 夜雨聆风
夜雨聆风你有没有想过一个问题:
ChatGPT怎么什么都知道?你问它历史,它懂;问它代码,它会;问它怎么做红烧肉,它还能给你列步骤。
它到底是怎么"学会"这些的?
今天不聊技术术语,不用公式,我用几个你一定能听懂的比喻,把这事讲明白。
第一个比喻:教婴儿认猫

想象你面前有一个从没见过猫的婴儿。
你不会跟它说"猫有4条腿、三角形耳朵、有胡须"——你只是一遍遍指着猫说:"这是猫。"
婴儿的大脑会自己从画面里提取特征:先是一个模糊的轮廓,然后是耳朵的形状、眼睛的颜色、体型的大小……经过成千上万次"这是猫""这不是猫"的训练之后,它的大脑里形成了一套判断标准。
AI的学习过程,就是这个婴儿认猫过程的数学版。
只不过,这个"婴儿"看的不是几百张猫的照片,而是几百万张。它学的也不只是认猫,而是认世间万物——文字、图片、代码、音乐、视频。
有个数据可以感受一下:一个人一辈子读的书大约相当于1亿字。而2023年的GPT-4训练时读过的数据约13万亿字,相当于1.3亿本小说——是人类一辈子阅读量的100万倍。
但这已经是三年前的数据了。到了2026年6月,DeepSeek V4 Pro的参数量已经达到1.6万亿,智谱的GLM-5.2有7440亿参数,而即将发布的GLM-5.5更将突破万亿参数大关。AI读过的数据量,早就不是"百万倍"能形容的了。
第二个比喻:蒙眼学切菜

现在想象你蒙着眼睛学切黄瓜丝。
你凭感觉切一刀,旁边有人告诉你:"太粗了!"你就调细一点。再切一刀,"太细了!"你再调粗一点。
经过几百次"切一刀→听反馈→调整力度"的循环,你终于能切出均匀的黄瓜丝了。
AI的训练就是这个过程。
技术上叫"梯度下降",但本质就是:不断试错,不断调整,直到找到最优解。
每次AI给出一个答案,系统会把它跟"正确答案"对比。错了就告诉它"你哪里错了",它就调整自己的参数。调对了就奖励,调错了就惩罚。几亿次调整之后,它就"学会"了。
第三个比喻:超级填空题选手

ChatGPT到底在干什么?
说白了,它就是一个超级填空题选手。
你给它:"今天天气真____"
它会根据读过的海量文本,预测最可能的下一个字是"好"。
你给它:"人生就像一盒____"
它预测下一个词是"巧克力"。
只不过,它不是填一个字,而是能连续填出一整篇文章、一整段代码、一整封邮件。
全世界最聪明的AI,本质上只在做一件事:预测下一个最可能出现的字。
听起来简单到离谱对吧?但当你把这件事做到极致——用几万亿个字的数据训练、用几万张显卡跑几个月——它就从"简单填空"变成了"看起来什么都会"。
第四个比喻:死记硬背 vs 真正理解
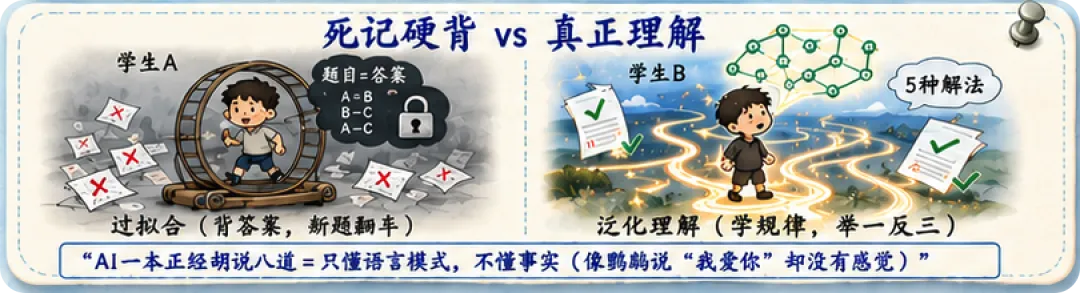
考试前,有两个学生:
学生A把所有历年真题都背下来了,每道题答案都对。但换了一道新题,完全不会做——因为他只记住了题目和答案的对应关系,没有理解解题思路。
学生B只做了几套卷子,但他掌握了5种解题方法,能解各种不同的题。
学生A就是"过拟合"的AI——在练习题上满分,遇到新题就翻车。
学生B才是好的AI——它不是记住了答案,而是学会了底层规律。
这也是为什么AI有时候会"一本正经地胡说八道"。它不是在"说谎",而是它学会的是"语言模式"而不是"事实"。它知道"什么话听起来像正确的",但不真的知道"什么是正确的"。
就像一个鹦鹉能流利地说"我爱你",但它并不真的有爱的感觉。
五个你可能好奇的问题
Q1:训练一个AI要花多少钱?
2023年,GPT-4的训练成本约1亿美元,用了约25000张顶级显卡,跑了3-4个月。
但到了2026年,情况完全变了。中国DeepSeek用557万美元就训练出了性能媲美GPT-4的模型——成本只有1/20。而现在微软正在考虑用DeepSeek V4替代OpenAI和Anthropic的模型,原因很简单:后者成本高出50倍。
打个比方:三年前造一辆跑车要1000万,现在有人用50万造了一辆性能差不多的。AI的训练成本正在以肉眼可见的速度下降。
Q2:AI读了多少书?
GPT-4的训练数据约13万亿个字。如果你每天读一本书(10万字),从出生读到80岁,你一辈子能读29万本书。
GPT-4读过的数据,相当于你从现在开始读4500万辈子。

Q3:AI会"思考"吗?
不会。 至少不是你以为的那种"思考"。
AI没有想法、没有情感、没有好奇心。它说"我觉得"的时候,不是真的"觉得"——它只是学会了在这个语境下,说"我觉得"是最合适的输出。
天气预报说明天会下雨,但天气预报本身不会被淋湿。
Q4:AI跟人脑一样吗?
名字像,本质不同。
神经网络借鉴了大脑神经元的概念,但运作方式差十万八千里。人脑是生物化学信号,AI是数字矩阵运算。就像飞机借鉴了鸟的翅膀,但飞机不是用扇翅膀的方式飞的。
Q5:AI会越来越聪明吗?
会,而且快得吓人。
2025年初DeepSeek-R1发布,它学会了"先想再答"——做数学题不再直接写答案,而是像人一样"审题→列步骤→验算→回答"。
到了2026年6月,GPT-5.5已经上线,DeepSeek V4被微软考虑大规模采用,智谱GLM-5.2在全球开源模型中编程能力排名第一,8月即将发布的GLM-5.5更将冲击万亿参数。
更关键的是,小模型也开始变强。面壁智能CEO李大海在2026年北京智源大会上透露:端侧小模型的智能水平已经追平GPT-4。 说明聪明的训练方法,比堆更多参数更有效。

一张图看懂AI学习的全流程
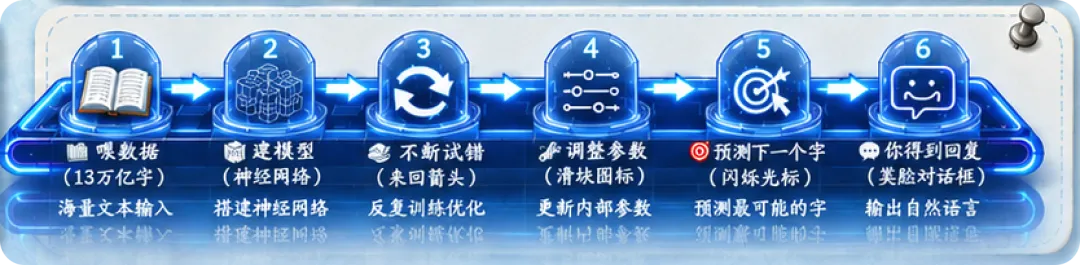
就这么多。没有魔法,没有意识,没有"顿悟"。
本质上,AI就是一个被海量数据喂出来的、超级强大的"模式识别器"。 它不理解世界,但它能识别世界运转的统计规律。
我最喜欢的一个比喻是这样的:
人类的学习方式是"从1到10"——先理解一个概念,然后逐步扩展。AI的学习方式是"从10亿到1"——先把所有数据塞进去,然后提炼出规律。
两种方式各有各的好。人类擅长从极少经验中举一反三,AI擅长从海量数据中发现人眼看不到的模式。
AI不是在模仿人类思考,它是在用一种全新的方式"理解"世界。
理解了这一点,你就不会害怕AI,也不会神化AI。它就是一个工具——一个超级强大的工具,但终究是工具。
它是怎么学会的?就是读了足够多的书,做了足够多的题,挨了足够多的骂。
跟人一样,只不过速度快了一亿倍。
技术很酷,但让技术变得有用的那个人,更酷。
关注「技术很酷」,学习落地好用的技术干货。
