 夜雨聆风
夜雨聆风
我们应该构建这样的AI辅助系统:扩展意识而非缩窄视野,邀请反思而非诱导接受,帮助用户看到模式而不隐藏细微差别,鼓励判断而非替代判断 ……
协助阅读文章,梳理评论,汇总内容,提炼要点,生成摘要,无疑是当今AI工具被最常使用的场景之一。AI俨然成了一名诠释者和认知的塑造者,决定什么最重要、什么该被忽略、共识如何被框定。
但AI生成摘要从来不是中立的,背后是算法选择。我们不禁要追问:AI是在赋权用户做出明智判断,还是在诱导他们被动接受?
这正是Nima Kordzadeh在《Communications of the ACM》2026年6月刊发表的观点文章所探讨的核心议题。本文尝试沿着这篇文章的分析脉络,探讨AI助手的通用设计哲学。
一
AI摘要的“好、坏、丑”
Kordzadeh从用户、品牌、平台三方视角,系统分析了AI生成在线评论摘要的利弊:
| 利益相关者 | 好 (The Good) | 坏 (The Bad) | 丑 (The Ugly) |
|---|---|---|---|
| 用户 | 节省时间,降低认知负荷,呈现反复出现的主题,支持明智决策 | 过度简化或聚焦多数意见会过滤细微差别,可能与个人需求不符;锚定效应等认知偏见会缩窄解读空间,导致过度依赖 | 扭曲或正面偏向的摘要误导用户,削弱决策信心,模糊"被告知"与"被影响"的界限 |
| 品牌 | 突出一致优势(如质量、服务),放大声誉,提供快速反馈循环 | 不平衡的描绘夸大弱点或遗漏优点,歪曲声誉,限制公平竞争 | 持续的偏见或扭曲造成声誉损害,引发与平台的纠纷,引起公平性和透明度担忧 |
| 平台 | 提升可用性,减少信息杂乱,增强用户参与度;平衡透明的摘要可建立用户信任和忠诚度 | 肤浅或有偏见的摘要侵蚀用户信心,增加确保准确性、公平性和透明度的责任 | 被感知的偏袒或操纵损害可信度,招致公众反弹和监管审查,威胁合法性 |
这个分析框架揭示了一个关键洞察:效率收益可以迅速转变为扭曲和信任侵蚀。
二
从自动化到赋权
文章的核心立场可以概括为:
AI生成在线评论摘要的设计应从“自动化”转向“赋权”,通过透明度、多元性、用户控制和问责制增强用户能动性,使用户成为主动解释者,而非算法共识的沉默接收者。
这意味着评判AI摘要价值的标准不应仅是准确性或效率,而应是它们如何塑造人类能动性。问题不再是“自动化能否有效完成摘要”,而是“它是放大还是压制了用户批判性思考、比较替代方案、做出符合自身目标的选择的能力”。
自动化 vs. 赋权:范式对比
| 维度 | 自动化范式 | 赋权范式 |
|---|---|---|
| 目标 | 替代人类劳动,提高效率 | 增强人类能力,支持判断 |
| 用户角色 | 被动接收者 | 主动诠释者 |
| 信息呈现 | 单一"共识"结论 | 多元视角并存 |
| 透明度 | 黑箱操作 | 可追溯、可理解 |
| 控制权 | 算法决定 | 用户可调整 |
| 信任基础 | 权威性 | 开放性 |
| 价值衡量 | 速度、准确率 | 能动性、理解深度 |
三
赋权设计的四项原则
Kordzadeh提出了以赋权为核心的设计哲学,包含四项相互支撑的原则:
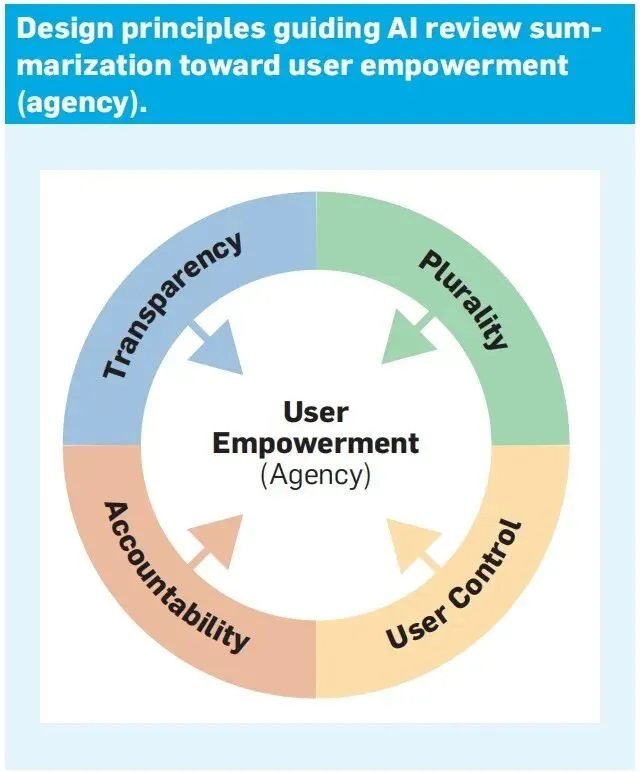
原则一:透明度(Transparency)
核心理念:将隐藏的逻辑转化为可见的过程。
透明度是能动性的基础。当用户理解摘要是如何构建的——它从什么数据中提取、什么规则指导纳入、存在什么局限——他们就能批判性地诠释,而非盲目接受。
实践方法:
基础披露:说明数据来源、数量、时间范围
例:"此摘要基于1,250条已验证评论生成,使用AI识别清洁度、服务和价值方面的反复主题"
交互式透明:提供"追溯此洞察"链接,显示支持性原始评论
置信度指示:为每个洞察提供置信度分数
局限性说明:明确摘要能说什么、不能说什么
认知效应:解释和可追溯性培养校准的信任,减少自动化偏见。透明度将平台从"沉默的仲裁者"转变为"推理的伙伴"。
原则二:多元性(Plurality)
核心理念:用多元视角替代单一叙事。
单一的"共识"摘要虽然方便,但会压平合理的分歧,掩盖偏好、体验或优先级的多样性。家庭、独行旅客和商务客人可能重视同一酒店的不同方面。
实践方法:
并列呈现:最受赞扬和最受批评的方面并排展示
分群洞察:为不同用户群体提供细分见解
情感分布可视化:展示各主题的情感分布,而非简单平均
争议标识:标注存在显著分歧的话题
认知效应:接触多元视角有助于对抗锚定效应和确认偏见。多元性将AI从"最终裁判"重新定位为"对话发起者"——一个框定选项而非决定选项的工具。
原则三:用户控制(User Control)
核心理念:将摘要转化为交互式工具。
当用户能够塑造他们所看到的内容时,能动性就会增强。静态摘要往往暗示单一解读,而交互式设计允许个人根据自己的需求探索信息。
实践方法:
时间窗口调整:滑块调整时间范围(如"最近六个月")
群体筛选:聚焦特定评论者群体(如"仅限家庭")
主题权重:切换强调某些方面(如清洁度vs.位置)
可逆选择:所有调整都可轻松撤销
设计平衡:有效的用户控制需要平衡简洁与灵活。太多选项会让人不知所措,但几个直观的选项——清晰的筛选器、可见的理由、可逆的选择——可以在不增加摩擦的情况下强化自主性。
认知效应:当人们能追踪每次调整如何改变重点时,他们会更加意识到权衡和潜在偏见,减少对默认视图的过度依赖,培养对决策过程的主人翁意识。
原则四:问责制(Accountability)
核心理念:将监督嵌入系统。
透明度、多元性和用户控制只有与真正的问责制配对才有效。没有监控和纠正扭曲的机制,即使设计良好的摘要也可能滑向偏见、遗漏或操纵。
实践方法:
定期审计:评估跨产品、语言和用户群体的摘要平衡性和准确性
公开报告:公布评估结果,即使是简要形式
反馈渠道:为用户和企业提供便捷渠道,质疑误导性摘要或突出被忽视的视角
响应性纠正:及时处理反馈,将问责从静态合规转变为与利益相关者的活跃对话
独立监督:在高影响领域,外部审查者或行业联盟可建立代表性和偏见缓解的共享基准
信任效应:将问责制嵌入设计和治理,将AI摘要转变为集体声音的可信中介。
四
AI助手的通用设计哲学
Kordzadeh的分析虽然聚焦于在线评论摘要,但其核心洞察可以拓展为AI助手的通用设计哲学。无论是搜索引擎、写作助手、代码生成器还是决策支持系统,所有AI助手都面临同样的根本问题:技术应该替代人类判断,还是增强人类判断?
AI助手的通用设计框架对比
| 设计维度 | 自动化导向 | 赋权导向 |
|---|---|---|
| 信息呈现 | 给出"最佳答案" | 呈现选项空间和权衡 |
| 推理过程 | 隐藏在黑箱中 | 可追溯、可解释 |
| 用户交互 | 被动接收输出 | 主动探索和调整 |
| 不确定性 | 隐藏或忽略 | 明确表达和量化 |
| 错误处理 | 系统自动纠正 | 用户参与识别和纠正 |
| 学习方向 | 系统学习用户偏好 | 用户通过系统学习领域知识 |
| 长期效应 | 用户技能退化 | 用户能力提升 |
赋权设计的核心问题清单
在设计任何AI助手时,可以用以下问题检验是否符合赋权原则:
透明度检验:
用户能否理解AI是如何得出这个结果的?
数据来源、处理逻辑、局限性是否清晰可见?
用户能否追溯到支持结论的原始证据?
多元性检验:
是否呈现了多种可能的解读或方案?
少数意见或边缘情况是否被适当表达?
用户能否看到不同视角之间的张力和权衡?
用户控制检验:
用户能否根据自己的需求调整AI的行为?
交互是否支持探索而非仅仅接收?
用户能否轻松撤销或修改AI的建议?
问责制检验:
是否有机制监控和纠正系统性偏差?
用户能否反馈问题并看到响应?
系统的表现是否接受定期评估和公开报告?
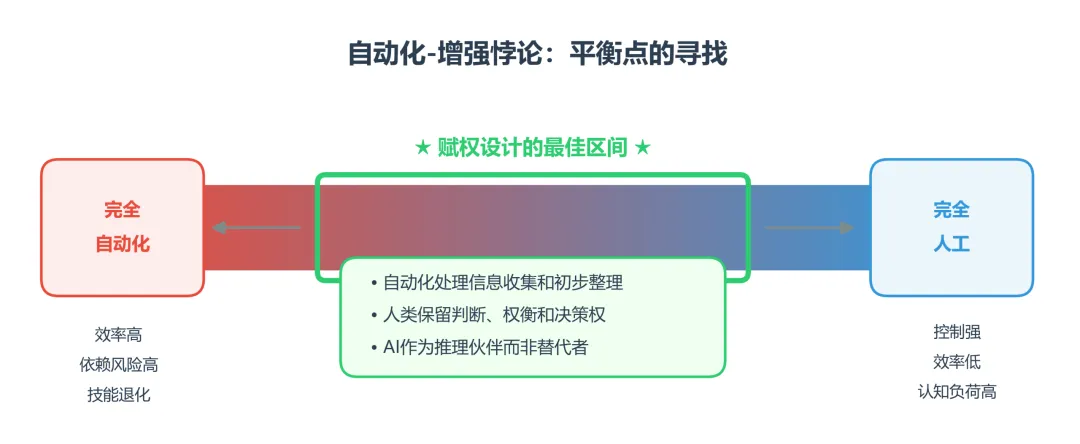
赋权设计的平衡点:打破“自动化-增强”悖论
在技术变革进程中,存在着一个所谓的“自动化-增强”悖论(Automation-Augmentation Paradox):当技术被引入工作场所时,它本应同时具备两种潜力——自动化(提高效率)和增强(创造新价值),但在实践中,组织和个人往往倾向于优先采用自动化路径,而忽视或抑制了增强。
这个悖论揭示了一个深刻的张力:
自动化的诱惑:完全自动化看似效率最高,但可能导致用户技能退化、过度依赖、批判性思维萎缩
增强的挑战:增强人类能力需要更复杂的设计,但能培养用户的判断力和自主性
最佳的AI系统设计需要在这两极之间找到平衡点:利用自动化处理繁琐的信息处理,同时保留人类在判断、价值权衡和最终决策中的核心角色。
五
结语:AI作为推理的伙伴
当下的“AI助手”正站在便利与控制的十字路口。它们承诺清晰,却携带扭曲的风险;提供速度,却可能以微妙的方式塑造理解,影响着人类的能动性。
我们当下的任务是构建这样的系统:
扩展意识而非缩窄视野
邀请反思而非诱导接受
帮助用户看到模式而不隐藏细微差别
鼓励判断而非替代判断
最终,进步的真正衡量标准在于AI如何深化人类理解并支持深思熟虑的判断。建立在尊重人类能动性基础上的工具可以扩展理解,赋予集体判断的全部丰富性以声音。这样的设计选择使AI更接近负责任和可问责的实践。
Kordzadeh, N. (2026). Empowerment over Automation in AI Summarization of Online Reviews. Communications of the ACM, 69(6), 39-42.
https://doi.org/10.1145/3773101
Jiang, W. et al. (2021). Review summary generation in online systems: Frameworks for supervised and unsupervised scenarios. ACM Transactions on the Web (TWEB), 15(3).
https://dl.acm.org/doi/abs/10.1145/3448015
Passi, S. & Vorvoreanu, M. (2022). Overreliance on AI: Literature review. Microsoft Research, 339.
https://www.microsoft.com/en-us/research/wp-content/uploads/2022/06/Aether-Overreliance-on-AI-Review-Final-6.21.22.pdf
Raisch, S. & Krakowski, S. (2021). Artificial intelligence and management: The automation–augmentation paradox. Academy of Management Review, 46(1).
https://journals.aom.org/doi/10.5465/amr.2018.0072
Rastogi, C. et al. (2022). Deciding fast and slow: The role of cognitive biases in AI-assisted decision-making. Proceedings of the ACM on Human-computer Interaction (CSCW1).
https://dl.acm.org/doi/abs/10.1145/3512930
Romeo, G. & Conti, D. (2025). Exploring automation bias in human–AI collaboration: A review and implications for explainable AI. AI and Society.
https://link.springer.com/article/10.1007/s00146-025-02422-7
Tendulkar, P.K. & Kordzadeh, N. (2025). Application of generative AI in summarizing online reviews: A prompt engineering approach. Proceedings of the Americas Conference on Information Systems (AMCIS).
https://aisel.aisnet.org/amcis2025/data_science/sig_dsa/8/
