 夜雨聆风
夜雨聆风
💡引言
在运动科技与人形机器人的交叉研究领域,动态且伴随高冲击力的全身交互任务一直是控制领域的难题。足球射门是其中的典型基准,要求机器人在保持单腿动态平衡的同时,在毫秒级的接触时间内对球体施加很高的冲量,并控制好球的运动轨迹。现有人形机器人在执行该任务时存在明显的技术瓶颈:传统的运动跟踪方法能提供基础的全身稳定性,但其固定的动作参考框架难以适应变化的球体位置与击球时机;纯任务奖励驱动的强化学习在面临庞大状态空间与稀疏反馈时,往往难以探索出有效的击球动作。本文分析的 RoboNaldo 系统,提出了一套三阶段的运动引导课程强化学习架构,把平衡维持与目标导向的动力学打击过程解耦开来,为高动量条件下的复杂全身人机交互问题提供了一种可行的技术路径。

图 1:RoboNaldo 真实机器人足球射门总览图

📊推文概览
联合研发团队与发表背景:该项研究由香港大学、香港中文大学及具身智能企业源策未来的联合团队完成,于 2026 年 6 月在 arXiv 发布,系统运行于 Unitree G1 人形机器人平台。
硬件部署与感知架构:系统摒弃了对外部动作捕捉设备的依赖,采用纯机载算力与传感器网络运行。通过头部激光雷达与胸部红外相机的传感器融合,实现了在真实室外草地环境下的自主目标定位与运动球追踪。
核心性能指标测试:在真实物理世界的测试中,系统于 3 米距离下展现出较高的定向打击精度。定位球平均靶向误差为 0.73 米,移动球平均误差为 0.86 米。
高动量动力学验证:系统在打击过程中产生的碰球后最高球速达到 13.10 m/s,约合 47.2 km/h。这一数值约为欧洲杯男子球员运动战射门速度的 59% 至 71%,说明系统能够产生足够强的击球冲量。
🛠️核心突破
1. 行业背景:连续接触与高动量脉冲的控制分歧
人形机器人在接触密集的运动操作领域近年来取得了进展,如推箱子、举重物或在复杂地形中行进。这些任务的核心共性在于驻留时间接触,系统可以在多个连续的控制步长内累积交互奖励并进行姿态微调。然而,足球射门代表了物理交互的另一个极端:接触发生在一个极短的时间窗口内,在 200Hz 的控制频率下仅持续 3 至 5 个物理步,不到 10 毫秒,同时作为接触执行器的腿部在发力的瞬间不能破坏躯干重心的整体稳定性。
早期的机器人足球系统多侧重于基础移动与接近球体,但在射门环节的评估上缺乏精度与力度的双重验证。下表列举了现有具身智能足球射门系统的能力象限对比。
表 1:各类型人形足球机器人系统核心能力对比。PAID 系统虽然引入了渐进式框架,但其评估使用方向余弦指标,无法解析亚米级的精度差异,且未在目标点位精度上进行测试。现有的踢球框架普遍面临一种两难。对抗性运动先验虽然能促使系统表现出类似人类的运动模式,但在何时起脚以及瞄准何处等具体任务目标上缺乏明确的监督信号,导致射门行为具有较高随机性。RoboNaldo 的思路是区分不同学习信号在不同训练阶段的作用边界,由此构建出逐步递进的解耦架构。
2. RoboNaldo 三阶段课程强化学习机制
为了缓解强化学习在庞大探索空间中的信用分配难题,研究团队设计了一套由三个阶段组成的学习课程。每个阶段承接前一阶段的神经网络检查点进行初始化,逐步加大任务难度。
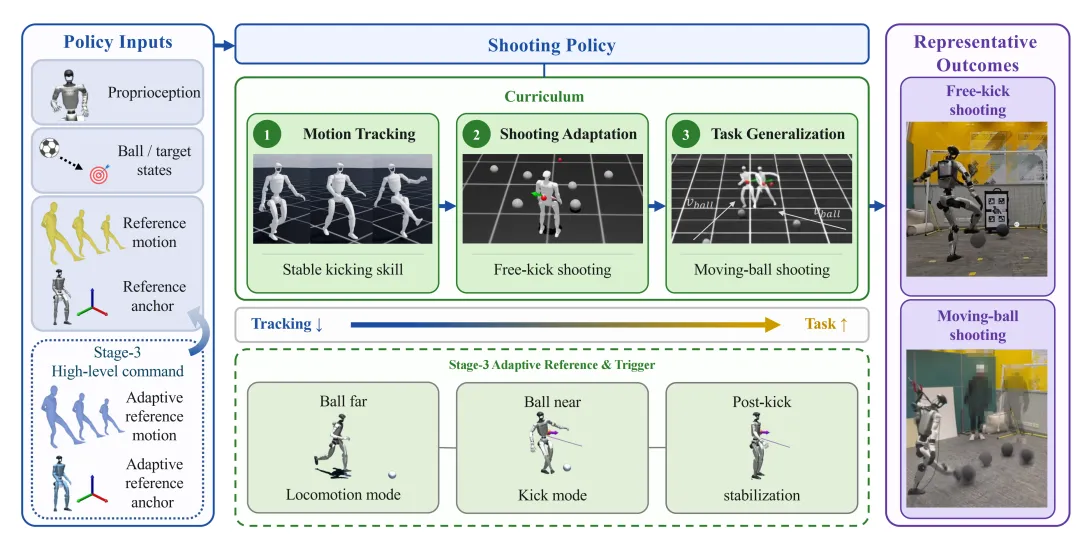
图 2:RoboNaldo 运动引导课程架构图
图2描绘了系统策略的顺序训练流程。底层策略从跟踪重定向的人类踢球动作出发,过渡到带有射门奖励的定位球自适应训练,最终集成高层移动指令接口以应对移动球场景。
第一阶段:射门运动跟踪。在初始设定中,环境不存在球、球门以及任务奖励。系统使用的参考轨迹,是通过 GVHMR 和 GMR 技术从人类踢球视频中重定向提取的一段侧脚踢球动作。策略在此阶段仅执行动作模仿。这一阶段为整个系统打下了稳固的底层运动基础,使机器人在不涉及外部目标交互时,率先掌握支撑腿平衡、髋关节发力与上肢反向协调的基础运动特征。当系统动作噪声标准差收敛,且跟踪奖励不再显著上升时,模型进入第二阶段。
第二阶段:射门自适应。这一阶段引入了足球、靶向点和射门任务奖励。球的初始生成位置在标称接触点前方 1 m × 1 m 的方形区域内随机采样。这一机制迫使策略打破原有的固定回放模式。为了获取射门奖励,系统必须根据球与目标的相对空间坐标,自主修改接近步态、调整触球点位置并改变挥腿的几何向量。在此阶段结束时,模型已经具备处理高精度定位球的能力。
第三阶段:任务泛化与时序对齐。移动球射门引入了核心的时间对齐挑战。若球以 5 m/s 的速度向机器人滚动,有效接触窗口极短,而前一阶段固化的挥腿时钟无法自动与之匹配。此时,研究人员在控制环中引入了一个模块化接口:高层移动指令与踢球触发器。
在训练期间,一个设定好的启发式规划器负责评估当前态势。规划器计算球体预测位置 pb = pb,⊥ + vb,⊥Th,其中预测视野参数 Th 取 0.4 s。当系统判断最小接近距离满足阈值条件 rthr < 0.25 m,且球高度在可击打范围内时,规划器向底层策略发送触发信号。底层策略接收信号后,其内部相位时钟被瞬间对齐至踢球阶段,完成从跟踪接近到高动量打击的模式切换。踢出球后,系统会强制维持一个稳定期,以抑制为了获取高瞬间奖励而导致身体失衡摔倒的不良策略。
3. 奖励工程:瞬时交互与密集化信用分配
在算法底层,RoboNaldo 在单步奖励函数上的设计,是实现高冲量与高精度并存的关键。传统的 HDMI 框架在奖励持续接触时有效,但用在足球射门时,会使网络在短暂的撞击瞬间难以获得有效的学习信号。系统设计的瞬时交互奖励覆盖了踢球的完整过程,公式表示为:
rinteract= (Rcontact + Rgoal) × (Rvel + Rforce) / 4
其中,Rcontact 用于引导脚部接近球体,Rforce 与 Rvel 要求产生足够大的撞击冲量,而 Rgoal 保留了方向指向性梯度。通过乘法与加法项的组合,该方程不仅防止了奖励在短接触期间坍缩,还有效过滤了那些力量微弱或偏离目标的低效踢击动作。
系统还实施了密集化射门奖励。由于球脱离机器人的瞬间,其最终落点已被物理定律锁定,但环境判定奖励却要等到球滚过球门线。针对这一时间差,系统在球离开脚后的每一个物理步长中,利用弹道学公式实时外推球的落点预测:
t*= (vb,y + √(vb,y2 - 2pb,yg)) / g
并根据预测落点误差持续发放密集奖励。这种跨越时间维度的信用分配方式,明显加快了训练后期的收敛速度。对于运动跟踪奖励的冲突处理,系统采用了基于距离的松弛因子。当下肢与球的距离进入近场范围 dnear = 0.35 m 时,系统自动将足部线性速度的跟踪权重 μ 降至 0.05。这给了脚踝在接触瞬间很大的空间自由度,而骨盆和上肢的方向跟踪权重仍保持在 0.6 左右,以维持身体平衡。
4. 观测空间与网络架构设置
在策略网络的架构层面,机器人每一步的状态输入由一个 547 维的观测向量构成,主要包含四部分。运动参考:29 个自由度的参考关节位置与速度。本体感受:过去 5 个时间步的 29 个关节位置、关节速度及动作指令历史。外感受觉:过去 5 个时间步在机器人坐标系下的球体位置与目标位置。锚点指令:在第 3 阶段中,高层发送的 9 维机动指令替代了原有的锚点参考。
策略网络采用 PPO 算法更新,在 Isaac Lab 内配置 4096 个并行环境。网络的 Actor 与 Critic 均使用 3 层多层感知机,维度配置为 512-256-128,采用 ELU 激活函数。超参数方面,熵系数设为 0.001,价值损失系数为 1.0,并设定 5 个学习周期和 4 个微批次。Critic 网络在训练时接收无噪声的特权全局信息,而 Actor 网络仅依赖带有噪声的机载观测数据,这有助于策略向真实物理硬件迁移时保持较强的鲁棒性。
5. 跨越虚实鸿沟:机载感知与域随机化
将具有极强动态特征的控制策略部署到真实的 Unitree G1 硬件上,且全程使用 50Hz 机载算力,需要解决严重的物理现实差距。该机器人包含 29 个自由度,整机质量约 35 千克。
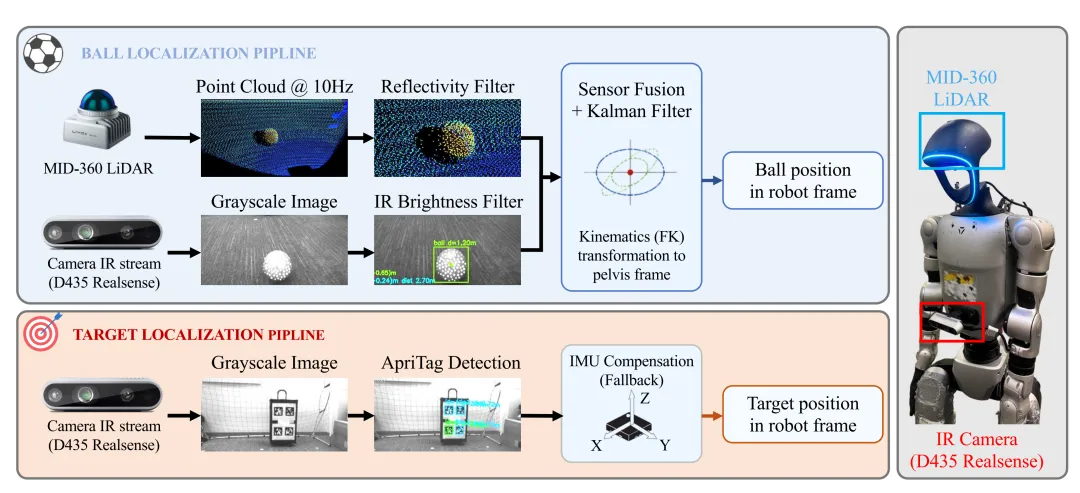
图 3:真实世界感知栈结构图
图解表明,系统依靠下倾固定的 MID-360 激光雷达处理近场数据,依靠胸部的 D435 红外相机弥补远场视野,两路信号最终在恒速卡尔曼滤波器中融合,生成骨盆坐标系下的精确定位。在视觉感知管道的设计上,研究人员发现主流的 RGB 视觉模型,例如 YOLO11 检测器,在面对高速运动的足球时,极易因运动模糊及室外复杂光照背景而丢失目标。为此,系统放弃了 RGB 通道,转而利用激光雷达的高反射率滤波以及 D435 的红外亮度截取,对反光材质足球实现了10 至 20 毫秒延迟、且抗模糊的高精度追踪。
为了支撑策略平滑迁移,仿真阶段引入了详尽的域随机化处理。每回合均随机生成不同的碰撞材质属性,静态摩擦系数设定在 0.3 ~ 1.6 之间,动态摩擦在 0.3 ~ 1.2 之间;恢复系数区间为 0 ~ 0.5;此外,系统对关节默认位置设定 ±0.01 弧度的偏差,并向机身质心注入最高侧向或垂直 ±0.05 m 的偏移 [1]。比较关键的是,系统每隔 1 至 3 秒便施加一次高强度的随机基座推力,其中包含最高 ±0.5 m/s 的水平速度扰动及 ±0.78 rad/s 的偏航角速度扰动。这些较为严苛的训练环境,造就了策略在草地上展现出的较高存活率。
6. 实验性能与消融分析
系统在仿真与现实世界中的量化表现证明了这一架构的有效性。在验证模型组件的仿真消融实验中,系统的各个模块展现出了清晰的因果关联。
几组对照的差距相当明显。纯 PPO 基线几乎无法完成射门,0.5 米内成功率只有 0.6%,不跌倒存活率约 10%;完整的 RoboNaldo 阶段 3 则把 0.5 米与 1.0 米内的成功率分别提到 32.4% 和 63.3%,存活率升至 98.8%。组件的作用也很清楚:去掉启发式触发接口后,存活率从约 99% 跌到 32.8%;去掉踢出后的稳定期约束,存活率进一步掉到 24.4%。这两组数据说明,时序控制是移动球场景下不摔倒的关键。
在实体部署中,RoboNaldo 执行了 136 次定位球尝试与 27 次移动球尝试。在定位球环节,机器人完成 124 次有效发球,存活率为 100%。进一步的数据拆解显示,系统针对左、中、右不同方位的目标均保持了较好的稳定性,中心目标的命中精度最高,平均径向误差为 0.65 米。
表 2:Unitree G1 真实硬件户外测试核心结果。移动球场景由于人类传球的不确定性,有效接触率降至 74.1%,但只要接触形成,仍保持了亚米级的平均精度。
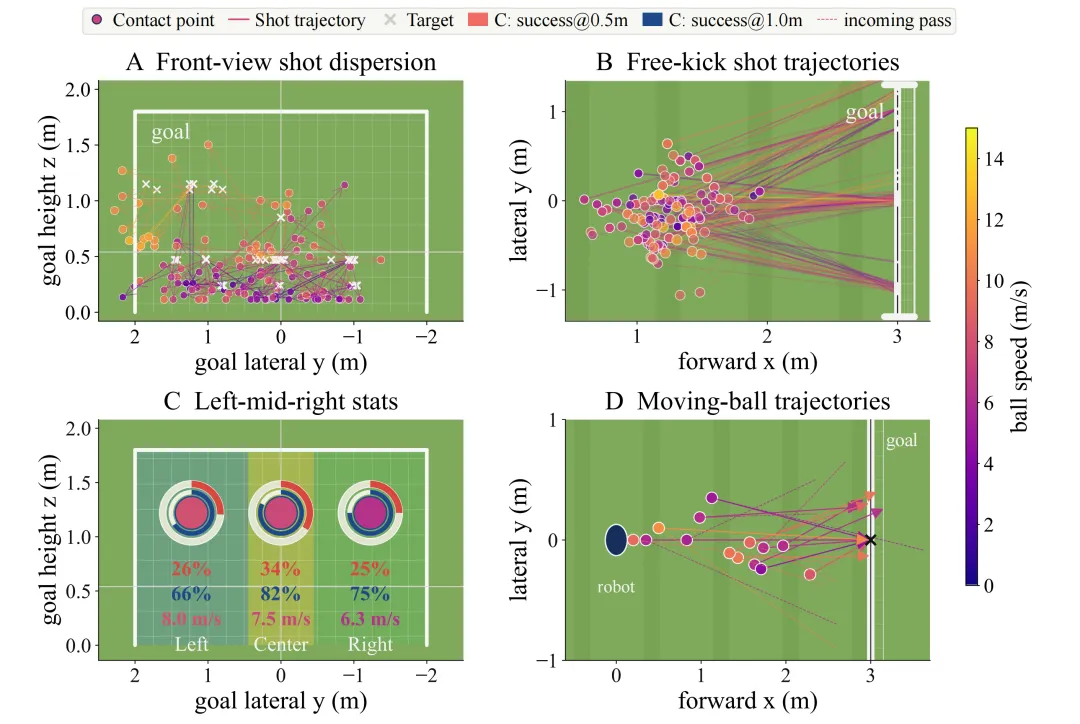
图 4:真实机器人射门数据概览图
包含四个视角的图表,通过散点图呈现了定位球与移动球在目标平面上的落点散布情况,显示出机器人在发力时表现出一定的类人偏好,例如更习惯用右脚发力。

图 5:真实机器人射门展示图
连续快照展示了机器人从获取感知信息、抬腿摆臂平衡、到触球瞬间以及完成射门后姿态恢复的整个物理时序。
🚀技术应用猜想
生物力学数字孪生测试台
目前的运动鞋靴研发与评测高度依赖机械化气动测试设备或真人穿戴测试。机械设备难以还原人类下肢复杂的关节受力模型,真人测试则缺乏力学数据上的一致性与可重复性。具备高精度目标瞄准与真实关节动力学的人形机器人,可以作为数字孪生测试系统,在真实场地环境下重现 13.1 m/s 级别的特定速度和特定切角的冲击瞬间。这种可编程的物理测试基准,能为运动装备的材料形变测试和鞋底抓地力研发,提供更接近真实受力情况的数据。
战术导向的自适应体育陪练系统
与依赖固定轨道射出的传统发球机不同,RoboNaldo 证明了机器人在接收不规则传球时进行“即兴”调整与反击的能力。在网球、足球等高水平专项训练中,如果将架构中的启发式规划器替换为理解特定战术图谱的多模态策略网络,人形伴练可以模拟特定类型人类球员的跑动习惯和击球偏好,通过细微改变触球角度施加不可预测的自旋与落点,从而在更真实的博弈环境中训练运动员的瞬间反应能力。
工业敏捷操作与突发环境高动量干预
传统工业机器人通常被设定为避免高速物理冲击,以防止机械结构损伤。然而,灾难搜救、高危作业或特殊制造业中,往往需要系统能产生短促且极高的撞击力(例如踢开受阻的障碍物、实施瞬时冲压辅助)。RoboNaldo 解耦运动平衡与瞬时脉冲释放的策略,为通用的工业操作机器人赋予了“爆发力”维度的控制能力,使其在执行高脉冲接触任务后迅速恢复姿态,扩大了机器人在非结构化环境下的操作边界。
💬延伸讨论
RoboNaldo 在控制架构层面提供了一种新的思路。这个系统的价值不止在于让机器人能够踢出高速足球,它还通过高层接口,把高层的任务决策与底层的动力学执行做了清晰的分离。前者负责判断何时触发动作、瞄准何处,后者负责毫秒级的关节响应与受力适应。
以往的研究常试图通过单一的端到端大模型统揽全局,这在处理包含高频率反馈和较高失衡风险的动态任务时,往往导致训练不稳定甚至失败。RoboNaldo 的三阶段课程学习表明,将人类先验运动作为底座,再通过环境目标进行边界自适应,最后将高维度时间决策交还给规划器,是一种兼具可解释性与鲁棒性的工程路径。
这意味着在未来的通用机器人生态中,多模态大模型只需关注宏观层面的情境理解,并在恰当的时机下达触发指令,而复杂的瞬间关节响应、受力变形和重心调整,则交由底层经过课程学习固化下来的运动模块自动接管。这种层级清晰的分工,也反映出人形机器人控制正从缓慢的持续接触,逐步走向更敏捷、更具爆发力的动态交互。
https://arxiv.org/abs/2606.11092v2
原文地址

欢迎体育人共建AI Agent生态

智体研团队正在招募实习生,方向包括科研与产品两类,研究领域聚焦动作捕捉以及相关的人体运动分析与建模。
科研方向偏算法与数据,主要参与运动信号处理、步态与姿态建模等工作,具体内容会结合个人背景与项目需求安排。产品方向偏落地,关注相关技术如何转化为可用的产品形态,参与需求调研、原型搭建与迭代推进。
我们希望你对动作捕捉、可穿戴或运动健康领域有真实兴趣,愿意动手。有信号处理、机器学习、运动科学或人机交互相关基础者优先,基础一般但学习意愿强的同学也欢迎沟通。时间上,希望每周能保证若干天稳定到岗。
工作地点为上海,待遇面议。有意者请将简历发送至,并简要说明意向方向与个人兴趣。

