 夜雨聆风
夜雨聆风前阵子有个做历史研究的朋友找我,说手头有一批民国时期的旧报纸扫描件,大概四十多页,想把里面的文字全部提取出来做数字化存档。他问我有没有什么好用的OCR工具推荐。
我当时心想,这还不简单,市面上大把方案随便挑一个不就完事了。
然后他发了一张样例过来。
手写批注混着铅字印刷,栏与栏之间排版不规则,泛黄的纸张上还有水渍和折痕。我丢进几个常用的OCR工具试了一圈。
惨不忍睹。
要么漏掉大半文字,要么识别出来全是乱码。有一款倒是认出了百分之七八十的内容,但把竖排当横排读,出来的文字根本没法用。朋友发来一串省略号,我也一时间无语凝噙。
说真的,那一刻我才意识到,OCR这件事,我们可能一直都低估了它的难度。
很多人对OCR的印象还停留在"拍个证件照自动识别身份证号"那个阶段。确实,日常生活里用到的OCR场景大多很简单,清晰的印刷体、标准的排版、单一的语言。这种情况下,十年前的技术就已经够用了。
但真实世界的文档是什么样的?
倾斜的、模糊的、手写体和印刷体混排的、中英文夹杂的、表格里嵌着表格的、一页纸上密密麻麻挤了好几栏内容的。这些才是现实中真正让人头疼的场景,也是过去十年OCR技术一直在啃的硬骨头。
而2026年,事情开始变得有点不一样了。
如果你关注这个领域的话,大概从今年上半年开始,会发现一个很有意思的趋势,大厂们突然开始密集地往OCR这个赛道里砸资源。先是DeepSeek开源了自己的OCR模型,效果相当惊艳,社区一片叫好。然后百度也坐不住了,直接扔出来一个叫Unlimited-OCR的开源项目。
我跟你说,这个名字起得就很有意思。Unlimited,无限的。什么无限?上下文长度无限。

坦率的讲,我第一次看到这个项目的时候,注意力全被一个数字吸引住了。
32768。
这是它支持的最大token数。你可能对这个数字没什么概念,那我换个说法,它一次性可以处理的内容量,大约相当于一本中等篇幅的小说。一整本。
你想想看,以前的OCR工具怎么处理长文档的?一页一页来。你得先把PDF拆成单页图片,然后一张一张丢进去识别,识别完再手动拼回去。流程繁琐不说,页与页之间的上下文关系还全丢了。比如一个表格跨了两页,拆开识别就是两堆不相关的碎片,拼都拼不回来。
而Unlimited-OCR的逻辑完全不同。你直接把整个PDF丢给它,它一次性吃进去,端到端地把所有内容解析出来。
不用拆页。不用拼接。不用手动干预。
这块其实挺关键的。可能有小伙伴纳闷,不就是一次性处理多页嘛,有什么了不起的?但你想想,一个四五十页的文档,里面可能包含几百个表格、上千段文字、各种图表和注释。要让模型一次性把这么多内容全部理解并准确提取,背后的计算量和对模型架构的要求,跟处理单张图片完全不是一个量级。
所以它叫Unlimited,不是随便吹的。
顺着上面的再聊聊它的具体能力。根据官方给出的信息,这个模型支持三种输入方式,单张图片,没问题。多张图片组成的多页文档,没问题。直接丢PDF文件,也没问题。
三种输入方式通吃,这一点我觉得还是挺重要的。因为在实际的工程场景里,你要处理的文档来源五花八门,有的是扫描件图片,有的是电子PDF,有的是手机拍的。如果一个工具只能处理某一种格式,你在工程链路上就要加一堆预处理步骤,既麻烦又容易出错。
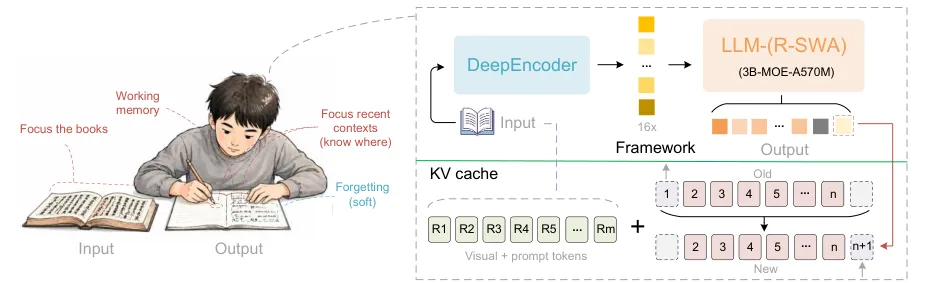
另外比较骚的是,它提供了两种图片处理模式。一个叫gundam模式,一个叫base模式,分别对应不同的文档类型和处理策略。你可以根据手头文档的具体情况来选择,而不是一刀切地用同一种方式处理所有东西。
还有一个细节让我印象深刻,它提供了两种推理后端。一个是基于Transformers的标准推理方式,适合大多数开发者上手。另一个是基于SGLang的高性能推理后端,适合需要大批量处理的场景。
这块需要注意一下,SGLang不是所有人都熟悉的。简单来说,它是一个专门为大模型推理优化的框架,特点是吞吐量高、延迟低。如果你是做档案数字化这种需要一口气处理成百上千页文档的场景,用SGLang后端会让效率提升非常明显。
还有一点,它支持流式输出。就是你在等它解析的时候,可以实时看到解析的进度和中间结果。这个体验就像看一个翻译员在你面前一页一页翻着念,而不是让你干等半小时然后一次性扔给你一个大文件。
说实话,这种交互细节,往往才是决定一个工具好不好用的关键。
那有人可能会问了,百度搞这个跟DeepSeek的OCR模型比起来怎么样?
这个问题很好,而且官方在README里其实没有回避。他们直接说了,目标是要push DeepSeek-OCR further。这话说得很直白,也很有底气。
我不是专业的评测人员,没办法给你一个绝对客观的横向对比。但从我了解到的信息来看,两者的核心差异主要在两个方面。
第一个是上下文长度。DeepSeek-OCR的上下文窗口相对有限,处理长文档时需要分段。而Unlimited-OCR主打的就是32768 token的超长上下文,天然适合长文档场景。
第二个是多页处理能力。DeepSeek-OCR更偏向单图场景的极致优化,而Unlimited-OCR从设计之初就把多页和PDF作为核心使用场景。
不是说谁一定比谁强,而是说它们瞄准的其实是不同的痛点。DeepSeek-OCR像是一台精度极高的单页扫描仪,而Unlimited-OCR更像是一台可以一次性吞掉整摞文件的数字化工作站。
我有时候觉得,技术产品之间的比较,不应该简单地排个一二三名。不同场景有不同的最优解,这才是正常的。
说到这里,我突然想聊一个更大的问题。
为什么2026年,大厂们突然都在卷OCR了?
其实吧,原因并不复杂。过去两年大模型的爆发,让所有人发现了一个现实问题,模型的能力再强,如果它"看"不懂原始文档,那它就只能处理已经被人工整理好的结构化数据。而这个世界上,绝大多数的信息还是以非结构化的形式存在于各种文档、图片、扫描件里。
说到底,OCR不是什么新东西,它有几十年的历史了。但当它跟大模型的能力结合在一起的时候,性质就变了。
以前的OCR只是在"认字",把图片里的像素转换成文字。现在的OCR模型在做的事情,是"理解文档"。它不仅认字,还能理解排版结构、表格逻辑、图文关系,甚至跨页的上下文语义。
这个转变的意义,可能比我们想象的要大得多。
你想想看,图书馆里那些还没被数字化的古籍,档案馆里那些泛黄的历史文件,医院里堆积如山的纸质病历,法院里几十年积累的卷宗。这些信息如果能被AI准确地读取和理解,释放出来的价值是难以估量的。
我一直觉得,AI技术真正改变世界的那一刻,不是它在某个基准测试上刷出了新高分,而是它让一个历史研究者可以在一晚上完成以前需要一个月的档案整理工作。
让一个医生可以快速检索十年前某个病人的所有手写病历。
让一个普通人可以把家里压箱底的老报纸扫描存档,留住那些快要被遗忘的文字。
这些事情听起来没那么酷炫,但它们是真实的、具体的、对人有意义的。
我始终坚信,技术最好的样子,就是让那些原本门槛很高的事情变得简单。Unlimited-OCR做的就是这件事。它把"处理一整本复杂文档"这个以前需要专业团队和大量人力的工作,变成了"把PDF丢进去,等结果出来"这么一个简单动作。
当然了,我也不打算把这个项目吹得天花乱坠。任何开源项目都有它的问题和局限。比如32768 token虽然很长,但面对一些特别极端的超长文档,可能还是需要分批处理。比如OCR的准确率在面对严重退化的历史文档时,肯定还是会有瑕疵。比如两种推理后端的部署门槛,对没有GPU资源的个人开发者来说,可能还是有点高。
这些问题是真实存在的,而且短期内不太可能完美解决。
怎么说呢,我觉得评判一个技术产品的价值,不应该只看它还有哪些不足,更应该看它把可能性的边界往外推了多少。
而Unlimited-OCR做到的事情,是让人第一次觉得"一次性解析整本复杂文档"这件事是真实可行的。不是PPT里的畅想,不是论文里的实验,而是一个你可以直接clone下来跑起来的开源项目。
这种感觉太爽了。
回到我那个做历史研究的朋友。
前几天他又找我,说那批旧报纸的事已经搞定了。他用的也是类似的技术路线,把扫描件批量喂进去,出来的文字准确率比他预期的高不少。虽然还是需要人工校对一些模糊的段落,但工作量直接砍了百分之八十以上。
他说了一句话,我印象特别深。
"感觉像是突然多了十个实习生。"
我当时就愣住了。
不是因为这话有多深刻,而是因为它太真实了。对一个靠单打独斗做研究的学者来说,十个实习生的生产力意味着什么?意味着他终于可以把时间花在真正需要人脑思考的事情上,而不是埋在故纸堆里一个个字去敲。
愚钝如我,那一刻才真正理解了"生产力工具"这四个字的分量。
最后说一个我一直在想的问题。
当AI开始大规模地"读懂"人类文明留下的这些纸质遗产的时候,会发生什么?
不是技术层面的会发生什么,而是文明层面的。
那些躺在档案馆角落里几十年没人碰过的文件,那些因为没有人力去整理而被封存的史料,那些记录着普通人生活细节的老报纸和旧信件。它们一直在那里,等着被看见。
以前我们没有足够的人力和工具去触碰它们。
现在,也许有了。
想想就觉得兴奋。
我又想起了朋友那句话。感觉像是突然多了十个实习生。
十个不眠不休、不会抱怨、不嫌枯燥的实习生。它们安静地坐在那里,一页一页地翻开那些泛黄的纸张,把上面的文字一个字一个字地抄录下来。
不为别的。
就是为了让那些快要被遗忘的声音,能再被听到一次。
https://github.com/baidu/Unlimited-OCR
https://arxiv.org/abs/2606.23050
