一个」、「OK 发」。
剩下的事情,全部由 Claude Code 自己做:
自己查热点、自己选选题 自己按风格写正文 自己跑 L1-L4 自检 自己生成封面 自己发到公众号
他从过去每天花 3 小时写文章,到现在每天 1 小时搞定。效率差 3 倍不止。
没有 Harness 的写法:跟 Claude 一句一句聊,告诉它「你要口语化一点」、「你开头加个故事」、「你再短一点」、「诶这个比喻不好换一个」...改 50 轮,可能还是不满意。
有 Harness 的写法:你只需要定义好规则和流程,然后让 AI 自己跑。你做决策,它执行。
怎么开始搭建你自己的 Harness
看到这你可能心动了。
但别急着上 Claude Code,先问自己三个问题:
你现在用 AI 的最大痛点是啥?是「它不听话」还是「它干得慢」还是「它记不住东西」? 你愿意花多少时间搭 Harness?10 分钟 / 1 个小时 / 1 天? 你有多少个需要 AI 帮忙的「重复任务」?
根据回答,路径不同:
路径一:0-1 个小时(零基础)
装上 Claude Code 写一份 CLAUDE.md,把你最重要的 5 条规范写进去 跑一个月,看看哪些地方「AI 老犯错」。这些就是下一个 Harness 要解决的问题
路径二:1-3 个小时(有一点基础)
上面那些做完 挑 1-2 个你每周都要干的重复任务,把操作流程写成 Skill 配 1-2 个 Hook 自动化「AI 改完文件后的检查」
路径三:3+ 个小时(深度玩家)
上面那些做完 设计 Subagent 分工,把复杂任务拆给 AI 团队 设计完整的 Memory 系统,让 AI 跨会话记住项目知识
我的建议:先从路径一开始。
Harness 不是一次性搭好的,是「养」出来的。你用 AI 越多,你越知道它哪里不行,你就越知道 Harness 应该补什么。
未来不是 Prompt 工程师的天下,是 Harness 工程师的天下
最后讲个更大的。
2023 年,全世界都在喊「Prompt Engineer 是未来最性感的职业」。
2024 年,人们发现 Prompt 工程没那么玄乎,写 Prompt 本身门槛不高。
2025-2026 年,真正的护城河是 Harness。
为啥?
模型能力趋同:Claude 、GPT、Gemini 之间的能力差越来越小 Prompt 越来越标准化:各种「最佳实践」已经被打包成工具和模板 真正的差异化在于「工程系统」:你怎么把模型嵌进你的工作流,怎么让它跟你已有的工具、知识、习惯无缝衔接
这就像当年「懂 Java 的人值钱」,后来「懂 Spring 框架的人值钱」,再后来「懂微服务架构的人值钱」。
编程语言、框架、架构。技术栈在变,但「把技术整合成系统解决问题」这件事的价值在持续上升。
AI 时代,这个「系统」就叫 Harness。
未来 5 年,最值钱的不是「会用 AI 的人」,是「会搭 Harness 的人」。
他们可能是:
AI 产品经理(设计 Harness 的人) AI 工程师(实现 Harness 的人) AI Native 的独立开发者
而你,今天看完这篇文章,就比 99% 的人更早知道这个游戏。
剩下的,就是动手搭一套自己的 Harness。
写在最后
写到这里 4000 多字了。
从 Harness 是什么,到 Harness 跟模型的关系,到 Claude Code 七件套拆解,到我自己怎么用 Harness 写这篇文章,到怎么开始搭自己的 Harness,到未来 Harness 工程师是趋势。
如果你只记住一句话,我希望是这句:
「模型是马力,Harness 是方向盘。」
再好的发动机,没有方向盘也开不上路。
现在,开干吧。
装个 Claude Code,先写一份 20 行的 CLAUDE.md。
然后用一周,再回来告诉我你发现了啥。
