 夜雨聆风
夜雨聆风点击蓝字 关注我们
AI academic space

推荐使用最新科研AI工具:
https://chat.cnpaperdata.com
本文基于 Barcelona School of Economics(BSE)工作论文:
Mayoral, L., Mueller, H., Philipp, M., Rauh, C., & Vassallo, R. (2026).Semantic Similarity Measures in Newspaper Text for Detecting and Predicting Disruptive Institutional EventsBSE Working Paper No. 1555
研究使用全球新闻文本与机器学习方法,构建制度性冲击的识别与预测框架,覆盖政变、任期延长与司法系统弱化等事件类型。
作者来自 Barcelona School of Economics(BSE)、Universitat Pompeu Fabra(UPF)等机构,研究方向集中在政治经济学与文本数据建模。
数据来源与事件定义
研究构建了跨国制度性事件数据集,覆盖三类核心事件:
• 军事政变(Coup d’état) • 任期限制规避(Term-limit evasion) • 司法系统弱化(Judiciary weakening)
数据来源包括多个权威事件数据库:
• Cline Center Coup Dataset • Powell & Thyne Coup Data • Versteeg et al. term-limit dataset • Helmke judicial manipulation data • DEED(Democratic Erosion Event Dataset)
最终形成覆盖 194个国家、1989年以来的月度面板数据。
新闻数据部分来自全球主流媒体数据库:
• Factiva • LexisNexis • BBC Monitor • Associated Press • The New York Times • The Economist • LatinNews
总规模约 600万条新闻标题,按国家与月份进行结构化整理。
方法链条:从新闻到风险变量
研究的核心是将新闻文本转化为可用于统计建模的风险指标,整体流程可以分为四个连续步骤。
文本向量化(语义空间构建)
每条新闻标题首先被映射到向量空间。
中文场景下推荐的 embedding 模型为:
Kingsoft-LLM/QZhou-Embedding-Zh(MTEB #1)或Tencent/Youtu-Embedding(工业级强基线)
这些模型在语义排序任务中表现稳定,适用于事件检测场景。
from sentence_transformers import SentenceTransformermodel = SentenceTransformer("Kingsoft-LLM/QZhou-Embedding-Zh")vec = model.encode("军方宣布接管国家政权")输出为高维语义向量,用于表示新闻在语义空间中的位置。
事件语义原型(Prototype)
每类制度性事件通过“语义原型”进行定义。
原型由40–70条典型新闻标题构成,例如:
• military takeover • constitutional manipulation • judicial intervention
这些样本经过 embedding 后取平均,形成事件中心向量。
import numpy as npevent_vec = np.mean(model.encode([ "军队进入首都并控制政府机构", "政府宣布解散议会", "军事力量接管国家政权"]), axis=0)这一向量代表某类制度性冲击的语义中心。
语义匹配(风险强度测量)
每条新闻与事件原型计算余弦相似度:
from sklearn.metrics.pairwise import cosine_similarityscore = cosine_similarity([news_vec], [event_vec])[0][0]该分数用于刻画新闻与制度性冲击语境之间的接近程度。
在这一阶段,每条新闻被转化为一个连续风险信号。
国家-月份风险指标
在文章层面完成计算后,进一步聚合到国家-月份:
Risk(i,t) = mean similarity(all headlines in country i at month t)同时构建补充统计量:
• 最大相似度(max) • Top-k平均 • 标准差(离散程度) • 新闻数量(coverage)
这些变量共同构成文本驱动的风险特征体系。
事件识别模型(Nowcasting)
在事件识别阶段,研究使用监督学习模型判断某国某月是否发生制度性冲击。
主要模型为:
• XGBoost(主模型) • LightGBM • CatBoost
输入变量包括三类信息:
语义特征
• mean / max / std similarity • top-k similarity
文本结构特征
• 新闻数量 • LDA主题分布
历史结构特征
• 距离上次事件时间 • 最近事件频率 • 选举周期变量
输出为:
事件发生概率(0–1)
模型在不同事件类型上的表现稳定:
• Coup:AUC ≈ 0.90 • Term-limit evasion:AUC ≈ 0.92 • Judiciary weakening:AUC ≈ 0.80
embedding特征在所有类别中均提供稳定增益。
事件预测(12个月滚动预测)
在识别基础上,研究进一步构建预测模型,用于估计未来12个月内事件发生概率。
方法采用 expanding window 设计:
• 每月更新训练样本 • 仅使用历史数据训练 • 输出未来12个月风险概率
核心模型为 Random Forest,通过多棵树集成建模非线性关系。
输入变量延续识别阶段特征,并加入时间衰减与长期历史结构信息。
中文场景实现路径
该方法可直接迁移至中文新闻与政策文本分析任务。
参考榜单:
https://huggingface.co/spaces/mteb/leaderboard
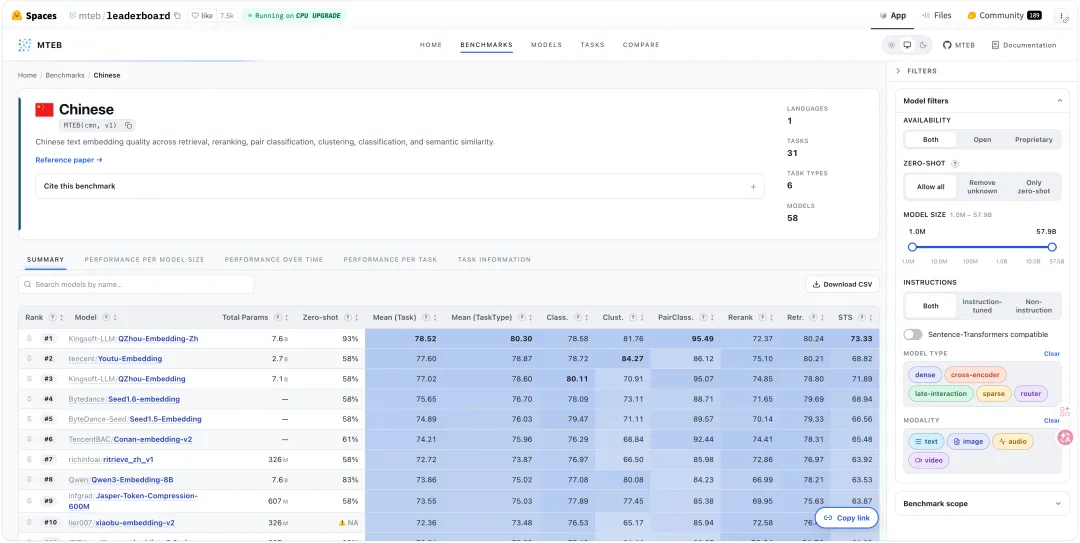
推荐 embedding 模型:
中文实现示例
from sentence_transformers import SentenceTransformerfrom sklearn.metrics.pairwise import cosine_similarityimport numpy as npmodel = SentenceTransformer("Kingsoft-LLM/QZhou-Embedding-Zh")event_vec = np.mean(model.encode([ "政府解散议会并接管司法系统", "军方宣布接管国家政权", "修改宪法延长总统任期"]), axis=0)news_vecs = model.encode([ "总统宣布解散最高法院", "议会通过宪法修正案", "经济政策保持稳定"])scores = cosine_similarity(news_vecs, [event_vec]).flatten()risk_index = np.mean(scores)方法结构总结
整体系统可以抽象为:
新闻标题→ embedding(QZhou / Youtu)→ prototype similarity→ country-month aggregation→ XGBoost nowcast→ Random Forest forecast结论
该研究构建了一套基于语义相似度的制度性风险测度框架,将全球新闻文本转化为连续可计算的风险时间序列,并进一步用于事件识别与预测。
其核心结构可以概括为:
用 embedding 空间中的语义距离,将新闻转化为制度性风险信号,并在时间维度上构建可预测的风险轨迹。
InfinitePaper AI 现已正式上线!
我们诚邀您即刻体验,感受AI如何重塑您的科研工作流。
新用户专享福利:即日起关注公众号后台发送 [ AI福利 ],即可领取7 天高级会员!
教育福利:添加客服完成 教育认证,即可再享受会员 8 折优惠!
分享福利:转发本文至朋友圈(保留2小时)或科研群(15人以上),截图发送至客服,可领取科研工具包 (包含:经济学理论手册、科研AI手册)!

活动期间永久会员最高可直降 560 元!

点击“阅读原文” 直达官方网站
