 夜雨聆风
夜雨聆风每天一个 AI 术语 11
训练集(Training Set)
模型真正用来练习的那部分数据
上一篇:数据集(Dataset)|下一篇:监督学习(Supervised Learning)
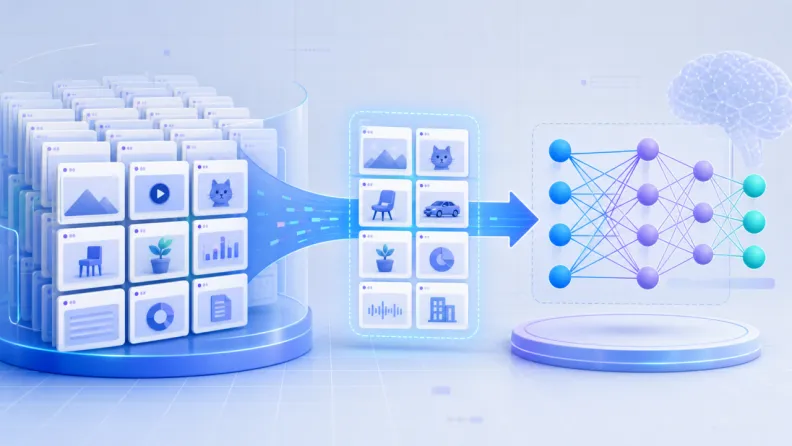
从上一篇“数据集”接着看
上一篇我们讲到,数据集是一组被收集、整理、组织起来的数据样本。它像一本题库,里面可能有图片、文本、语音、表格,也可能有对应的答案或标签。
但一个完整数据集通常不会全部拿去让模型学习。为了知道模型是真会了,还是只是把题库背熟了,我们会把数据按用途拆开。
其中,直接交给模型反复练习、用来更新参数的那一部分,就叫训练集(Training Set)。
训练集到底是什么
训练集不是一种新的数据格式,而是数据集里的一个角色。只要某批数据被拿来参与训练,让模型根据它调整内部参数,它就承担了“训练集”的作用。
可以把模型想成一个刚开始做题的学生:训练集就是它每天练习的题目。模型先根据样本做出预测,再根据预测和目标之间的差距调整参数。一次又一次之后,它才逐渐形成可用的判断能力。
训练集怎样让模型学会规律
训练过程并不是把数据倒进模型后立刻得到能力。更接近下面这个循环:
取出一批训练样本,例如一组图片或一段文本。 模型根据当前参数做出预测。 把预测结果和目标答案进行比较,计算差距。 根据差距调整参数,让下一次预测更接近目标。
这里的“差距”通常由损失函数衡量,而“怎么调整参数”则由算法决定。前面讲过的模型、参数、算法,在训练集这里终于合在一起:训练集提供练习材料,算法提供更新方法,参数记录学到的规律。
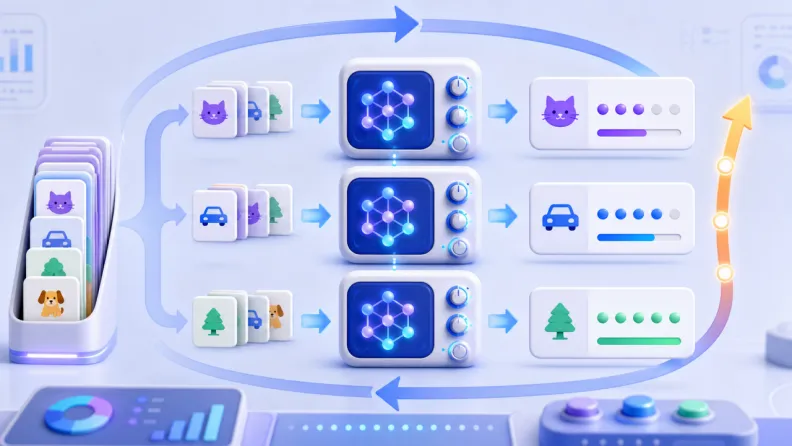
为什么不能把所有数据都拿来训练
如果所有数据都拿给模型练习,短期看似“物尽其用”,但会带来一个大问题:我们很难判断模型有没有真正学会。
这就像学生只做过一套题,考试时又考同一套题。分数高,不一定说明理解了知识点,也可能只是记住了题目。
因此,一个常见做法是把数据分成不同用途:
训练集:用于学习和更新参数。 验证集:用于训练过程中观察效果、帮助选择模型和调参数。 测试集:用于最后评估模型面对未见数据时的表现。
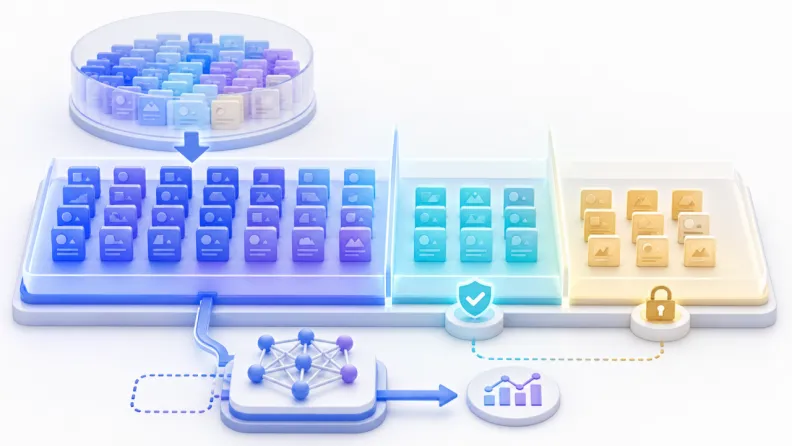
好的训练集应该长什么样
训练集会深刻影响模型最终学到什么。质量好的训练集,往往比单纯堆更多数据更重要。
检查维度 | 要问的问题 | 忽视后的影响 |
覆盖任务场景 | 训练集中有没有包含真实业务里会遇到的主要情况? | 模型容易只会处理少数熟悉样子,一换场景就失灵。 |
样本质量 | 数据是否清晰、去重、不过时,错误样本是否被清理? | 模型会把噪声也当成规律学进去。 |
标注一致性 | 同一类样本的答案或标签,是否按同一标准给出? | 模型会被互相矛盾的信号拉扯,学习效率下降。 |
分布平衡 | 关键类别、群体、场景是否明显偏少或偏多? | 模型可能对高频样本表现好,却忽视低频但重要的情况。 |
如果训练集里大多数样本来自同一种场景,模型就会更擅长这种场景;如果少数群体、少见情况或边界样本长期缺席,模型在这些地方就更容易出错。
训练集不是越大越好
更多训练数据通常有帮助,但前提是数据和任务相关、质量可靠、分布合理。重复的、错误的、过时的、来源不清的数据,可能只会让模型更坚定地学到错误模式。
所以真实项目里,训练集建设往往不是“多收一点”这么简单,而是一个持续清洗、筛选、标注、抽样和评估的过程。
常见误区
误区一:训练集就是全部数据。实际上,它只是用于训练的那部分数据。 误区二:训练集越大,模型一定越聪明。数据质量、覆盖范围和任务匹配度同样关键。 误区三:模型训练后表现好,就说明训练集没问题。也可能是验证和测试方式太宽松。 误区四:训练集只是工程细节。它往往决定模型能力边界,也决定风险会在哪里出现。
今天的小结
训练集是模型训练阶段直接使用的数据子集。 模型通过训练集不断预测、比较差距、调整参数。 训练集应与验证集、测试集区分开,避免把“练习题”当成“考试题”。 训练集质量会影响模型学到的规律,也会影响模型的偏差和边界。
为什么下一篇讲“监督学习”
现在我们知道:训练集负责给模型提供练习材料,让模型在反复尝试和纠错中调整参数。
但训练集有一个非常重要的区别:有些训练样本只有输入,有些训练样本还带有明确答案。
比如,一张图片旁边写着“猫”,一封邮件旁边标着“垃圾邮件”,一条用户记录旁边标着“是否会流失”。当模型用这种“输入 + 正确答案”的样本来学习时,它就像有人在旁边告诉它:这道题应该怎么答。
这种带着答案学习的方式,就是监督学习(Supervised Learning)。
下一篇我们会讲:监督学习为什么是最常见的机器学习方式之一,它适合解决哪些问题,又为什么“标签质量”会直接影响模型能力。

系列提示:如果你能分清“数据集、训练集、监督学习”这三个词,就已经抓住了许多 AI 项目的底层逻辑:先有什么数据,再决定用哪部分练习,最后决定用什么学习方式。
