 夜雨聆风
夜雨聆风
01
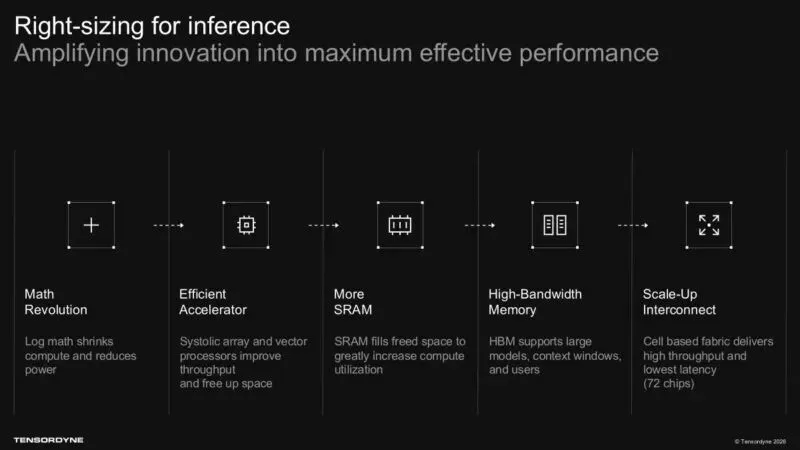
02
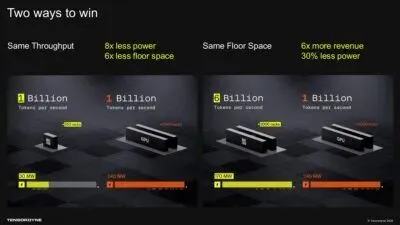
对于 2 万亿参数的模型,TensorDyne 的 TDN72 单机架(120kW),就能实现 1300 tokens / 秒的用户推理速度;
而如果用 NVIDIA 和 Groq 的方案,需要 9 个机架、1.5MW 的功耗才能达到同样的效果;
就算是 AWS+Cerebras 的方案,也需要 14 个机架、800kW 的功耗。


03
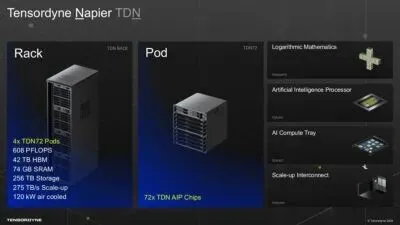
工艺:台积电 3nm 工艺;
晶体管:1380 亿颗;
算力:单颗芯片 2.1PFlops;
频率:加速器核心 1.33GHz,CPU 核心 1.5GHz;
内存:256MB SRAM,144GB HBM3E;

04


05
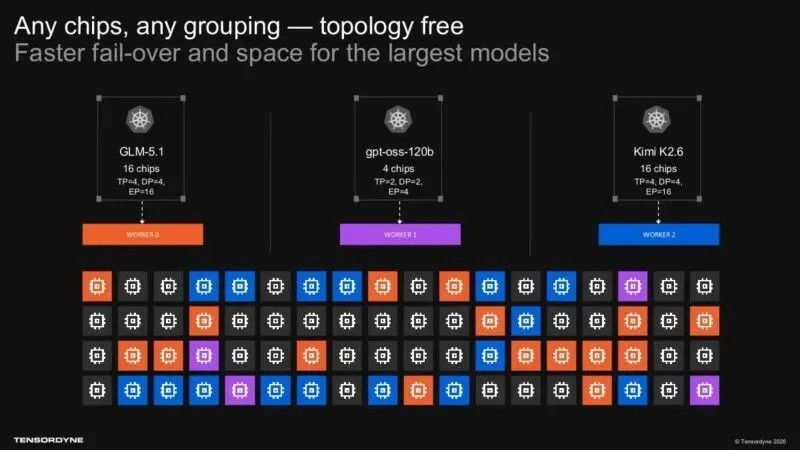
支持 Hugging Face 的模型 hub,开发者可以直接用现成的模型; 直接支持 PyTorch 和 Triton 模型的编译,不用大幅改代码; 自己的 Python SDK tensordyne.nn ,方便开发者适配; 

06
07
2026-06-10
2026-06-12

算力“迷你派”爆火!英伟达都在布局,5大优势解锁全场景数字新可能
2026-06-02

2026-05-29

2026-05-28

